
Version : 1.0.0 24th April 2023
In this Hands On Lab you will create a model to predict customer churn and present model-driven insights to your stakeholders. You will use an interpretability technique to make your otherwise “black box model” explainable in an interactive dashboard. A mathematical explanation is beyond the scope of this lab but if you are interested in learning more we recommend the Fast Forward Labs Report on Model Interpretability. Finally, you will use basic ML Ops techniques to productionize and monitor your model.
-
Single ML Workspace as the primary working environment
-
Important! ML Workspace contains both Model Metrics and Governance features turned on (they are off by default).
-
Use this document for all preparation

Lab 1: Configure and deploy the Workshop Content as an AMP (15 min)
AMPs (Applied Machine Learning Prototypes) are reference Machine Learning projects that have been built by Cloudera Fast Forward Labs to provide quickstart examples and tutorials. AMPs are deployed into the Cloudera Machine Learning (CML) experience, which is a platform you can also build your own Machine Learning use cases on.
-
Go to the Workshop Environment (provided by instructor)
-
Need to have Workload password set (this will be needed for CDV part where CDW is queried)
-
For directions to set Workload password click here Reset Workload Password
-
-
Navigate to the Machine Learning tile from the CDP Menu
-
Make sure you can click into the Workspace by clicking the Workspace name (provided by instructor)

A Workspace is a cluster that runs on a kubernetes service to provide teams of data scientists a platform to develop, test, train, and ultimately deploy machine learning models. It is designed to deploy a small number of infra resources and then autoscale compute resources as needed when end users implement more workloads and use cases.
-
Click on User Settings
-
Go to Environment Variables tab and set your WORKLOAD_PASSWORD (provided by instructor).

In a workspace, Projects view is the default and you’ll be presented with all public (within your organization) and your own projects, if any. In this lab we will be creating a project based on Applied ML Prototype.
-
Click on AMPs in the side panel and search for “workshop”
-
If you don’t see a Cloudera Machine Learning Workshop AMP, click on Projects on the left-side panel, and follow the next 5 steps:
1. Click on the `New Project` button on the right side of the screen 2. Name you project something creative 3. Under Initial Setup, click the `AMPs` tab. 4. Provide teh Git URL: `https://github.com/ogakulov/CML_AMP_Churn_Prediction_mlflow` 5. Click the `Create Project` button

-
Click on the AMP card and then on Configure Project

IMPORTANT
-
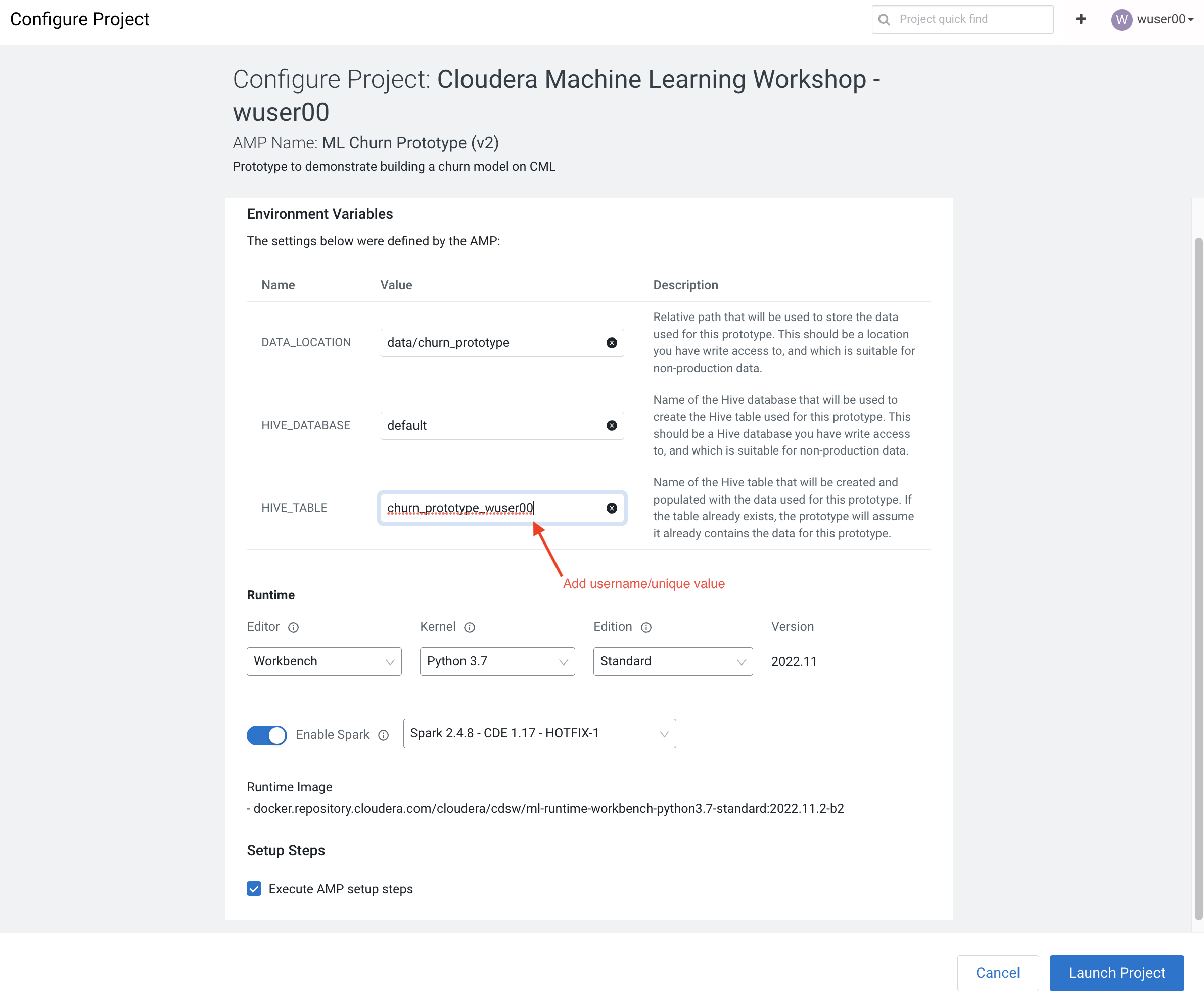
In the Configure Project screen, change the HIVE_TABLE to have a unique suffix. Leave the other environment variables as is.
-
DATA_LOCATION:
data/churn_prototype -
HIVE_DATABASE:
<unique username/value>For example, cdpuser50 -
HIVE_TABLE:
churn_prototype
-
-
Click Launch Project

NOTE: If you see a Warning about runtime mismatch, select the latest available runtime from the dropdown menu.
The latest version of the AMP has been tested for CML Runtimes with Python 3.7 and Spark 2.4.7. If the workspace does not have the exact runtime that was tested you may get a warning. However, you can still deploy the project with other runtimes. For example, you can deploy the project with Spark 2.4.7, CDP 7.2.11, CDE 1.13 HotFix 2.
-
Click on Overview on the side panel. On the Project Overview page you will find a listing of Files, as well as a rendering of the README.md

Collaborators:
-
Click on Collaborators in the side panel
This feature allows teams of Data Scientists, Analysts, and Data Engineers to work together on a given project.
-
Ask a colleague for their user ID or use wuser00 and add them as a collaborator with a Viewer role on your project by clicking Add
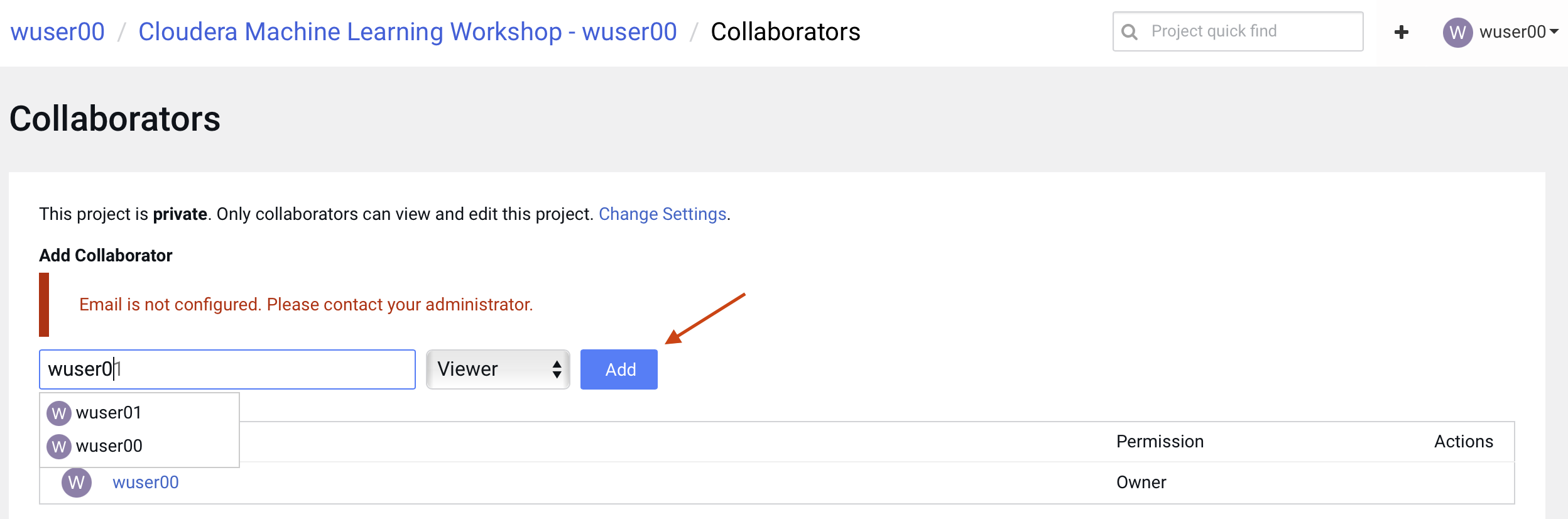
You can give access to other users with certain permissions for the encompassing project so teams of users can collaborate together. CML users can also be organized into Teams for ease of management. Consult CML documentation to learn about available roles and their permissions.

Project Settings:
-
Click on Project Settings in the side panel
Taking a look at Project Settings, this is where you can define several options for the current project. You have the ability to define different engines where your code in CML will run. There are project variables that can be defined and used throughout your code. SSH tunnels can also be configured to connect to other services as needed. More details can be found in our docs.
-
Change the name of your project to something creative
Please do not change the other Project Settings
This view is also where the project can be deleted, if needed.

-
Click on Data in the side panel
-
Click on Launch Data Application
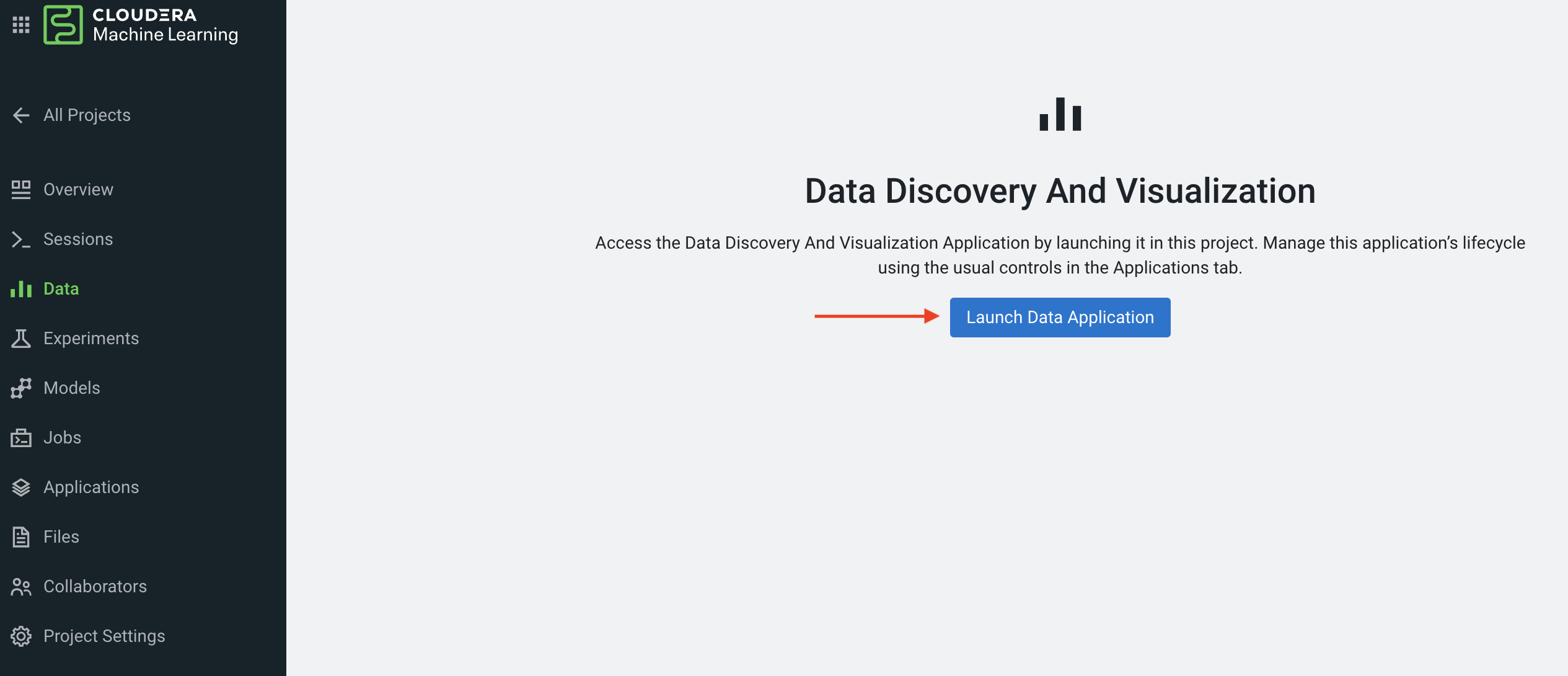
Cloudera Data Visualization (CDV) deployed in CML will take approximately 2 minutes to spin up. It’s a powerful addition to the workflow, as it allows quick access to a SQL interface and visual data exploration without writing any Python code. The data connection points to the central Data Lake which stores all of the enterprise data, giving CML user ability to discover datasets, combine and filter them to uncover new insight.
CDV is deployed as an Application inside of CML. While this application is starting, you can check on its status by clicking on Applications in the side panel. When you see status Running you can return to the Data page in the side panel. This is what you should see now:
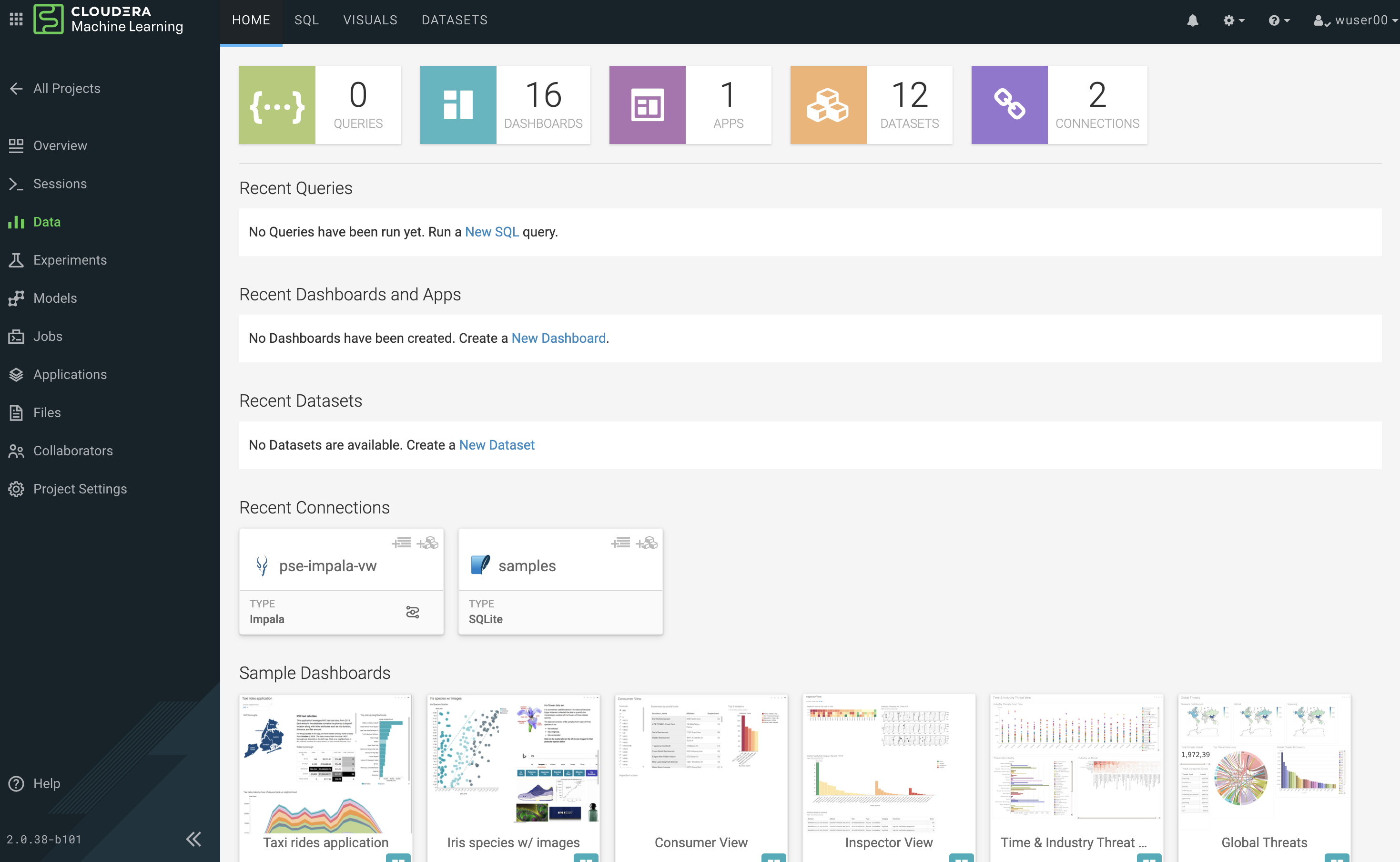
From here you can navigate to SQL editor, start building visualizations, or create new datasets.
-
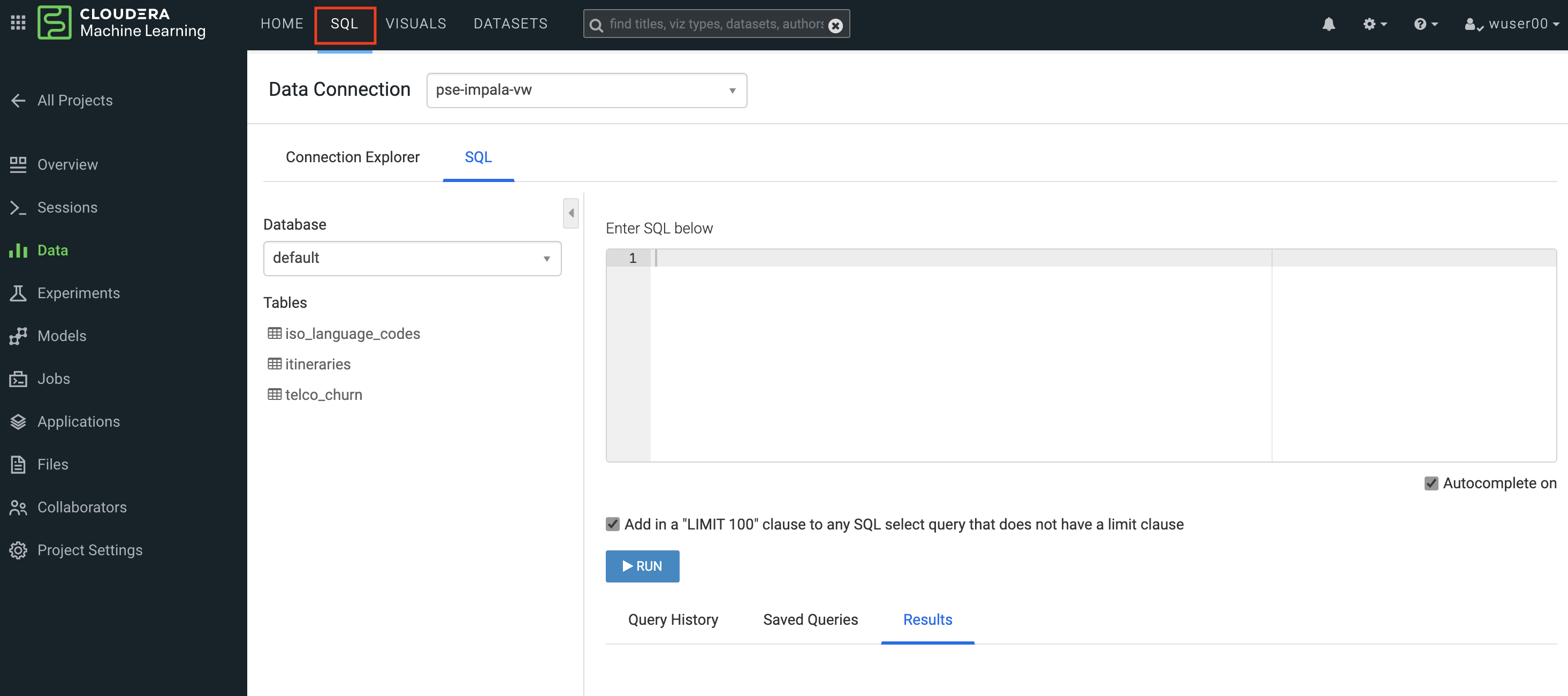
Click on SQL tab in the top menu
 Note
NoteIf you see below error check to make sure your Workload Password is set in CML (see Part 1, p.5). You may need to restart your app to fix this. 
-
In Data Connection drop down select pse-impala-vw (instructor may provide a different connection)
-
Inn the SQL editor enter the query below, the click RUN or ⌘+Enter
SELECT COUNT(DISTINCT internetservice) as 'internetservice', COUNT(DISTINCT multiplelines) as 'multiplelines', COUNT(DISTINCT contract) as 'contract', COUNT(DISTINCT paymentmethod) as 'paymentmethod' FROM default.churn_prototype;
The result produced tells us that each categorical variable in this dataset has just a handful of unique values. Any number of table stats analysis can be carried out, including table joins, filtering, etc. For example, below we will limit what data is pulled in to build a dashboard.
-
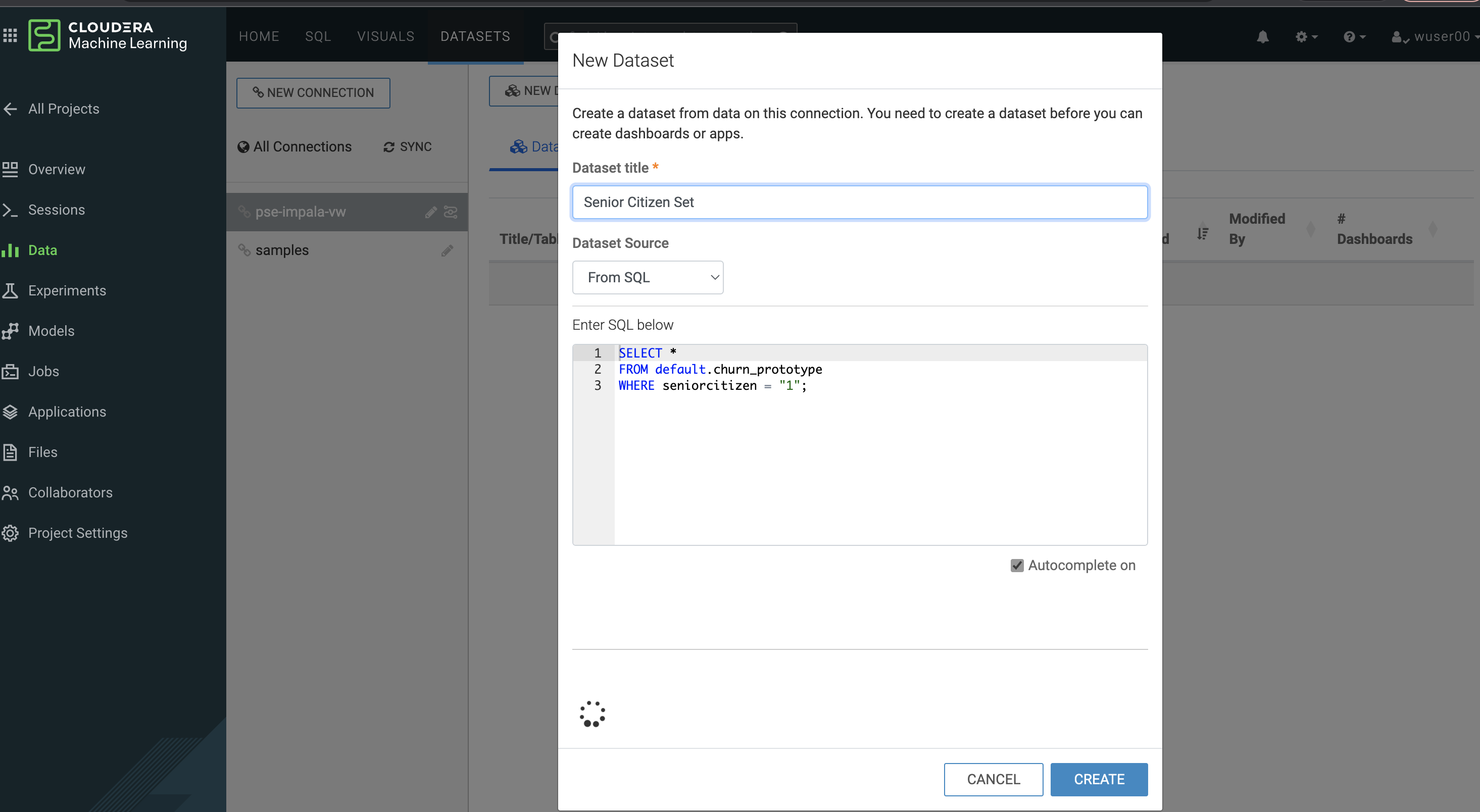
In the SQL editor replace the previous query with the query below
SELECT * FROM default.churn_prototype WHERE seniorcitizen = "1";
-
Click SAVE AS DATASET button. This will take you to the DATASETS tab in the top menu.
-
Give the Dataset a name and click CREATE
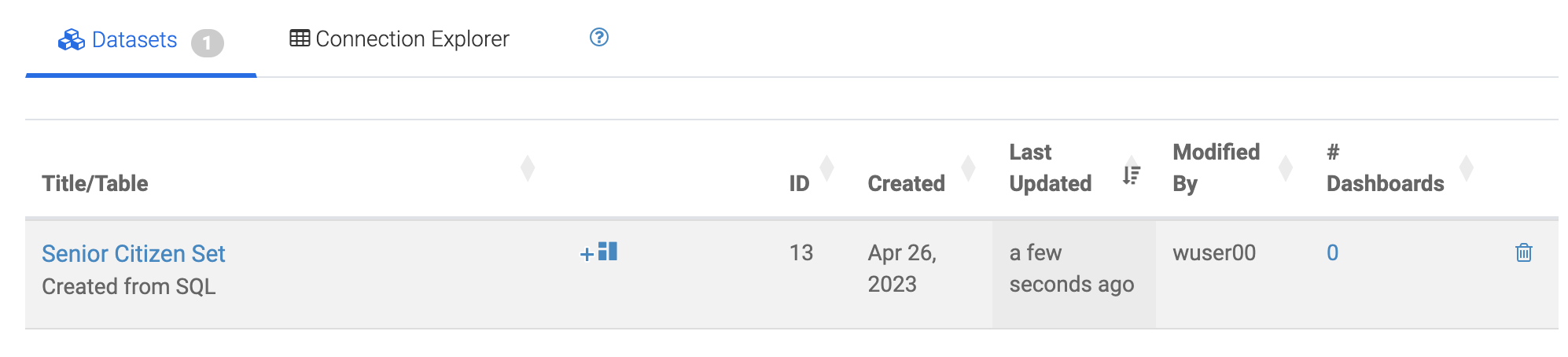
In the context of Cloudera Data Visualization, creating a Dataset is defining metadata on top of existing Hive or Iceberg table. The logical Dataset object can then be easily used to build visuals and dashboards fit for decision making or data exploration.
-
Click on your Dataset to view the metadata information.
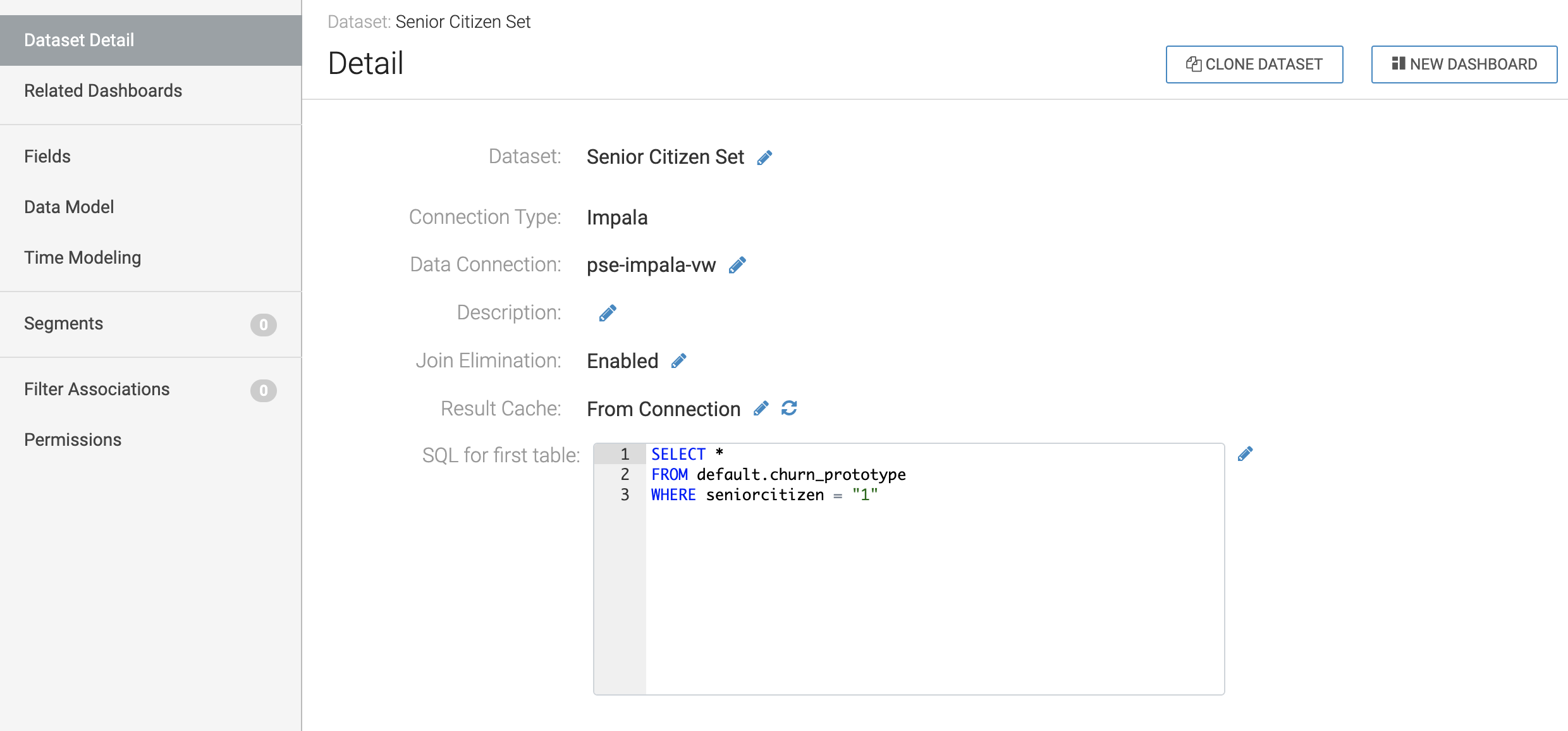
-
Click on Fields menu item in the left-hand panel
-
Click on the EDIT FIELDS button
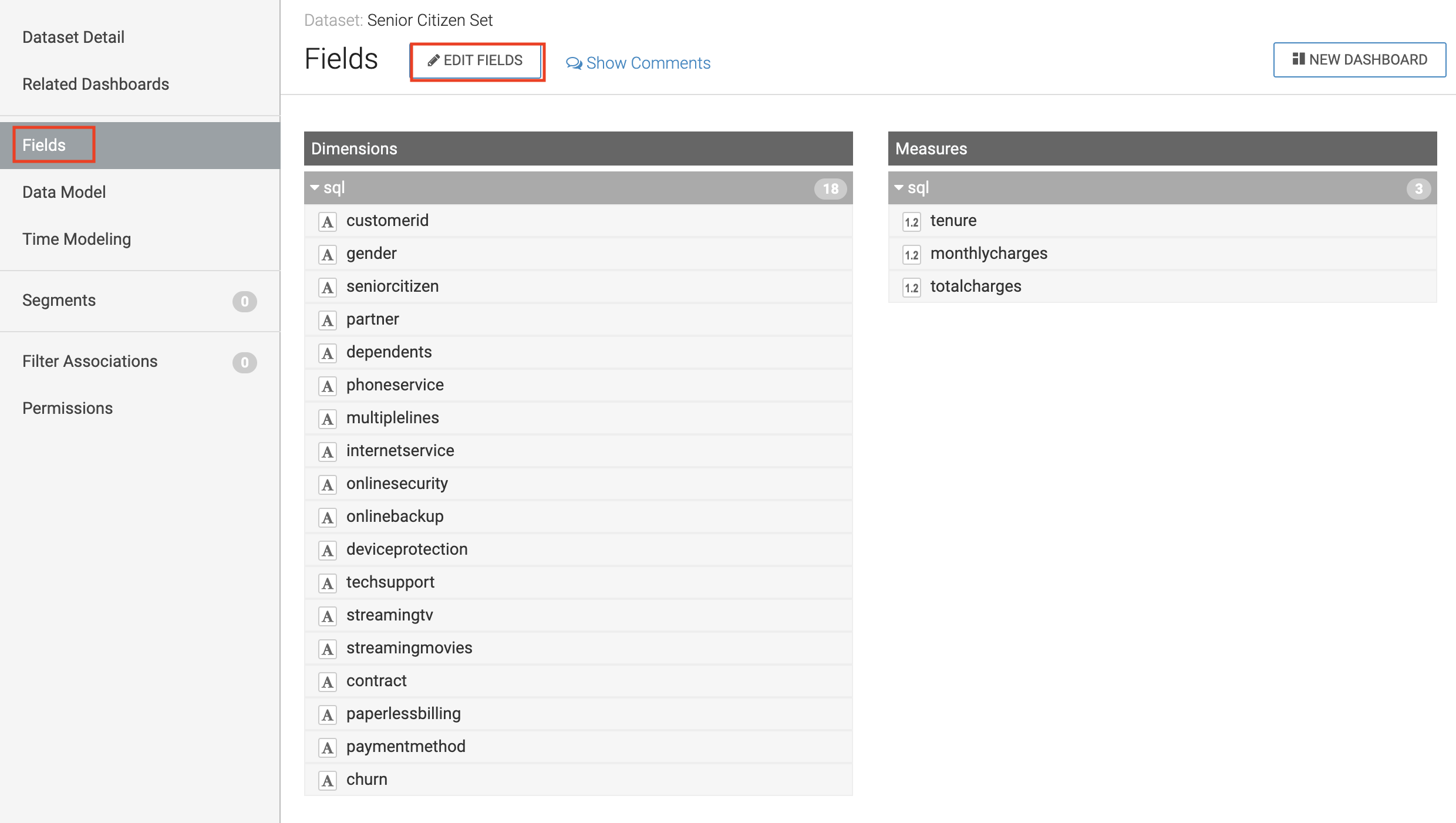
-
Click the down arrow at the end of the churn Field, and select Clone

-
Find the Copy of churn Field at the bottom of the Dimensions list and change its type to Mes(ure) and its type from (string) to (integer).
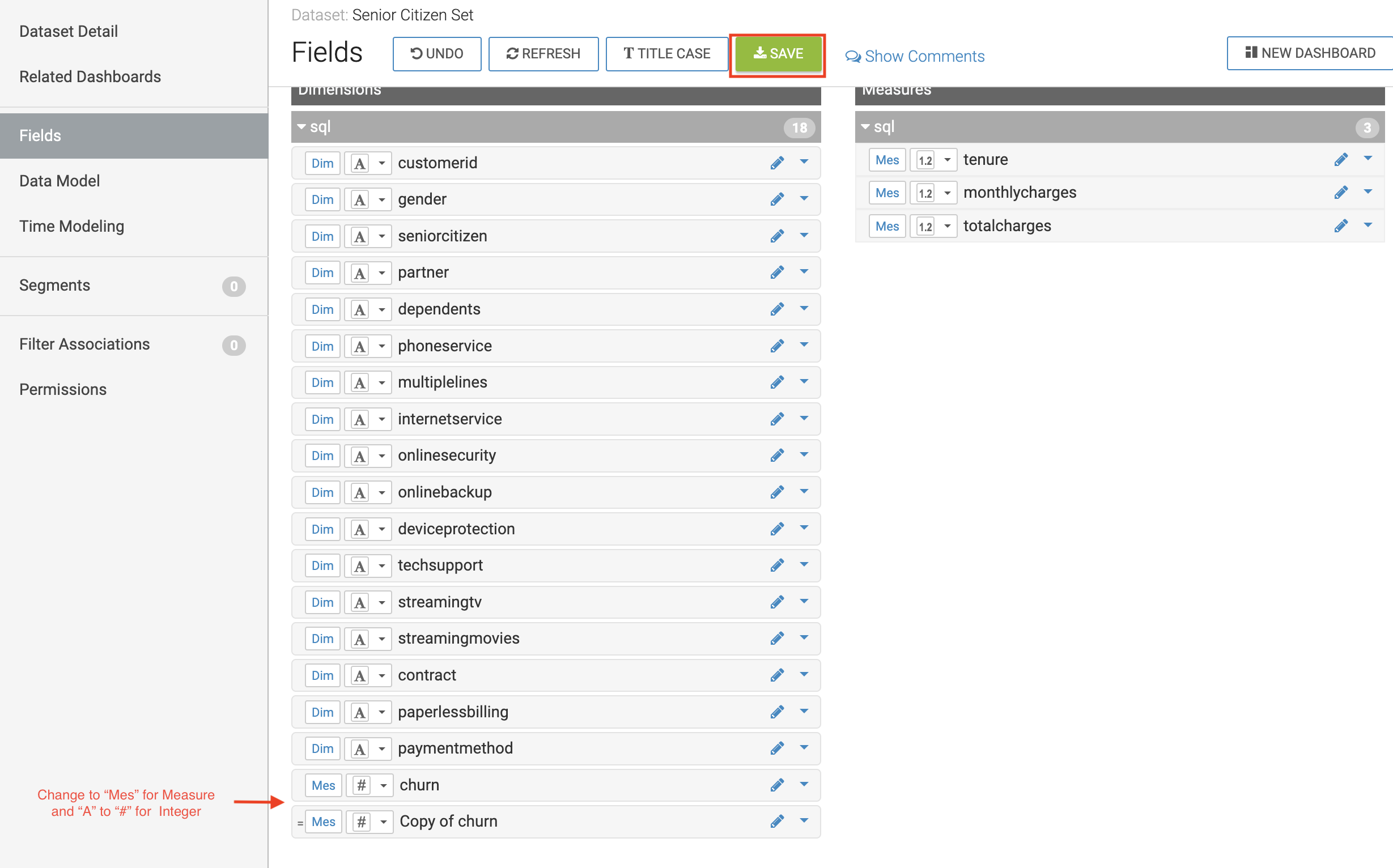
-
Click the SAVE button
There is much more that can be done with a Dataset, but we will leave it here. Now your Dataset is ready to be used in a Dashboard.
-
Click on the Visual tab in the top menu
-
Click on the NEW DASHBOARD button located on the top right
You are now presented with a Dashboard building interface.
-
Click on Visuals menu item in the right-hand panel, the connection is the same one you used to run your SQL against, and the Dataset you just created.
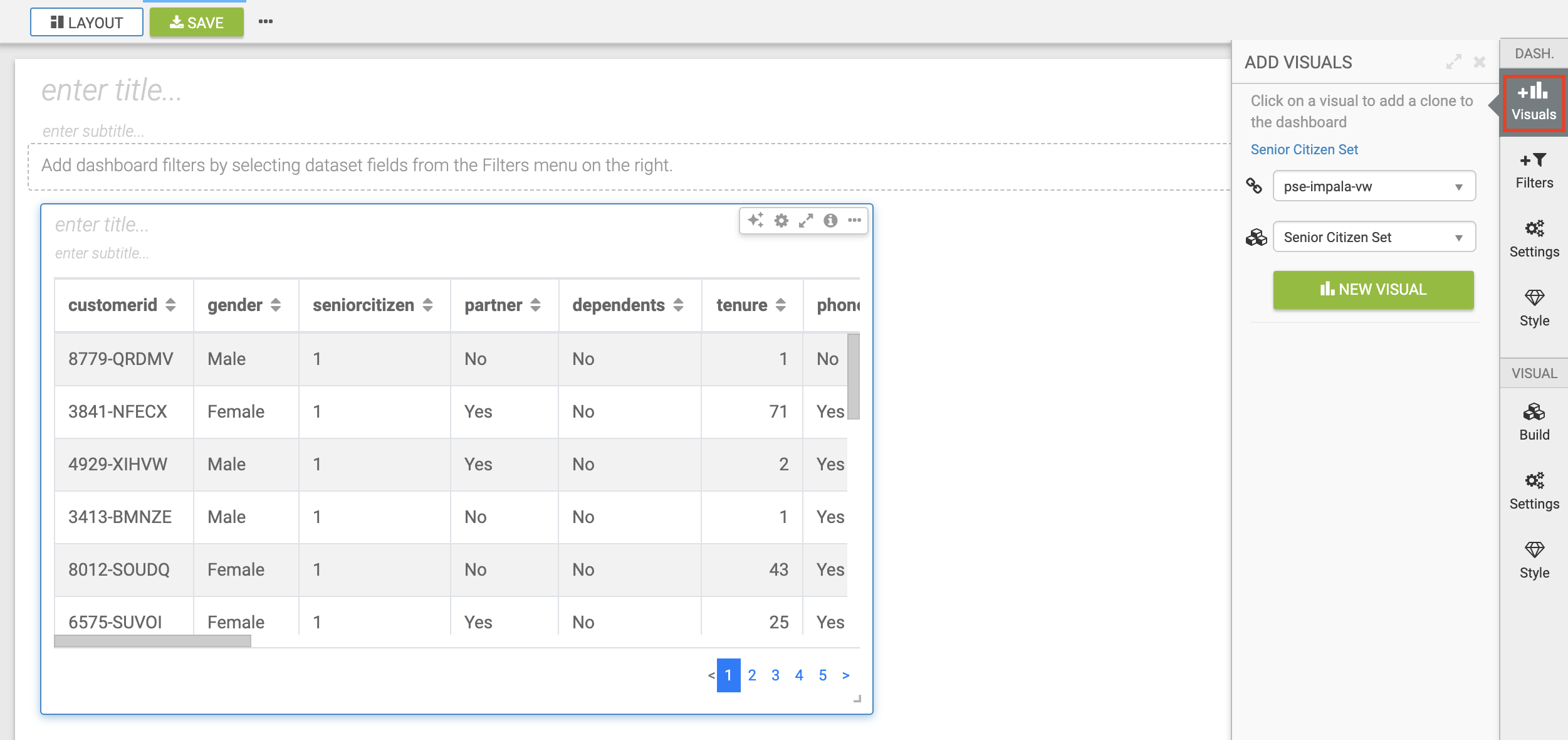
-
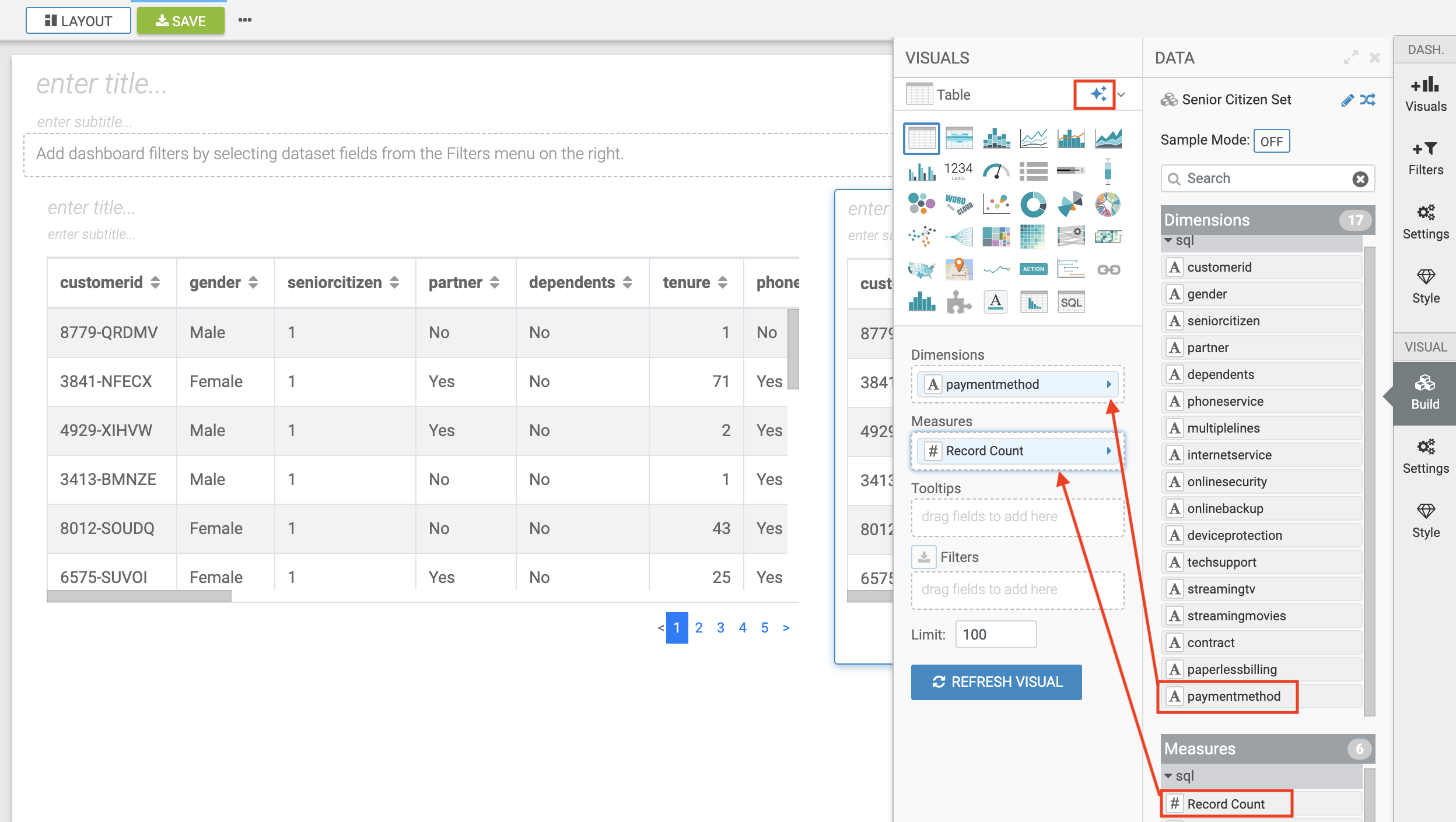
In the right-hand panel click on the NEW VISUAL button.
By default, CDV will use a table as the starter format. Of course the idea is to use visualization techniques to develop some insight around the dataset, to explore the underlying data, or to develop a user-friendly dashboard for broader consumption.
-
Drag the paymentmethod card to the Dimensions shelf and Record Count to Measures shelf
-
Click on the Explore Visuals icon to explore visualization options
-
Slect Horizontal bars by clicking on the that card
Congratulations you just built your first visual in CDV! Now add a couple of more interesting visuals and save your dashboard to conclude this part of the workshop.
-
Click on the Visual menu item on the right-hand panel and the click on NEW VISUAL to add a new visual
-
Repeat steps above in this section to build a visual based on other variables and styles
-
Give your dashboard a title and a subtitle
-
Click the SAVE button












Performant SQL interface and visual data exploration are two powerful tools in the arsenal of a Data Professional. One helps to wrangle the data available in the enterprise Data Lakehouse, the other makes it easier to identify patterns and to communicate information to a wider audience.
Sessions allow you to perform actions such as run R, Scala or Python code. They also provide access to an interactive command prompt and terminal. Sessions will be built on a specified Runtime Image, which is a docker container that is deployed onto the ML Workspace. In addition you can specify how much compute you want the session to use.
-
Click on the Overview menu item in the side panel
-
Click on the New Session button in the top right corner
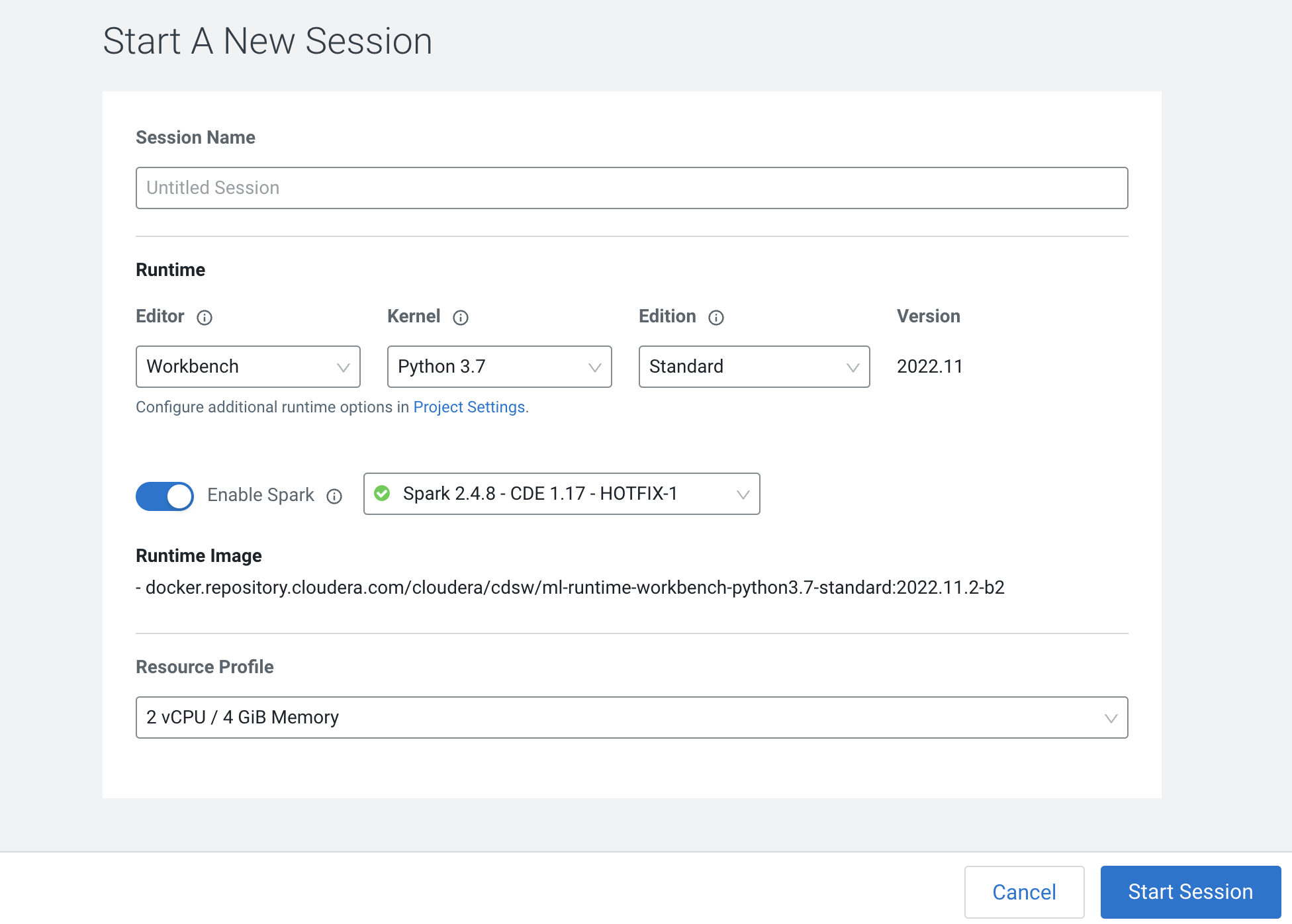
Before you start a new session you can give it a name, choose an editor (e.g. JupyterLab), what kernel you’d like to use (e.g. latest Python or R), whether you want to make Spark (and hdfs) libraries be available in your session, and finally the resource profile (CPU, memory, and GPU).
-
Ensure that Enable Spark add on is enabled
-
Leave all other default settings as is and click the Start Session button
The Workbench is now starting up and deploying a container onto the workspace at this point. Going from left to right you will see the project files, editor pane, and session pane.
Once you see the flashing red line on the bottom of the session pane turn steady green the container has been successfully started.
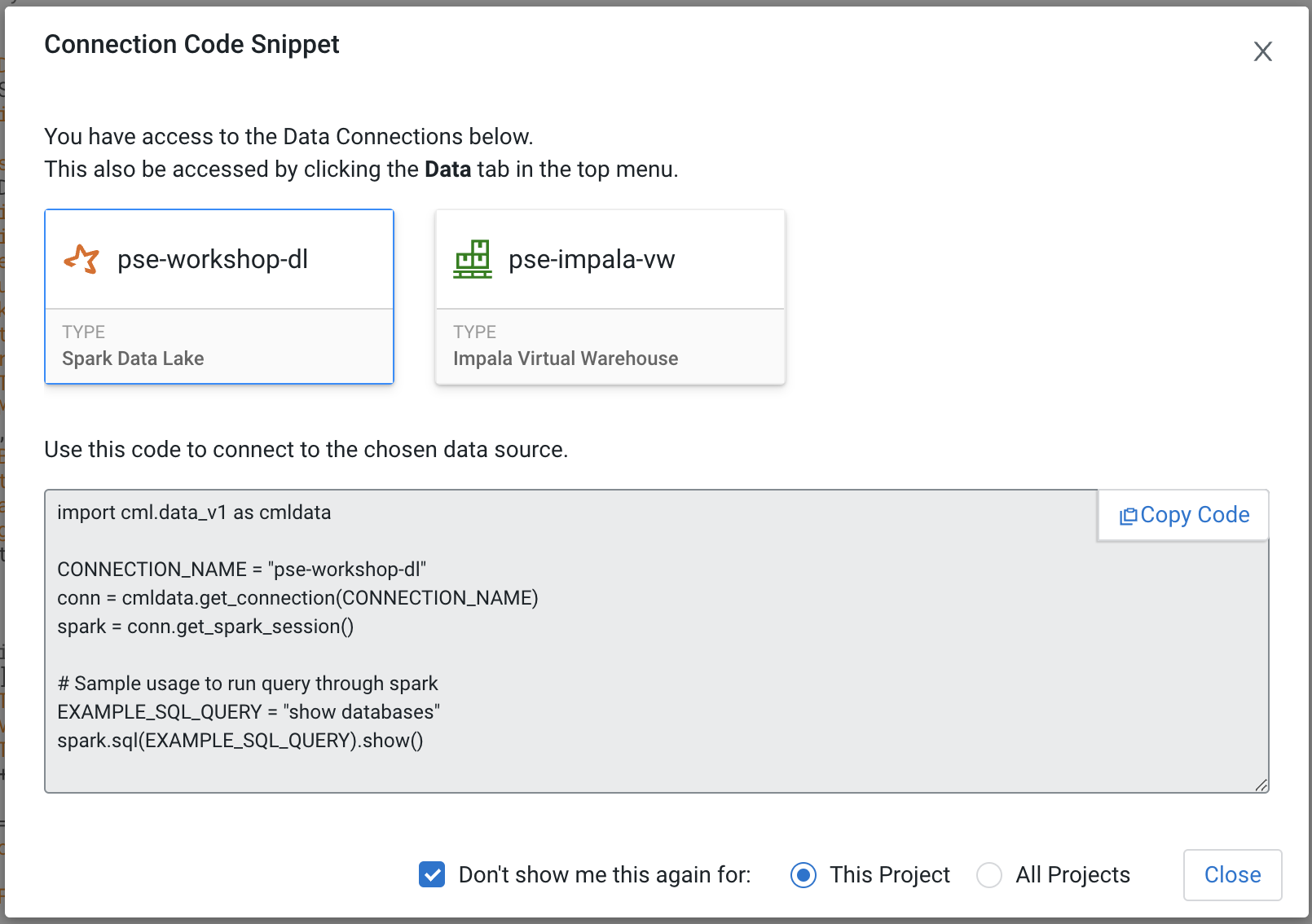
You will be greeted with a pop-up window to get you started connecting to pre-populated Data Lake sources (e.g. virtual Data Warehouses). You could simply copy the code snippet provided and easily connect to, say, a Hive vDW. However, in this lab we won’t be using this feature.
-
Check the box Don’t show me this again and click the Close button


-
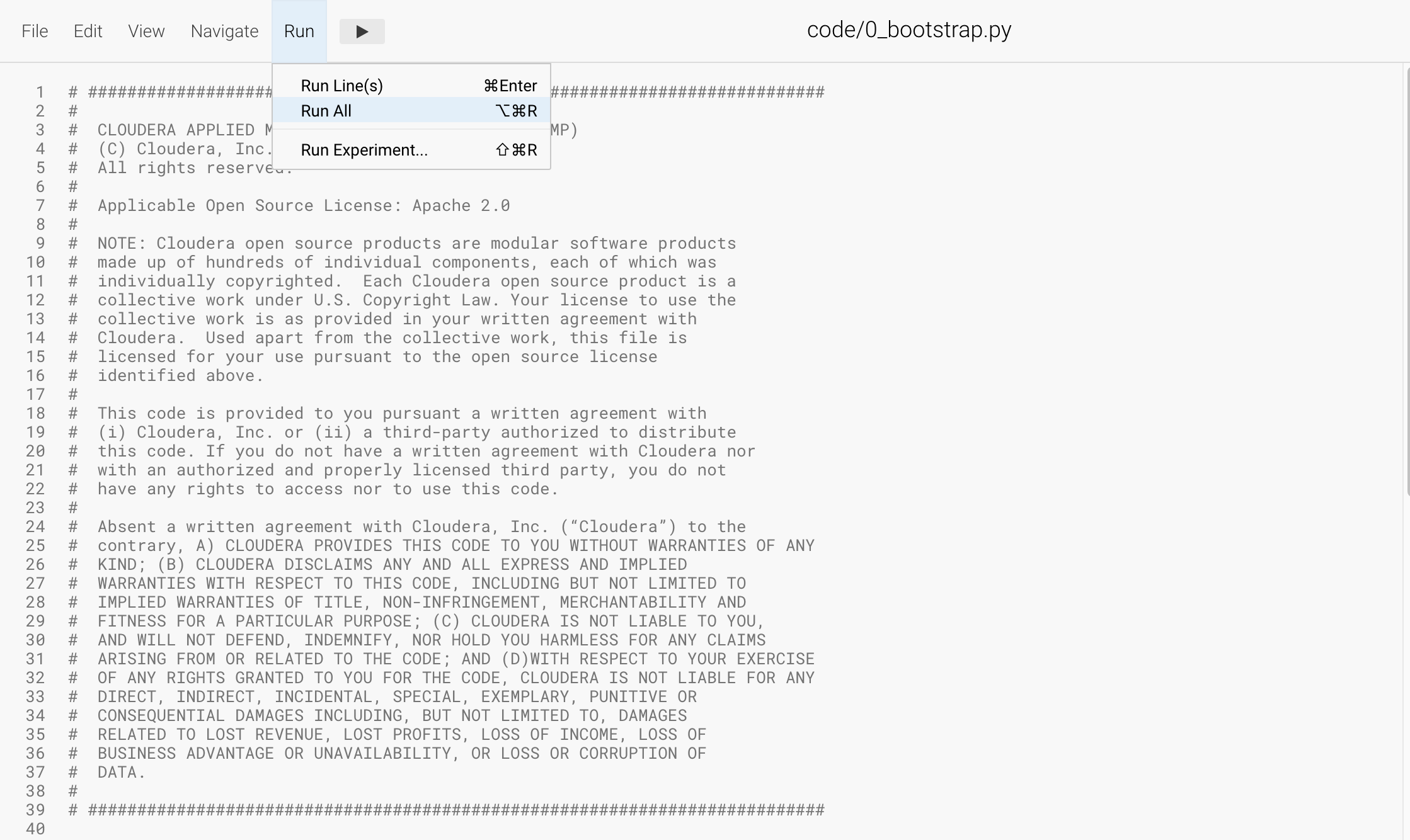
Navigate to code/0_bootstrap.py
You need to run this at the start of the project. It will install the requirements, create the STORAGE and STORAGE_MODE environment variables and copy the data from WA_Fn-UseC_-Telco-Customer-Churn-.csv into specified path of the STORAGE location, if applicable.
-
Important! Run All lines in this script

-
Navigate to code/1_data_ingest.py
In this script you will ingest a raw csv file into a Spark Dataframe. The script has a .py extension and therefore is ideally suited for execution with the Workbench editor. No modifications to the code are required and it can be executed as is.
-
You can execute the entire script in bulk by clicking on the “play icon” on the top menu bar. Once you do this you should notice the editor bar switches from green to red.
-
As an alternative you can select subsets of the code and execute those only. This is great for troubleshooting and testing. To do so, highlight a number of lines of code from your script and then click on “Run” → “Run Lines” from the top menu bar.
-
-
Important! Run All lines in this script
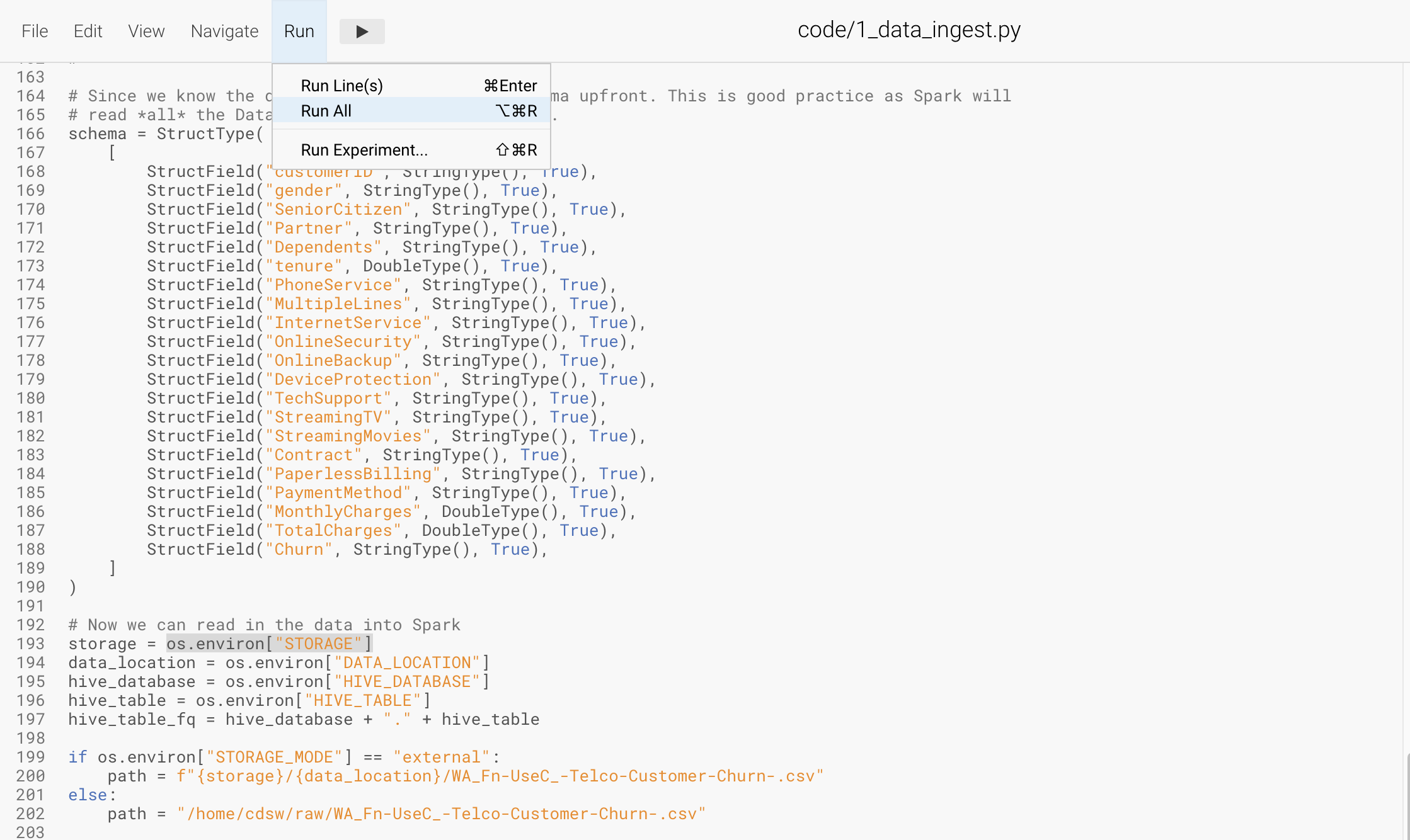
The code is explained in the script comments. However, here are a key few highlights:
-
Because CML is integrated with SDX and CDP, you can easily retrieve large datasets from Cloud Storage (ADLS, S3, Ozone) with a simple line of code
-
Apache Spark is a general purpose framework for distributed computing that offers high performance for both batch and stream processing. It exposes APIs for Java, Python, R, and Scala, as well as an interactive shell for you to run jobs.
-
In Cloudera Machine Learning (CML), Spark and its dependencies are bundled directly into the CML runtime Docker image.
-
Furthermore, you can switch between different Spark versions at Session launch.
-

In a real-life scenario, the underlying data may be shifting from week to week or even hour to hour. It may be necessary to run the ingestion process in CML on a recurring basis. Jobs allow any project script to be scheduled to run inside of an ML Workspace compute cluster.
-
Click on the ←Project menu item in the top panel on the right
-
Click on the Jobs in the side panel
-
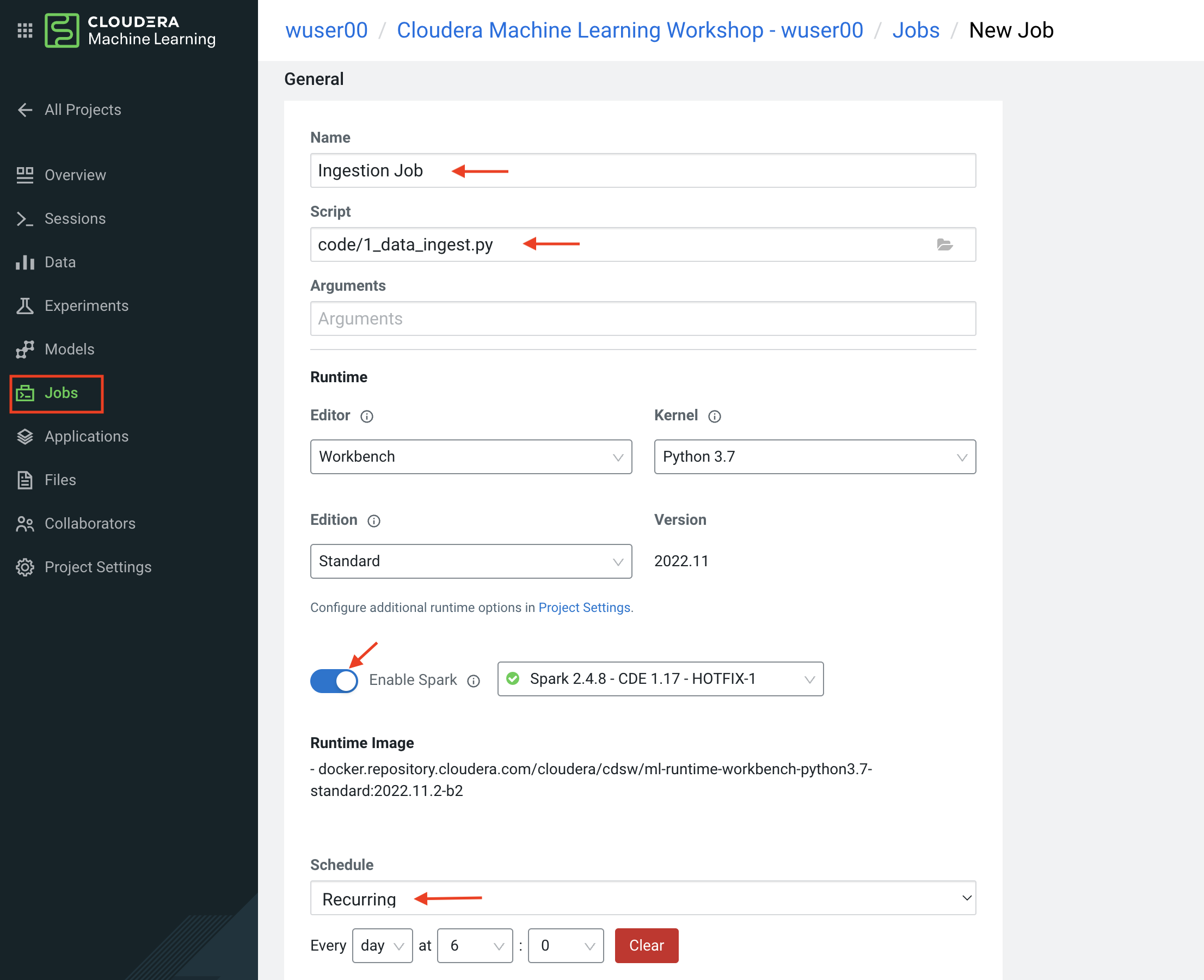
Click New Job
-
Give your job a name (e.g. Ingestion Job) and select code/1_data_ingest.py as the Script to run
-
Toggle the Enable Spark button
-
Select Recurring as the Schedule from the dropdown and provide daily time for the job to run
-
Scroll to the bottom of the page and click the Create Job button
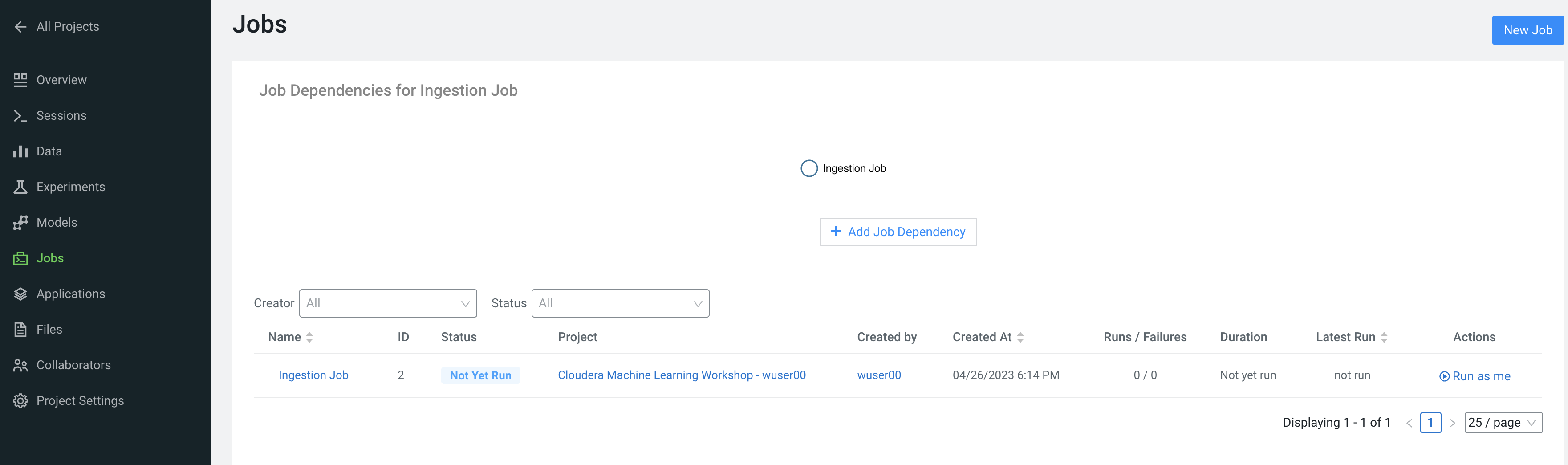
Optionally, you can also manually trigger your job by clicking the Run action button on the right.
With Jobs you can schedule and orchestrate your batch scripts. Jobs allow you to build complex pipelines and are an essential part of any CI/CD or ML Ops pipeline. Typical use cases span from Spark ETL, Model Batch Scoring, A/B Testing and other model management related automations.
-
Click on >_ Sessions in the side panel to return to your running session




In the previous section you loaded a csv file with a python script. In this section you will perform more Python commands with Jupyter Notebooks. Notebooks have a “.ipynb” extension and need to be executed with a Session using the JupyterLabs editor.
-
Launch a new session by selecting the three “vertical dots” on the right side of the top menu bar. If you are in full-screen mode, the Sessions dropdown will appear without having to click into the menu.
image::./images/lab4/lab4-8.png[]
-
Launch the new Session with the following settings:
-
Session Name:
telco_churn_session_2 -
Editor:
JuypterLab -
Kernel:
Python 3.7 -
Resource Profile:
1vCPU/2 GiB Memory|2vCPU/4 GiB Memory -
Runtime Edition:
Standard -
Runtime Version:
Any available version -
Enable Spark Add On:
enable any Spark version
After a few moments the JupyterLab editor should have taken over the screen.
-
*Open Notebook code/2_data_exploration.ipynb from the left side menu and investigate the code
+ Notebook cells are meant to be executed individually and give a more interactive flavor for coding and experimentation.
+ As before, no code changes are required and more detailed instructions are included in the comments. There are two ways to run each cell. Click on the cell you want to run. Hit “Shift” + “Enter” on your keyboard. Use this approach if you want to execute each cell individually. If you use this approach, make sure to run cells top to bottom, as they depend on each other.
-
Alternatively, open the “Run” menu from the top bar and then select “Run All”. Use this approach if you want to execute the entire notebook in bulk.
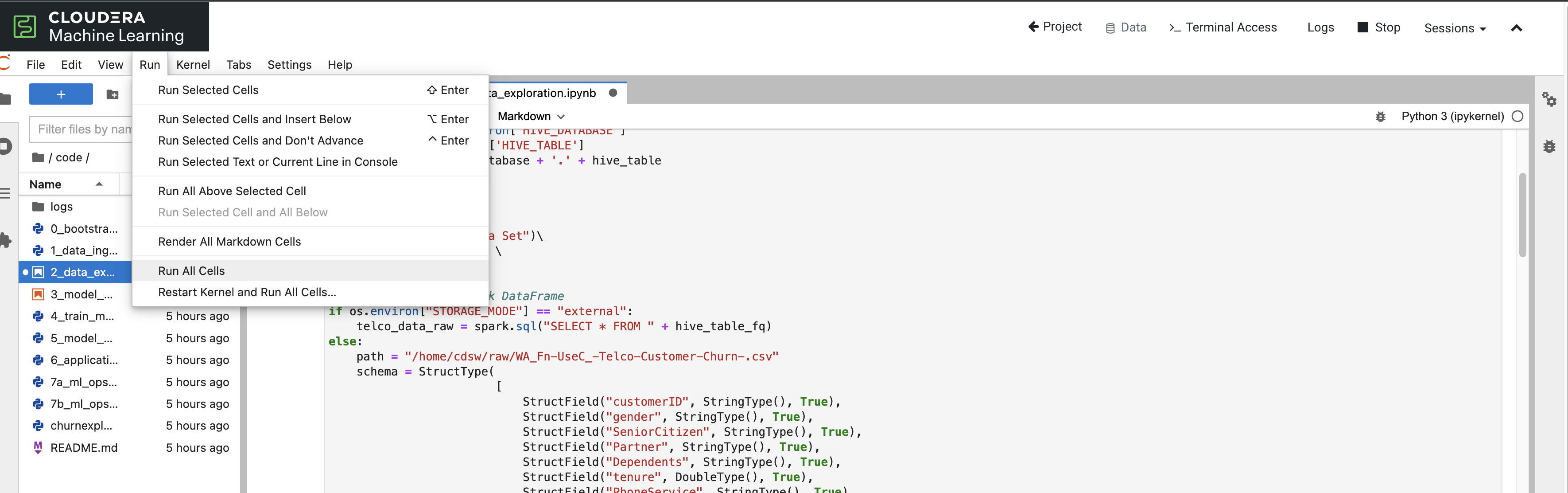
With CML Runtimes, you can easily switch between different editors and work with multiple editors or programming environments in parallel if needed. First you stored a Spark Dataframe as a Spark table in the “1_ingest_data.py” python script using the Workbench editor. Then you retrieved the data in notebook “2_data_exploration.ipynb” using a JupyterLab session via Spark SQL. Spark SQL allows you to easily exchange files across sessions. Your Spark table was tracked as Hive External Tables and automatically made available in Atlas, the Data Catalog, and CDW. This is powered by SDX integration and requires no work on the CDP Admin or Users. We will see more on this in Lab 7.

When you are finished with notebook “2_data_exploration.ipynb” go ahead and move on to notebook “3_model_building.ipynb”. As before, no code changes are required.
-
While still in JupyterLab session, navigate to code/3_model_building.ipynb
-
Execute all code in 3_model_building.ipynb
In this notebook “3_model_building.ipynb” you creat a model with SciKit Learn and Lime, and then store it in your project. Optionally, you could have saved it to Cloud Storage. CML allows you to work with any other libraries of your choice. This is the power of CML… any open source library and framework is one pip install away.
-
Click Stop to terminate your JupyterLab session
-
Return to ← Project and click on >_ Sessions and retun to your single running session
After exploring the data and building an initial, baseline model the work of optimization (a.k.a. hyperparameter tuning) can start to take place. In this phase of an ML project, model training script is made to be more robust. Further, it is now time to find model parameters that provide the “best” outcome. Depending on the model type and business use case “best” may mean use of different metrics. For instance, in a model that is built to diagnose ailments, the rate of false negatives may be especially important to determine “best” model. In cybersecurity use case, it may be the rate of false positives that’s of most interest.
To give Data Scientists flexibility to collect, record, and compare experiment runs, CML provides out-of-the-box mlflow Experiments as a framework to achieve this.
-
Inside a running Workbench session, navigate to code/4_train_model.py
-
Click the Play button in the top menu to run all lines
This script uses “kernel” and “max_iter” as the two parameters to manipulate during model training in order to achieve the best result. In our case, we’ll define “best” as the highest “test_score”.
-
While your script is running, click on ← Project in the top panel of the REPL
-
Click on Experiments in the side bar
-
Click on Churn Model Tuning
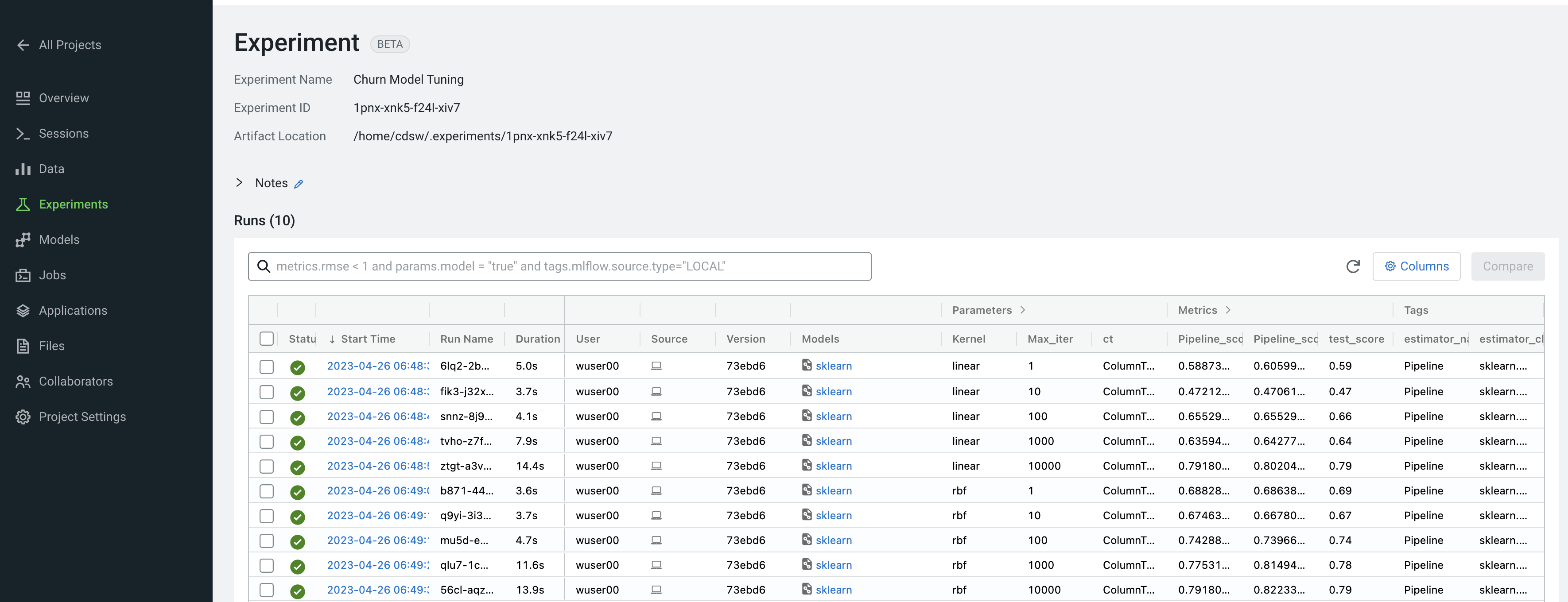
As expected, higher number of max_iterations produces better result (higher test_score). Interestingly, the choice of kernel does not make a difference at higher max_iter values. We can choose linear as it allows for faster model training.
-
Select all runs with “linear” Kernel
-
Click the Compare button
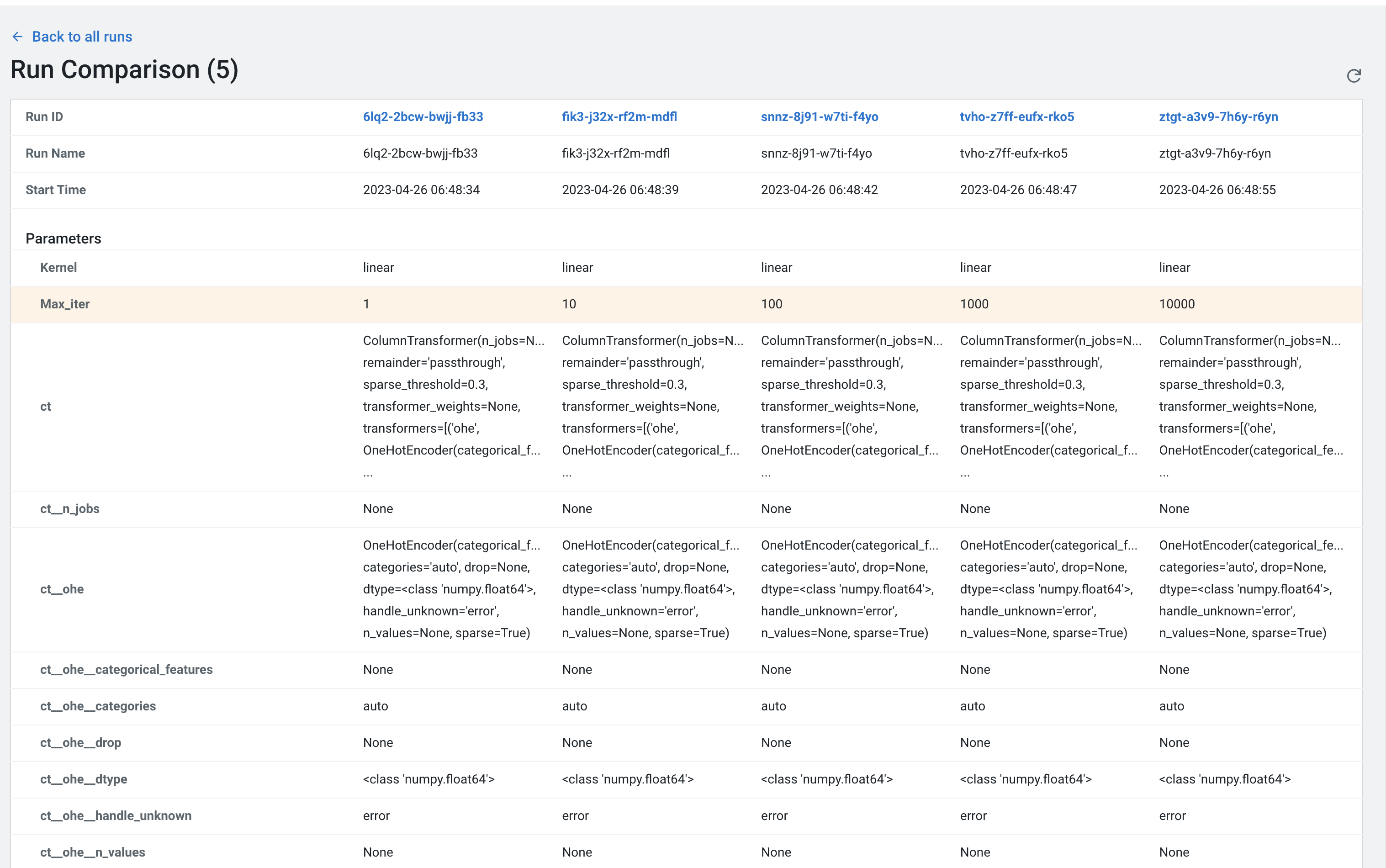
-
Scroll down and click on the test_score link
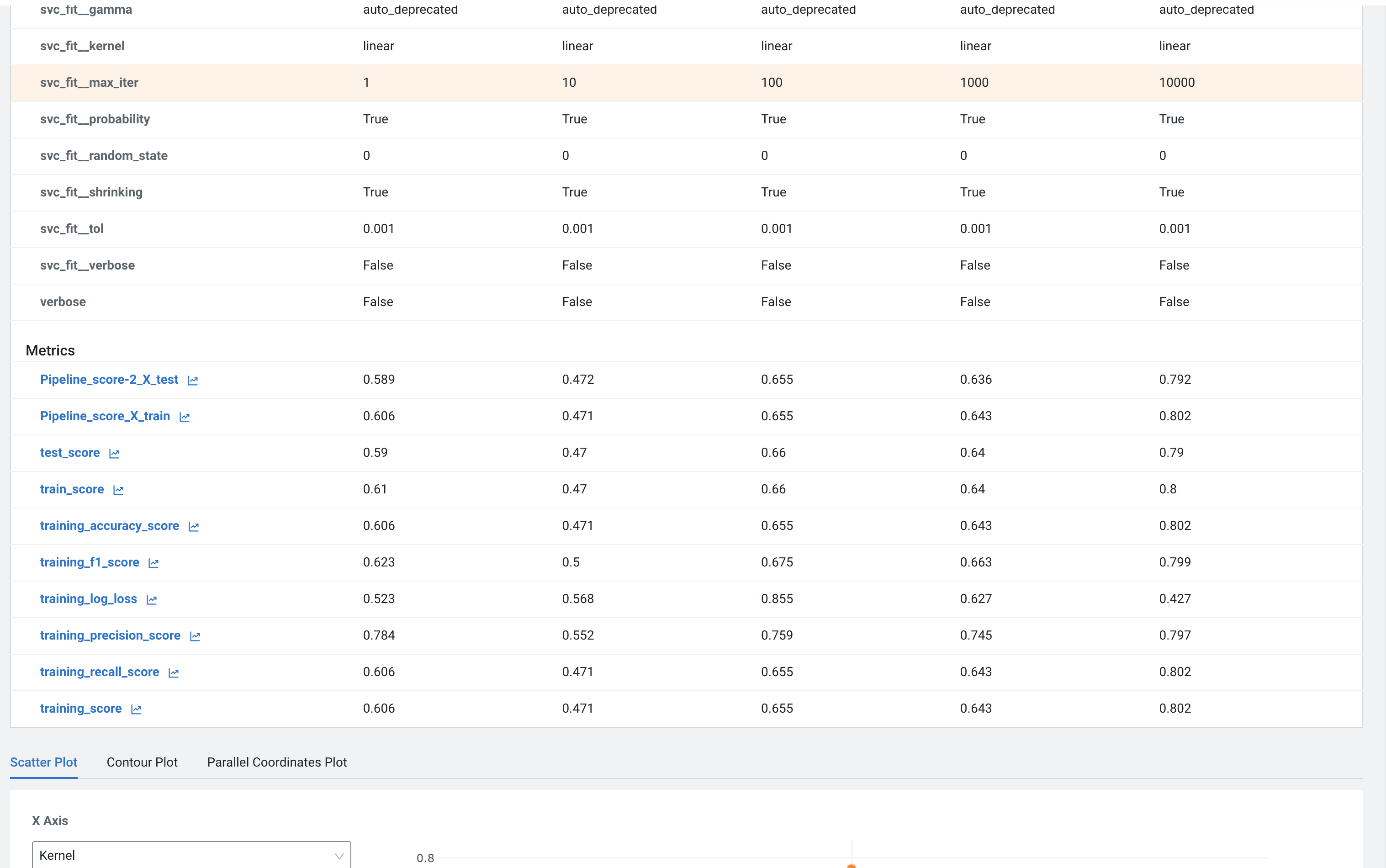
Built-in visualizations in mlflow allow for more detailed comparison of various experiment runs and outcomes.



Once a model is trained its predictions and insights must be put to use so they can add value to the organization. Generally this means using the model on new, unseen data in a production environment that offers key ML Ops capabilities.
One such example is Batch Scoring via CML Jobs. The model is loaded in a script and the predict function provided by the ML framework is applied to data in batch. The script is scheduled and orchestrated to perform the scoring on a regular basis. In case of failures, the script or data are manually updated so the scoring can resume.
This pattern is simple and reliable but has one pitfall. It requires the user or system waiting for the scoring job to run at its scheduled time. What if predictions are required on a short notice? Perhaps when a prospect navigates on an online shopping website or a potential anomaly is flagged by a third party business system?
-
CML Models allow you to deploy the same model script and model file in a REST Endpoint so the model can now serve responses in real time. The endpoint is hosted by a container.
-
CML Models provides tracking, metadata and versioning features that allow you to manage models in production.
-
Similarly, CML Applications allows you to deploy visual tools in an endpoint container. This is typically used to host apps with open source libraries such as Flask, Shiny, Streamlit and more.
-
Once a model is deployed to a CML Models container, a CML Application can forward requests to the Model endpoint to provide visual insights powered by ML models.
Below are the steps to deploy a near-real-time scoring model:
-
Click on Model Deployments in the side panel
-
Click on New Model
-
Important! Name your model
Churn Model API Endpoint. Any other name will cause issues with downstream scripts. -
Description:
Predicts and explains customer churn probability -
Important! Uncheck Enable Authentication
-
Under File select code/5_model_serve_explainer.py
-
Under Function enter
explain -
For Example Input enter the following JSON
-
You do not need to Enable Spark for model serving in this case
This JSON is a set of key value pairs representing a customer’s attributes. For example, a customer who is currently on a DSL Internet Service plan.
{
"StreamingTV": "No",
"MonthlyCharges": 70.35,
"PhoneService": "No",
"PaperlessBilling": "No",
"Partner": "No",
"OnlineBackup": "No",
"gender": "Female",
"Contract": "Month-to-month",
"TotalCharges": 1397.475,
"StreamingMovies": "No",
"DeviceProtection": "No",
"PaymentMethod": "Bank transfer (automatic)",
"tenure": 29,
"Dependents": "No",
"OnlineSecurity": "No",
"MultipleLines": "No",
"InternetService": "DSL",
"SeniorCitizen": "No",
"TechSupport": "No"
}

-
Scroll to the bottom of the page and click on the Deploy Model button
Model deployment may take a minute or two, meanwhile you can click on the Model name and explore the UI. The code for a sample request is provided on the left side. On the right side observe the model’s metadata. Each model is assigned a number of attributes including Model Name, Deployment, Build and creation timestamp.
-
Note down the Build Id of your model, we will need it in MLOps part of the workshops
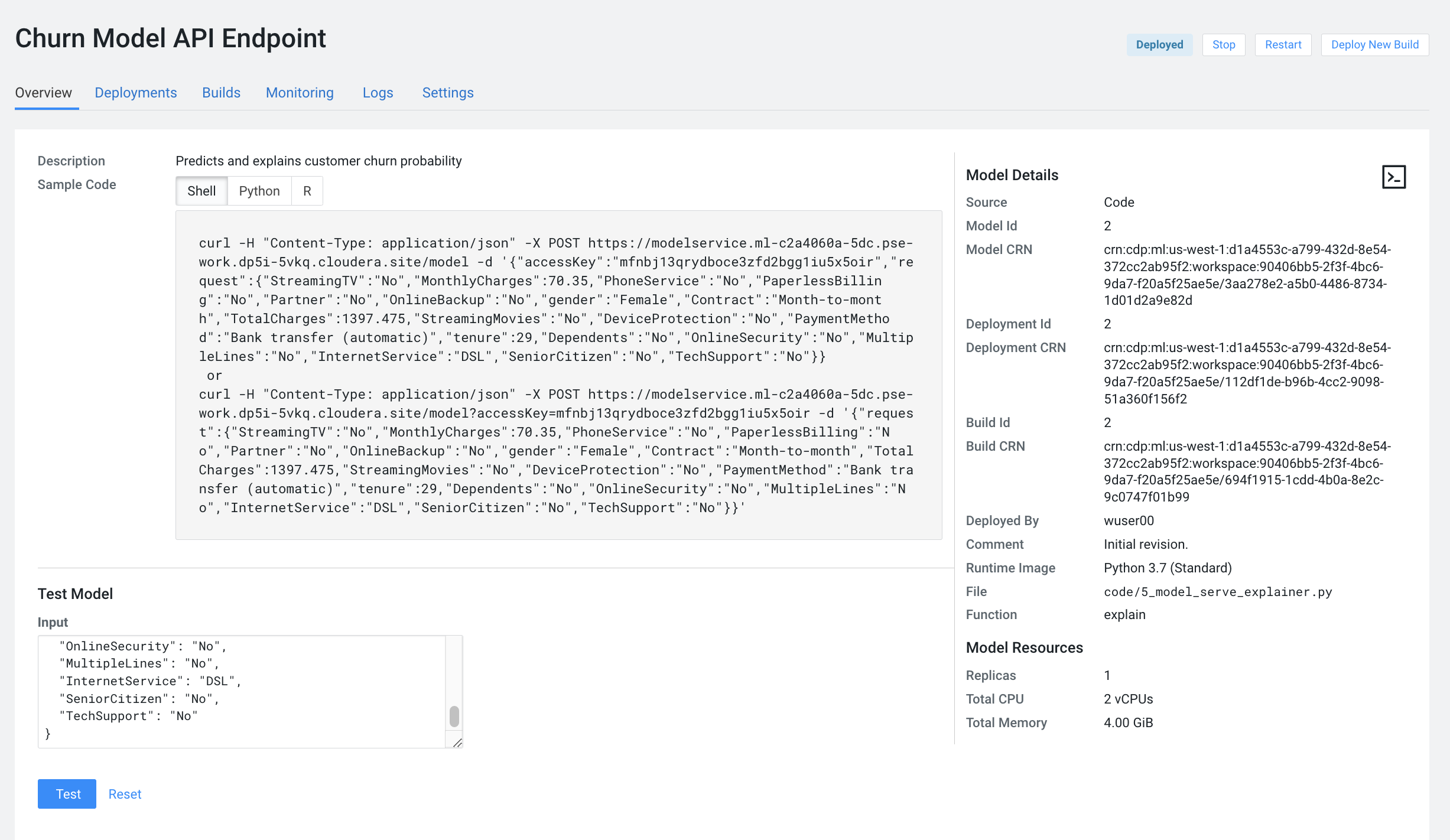
-
Once your model is Deployed, click the Test button
The test simulates a request submission to the Model endpoint. The model processes the input and returns the output along with metadata and a prediction for the customer. In addition, the request is assigned a unique identifier. We will use this metadata for ML Ops later in Lab 6.

---------------------------------------------MLOps Aside--------------------------------------------------------------- Before moving on to the next section, we will kick off a script to simulate real-world model performance.
-
Return to a running session () or start a new session if none are running
-
Navigate to code/7a_ml_ops_simulation.py
-
Run the entire script by clicking the Play button in the top menu to run all lines
This will generate a 1000 calls to the model, while we explore other parts of CML. Do not wait for this script to finish. Proceed to the next part of the workshop.
Navigate back to the Project Overview page and open the “5_model_serve_explainer.py" script. Scroll down and familiarize yourself with the code.
-
Notice the method “explain” method. This is the Python function whose purpose is to receive the Json input as a request and return a Json output as a response.
-
Within the method, the classifier object is used to apply the model object’s predict method.
-
In addition, notice that a decorator named “@cdsw.model_metrics” is applied to the “explain” method. Thanks to the decorator you can use the “cdsw.track_metric” methods inside the “explain” method to register each scalar value associated with each request.
-
The values are saved in the Model Metrics Store, a built in database used for tracking model requests.
Navigate back to the Project Overview page. Open the “models/telco_linear” subfolder and notice the presence of the “telco_linear.pkl” file. This is the physical model file loaded by the .py script you just inspected above.

You have already seen that Cloudera Data Visualization is deployed in CML as an Application. In fact, any custom, UI app can be hosted within CML. These can be streamlit, Django, or Rshiny (or other frameworks) apps that deliver custom visualization or incorporate a real-time model scoring. In the following steps we will deploy an Application for the Churn Customer project:
-
Go to Models and click on the model that you’ve deployed
-
Go to the Settings tab and copy the Access Key string
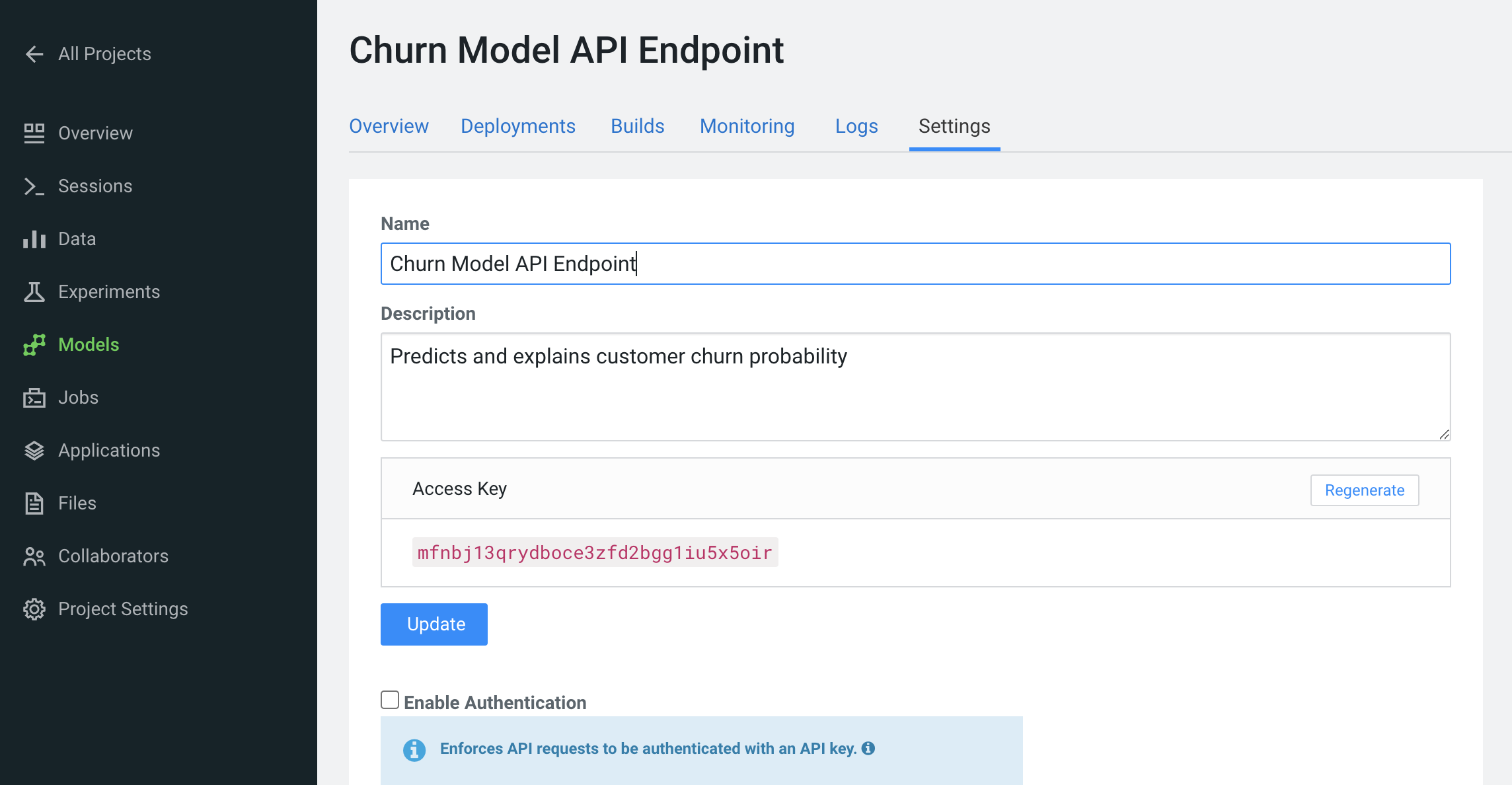
-
Navigate to Files > flask > single_view.html and open in a new session. (don’t start the session)
-
Important! On line 61 of the file, update the access key value with the Access Key you got earlier. Click File > Save (or ⌘+S)
-
Click on Application in the side panel
-
Click on New Application
-
Give your application a name (
Churn Model Explainer), and provide a unique subdomain -
Under Scripts select code/6_application.py
-
Ensure that a Workbench editor is selected and Enable Spark toggle is turned on
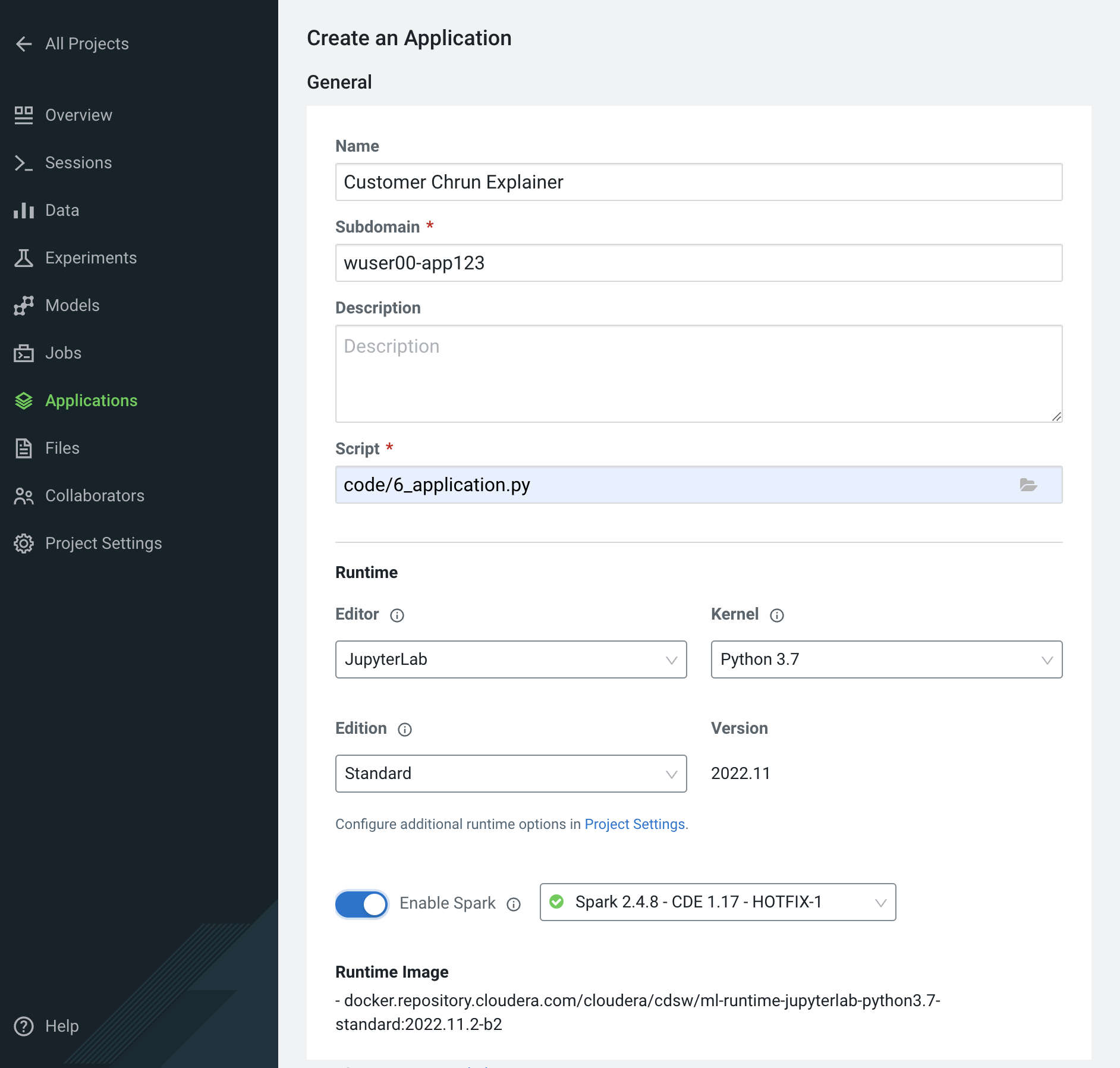
-
Scroll the bottom of the page and click on Create Application
Application startup can take up to 2 minutes, and once the application is ready you’ll see a card similar to this:



Click on the application in order to open it. This will automatically redirect you to the Visual Application landing page where the same data you worked with earlier is presented in an interactive table.
On the left side notice the probability column. This is the target variable predicted by the Machine Learning Model. It reflects the probability of each customer churning. The value is between 0 and 1. A value of 0.49 represents a 49% probability of the customer churning. By default, if the probability is higher than 50% the classifier will label the customer as “will churn” and otherwise as “will not churn”.
The 50% threshold can be increased or decreased implying customers previously assigned a “will churn” label may flip to “will not churn” and vice versa. This has important implications as it provides an avenue for tuning the level selectivity based on business considerations but a detailed explanation is beyond the scope of this content.
Next, click on the customer at the top of the table to investigate further.

A more detailed view of the customer is automatically loaded. The customer has a 58% chance of churning.
The Lime model applied to the classifier provides a color coding scheme highlighting the most impactful features in the prediction label being applied to this specific customer.
For example, this customer’s prediction of “will churn” is more significantly influenced by the “Internet Service” feature.
-
The dark red color coding signals that the customer is negatively impacted by the current value for the feature.
-
The current values of Monthly Charges and Phone Service also increase the likelihood of churn while the values of the Streaming Movies and Total Charges features decrease the likelihood of churn.
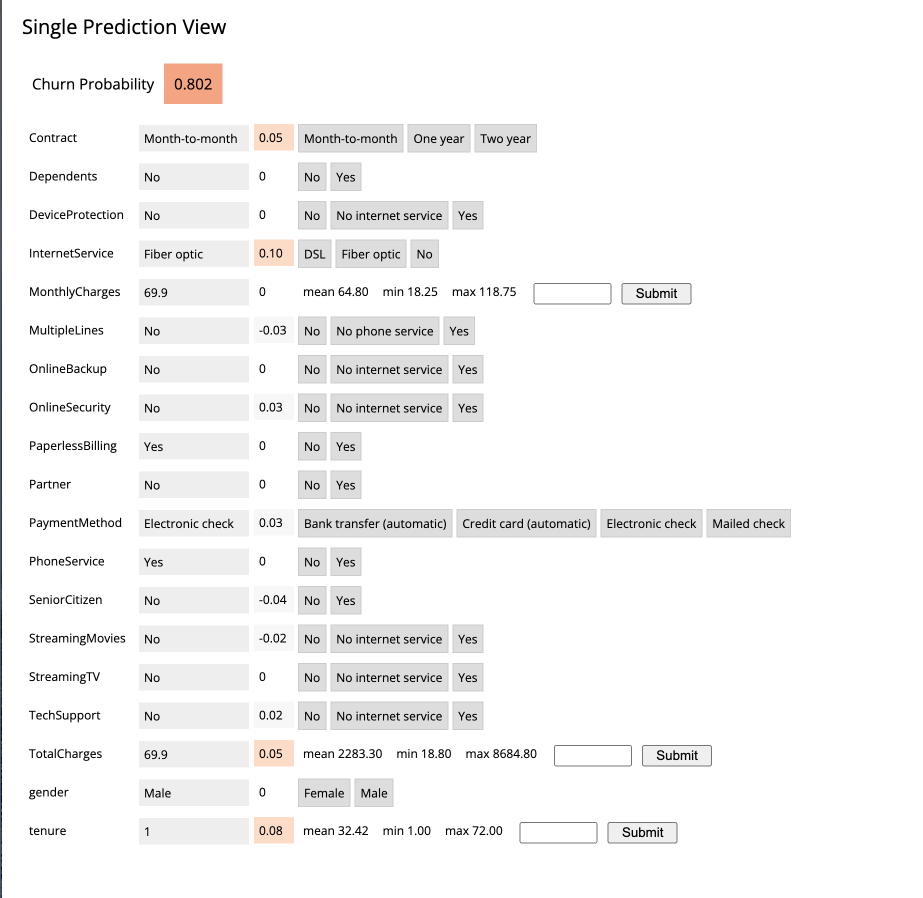
Let’s see what happens if we change the value for the most impactful feature in this given scenario i.e. “Internet Service”. Currently the value is set to “Fiber Optic”. Hover over the entry in the table and select “DSL”.
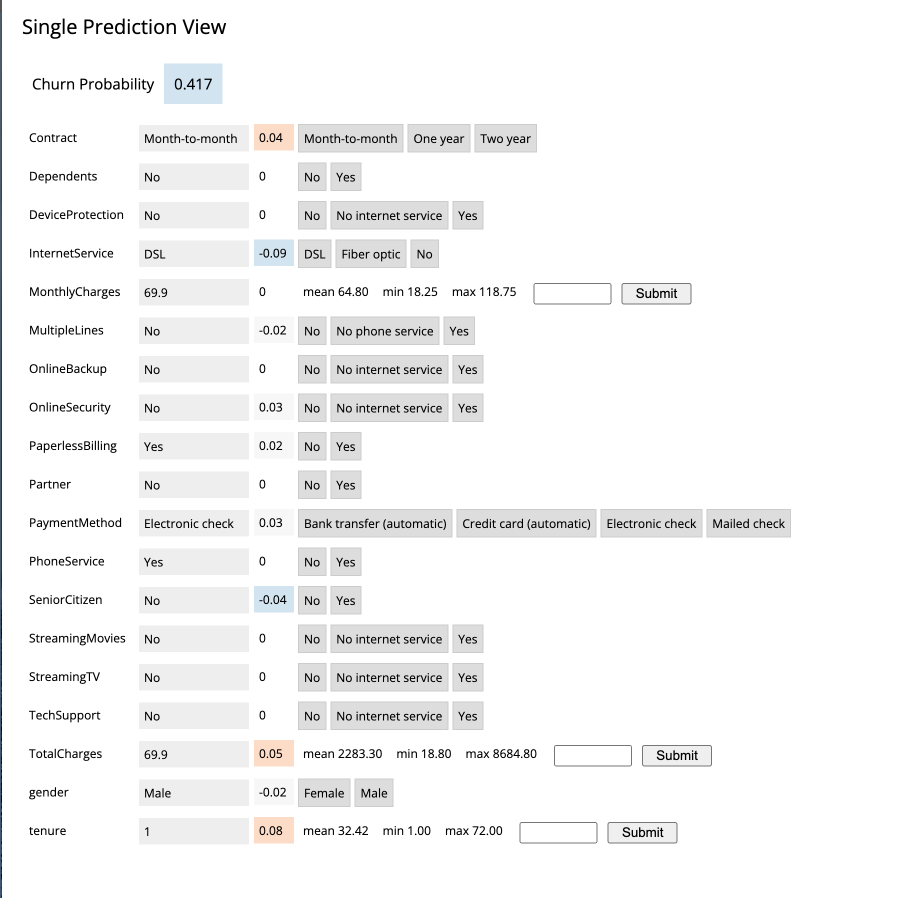
The table has now reloaded and the churn probability for this customer has dramatically decreased to roughly 15%.
This simple analysis can help the marketer optimize strategy in accordance to different business objectives. For example, the company could now tailor a proactive marketing offer based on this precious information. In addition, a more thorough financial analysis could be tied to the above simulation perhaps after adjusting the 50% threshold to increase or decrease selectivity based on business constraints or customer lifetime value assigned to each customer.


Navigate back to the CML Project Home folder (Overview). Open the “Code” folder and then script “6_application.py”. This is a basic Flask application that serves the HTML and some specific data used for.
Click on Open in Session to visualize the code in a more reader friendly-mode.

Now you will be able to explore the code with the Workbench Editor. The “Launch Session” form will automatically load on the right side of your screen. There is no need to launch a session so you can just minimize it.
As always no code changes are required. Here are some key highlights:
-
At lines 177 - 191 we load the model and use the “Explain” method to load a small dataset in the file. This is similar to what you did in script 5. If you want to display more data or fast changing data there are other ways to do this, for example with Cloudera SQL Stream Builder.
-
At line 248 we run the app on the "CDSW_APP_PORT". This value is already preset for you as this is a default environment variable. You can reuse this port for other applications.
The following steps assume you have executed the 7a_ml_ops_simulation.py script as shown in Lab 6 section MLOps Aside. If you haven’t done it please go back and make sure to run the model simulation script.
Navigate back to the project overview and launch a new session with the following configurations.
Session Name: telco_churn_ops_session
Editor: Workbench
Kernel: Python 3.7
Runtime Edition: Standard
Runtime Version: Any available version
Enable Spark Add On: any Spark version
Resource Profile: 1vCPU/2 GiB Memory
-
Once the session is running, open script “7b_ml_ops_visual.py” and explore the code in the editor.
-
Execute the whole script end to end without modifications.
-
Observe the code outputs on the right side. Here are the key highlights:
-
Model predictions are tracked in the CML Models Metrics Store. This is enabled by the use of the Python decorator and the use of “cdsw.track_metrics” methods in script 5. What is being tracked is completely up to the script developer.
-
You can then extract the predictions and related metadata and put the information in a Pandas dataframe. Again, the Python library you use does not matter and is entirely up to the developer.
-
This is exactly what the first diagram on the right side of your screen shows. Each column represents a prediction request reaching your CML Model endpoint. Each row represents a metric you are tracking in the CML Models Metrics Store.
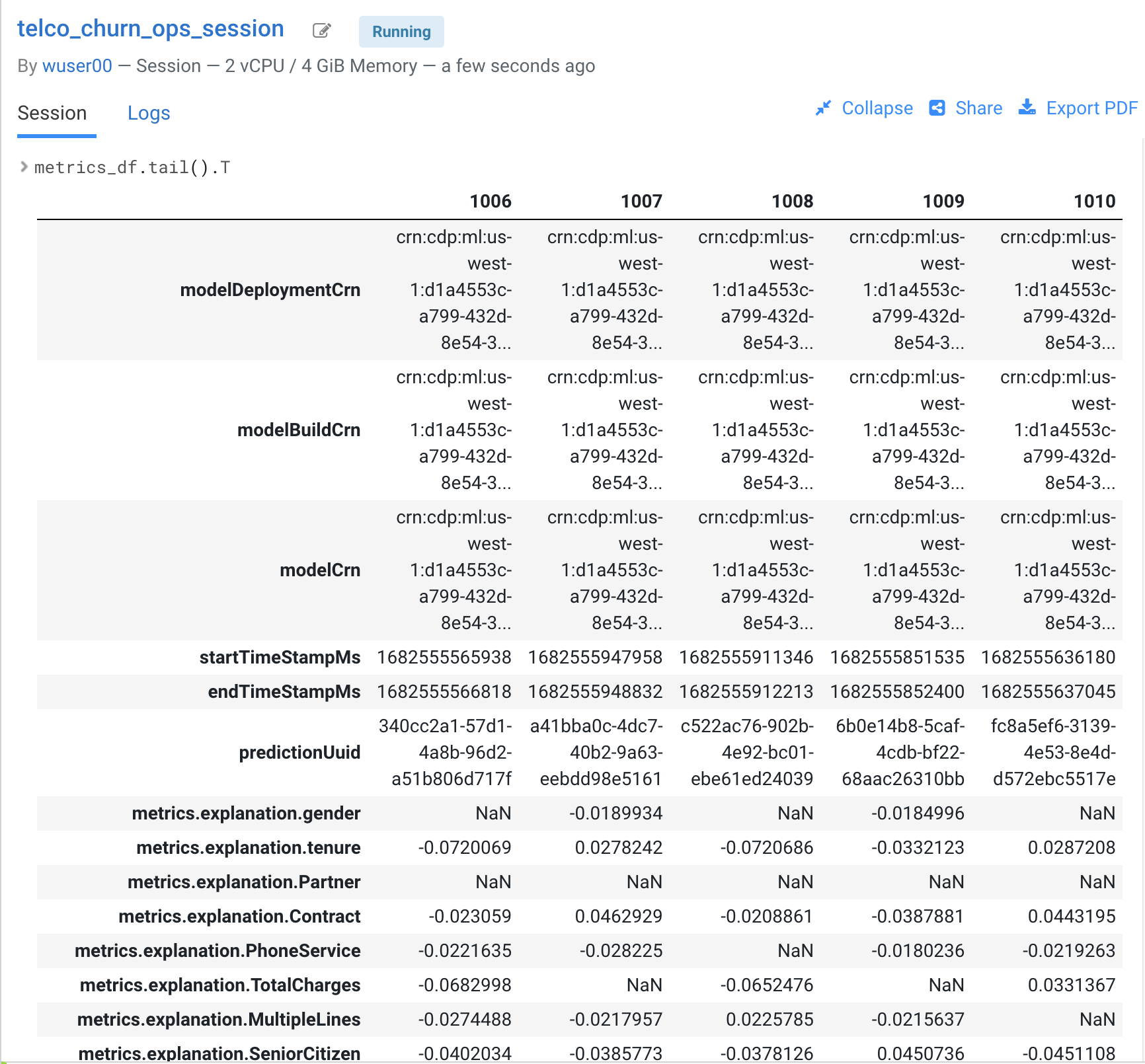
-
-
Once the tracked metrics have been saved to a Python data structure they can be used for all sorts of purposes.
-
For example, the second diagram shows a basic line plot in Seaborn where the models’ output probabilities are plotted as a function of time. On the X axis you can see the timestamp associated with each request. On the Y axis you can find the associated output probability.
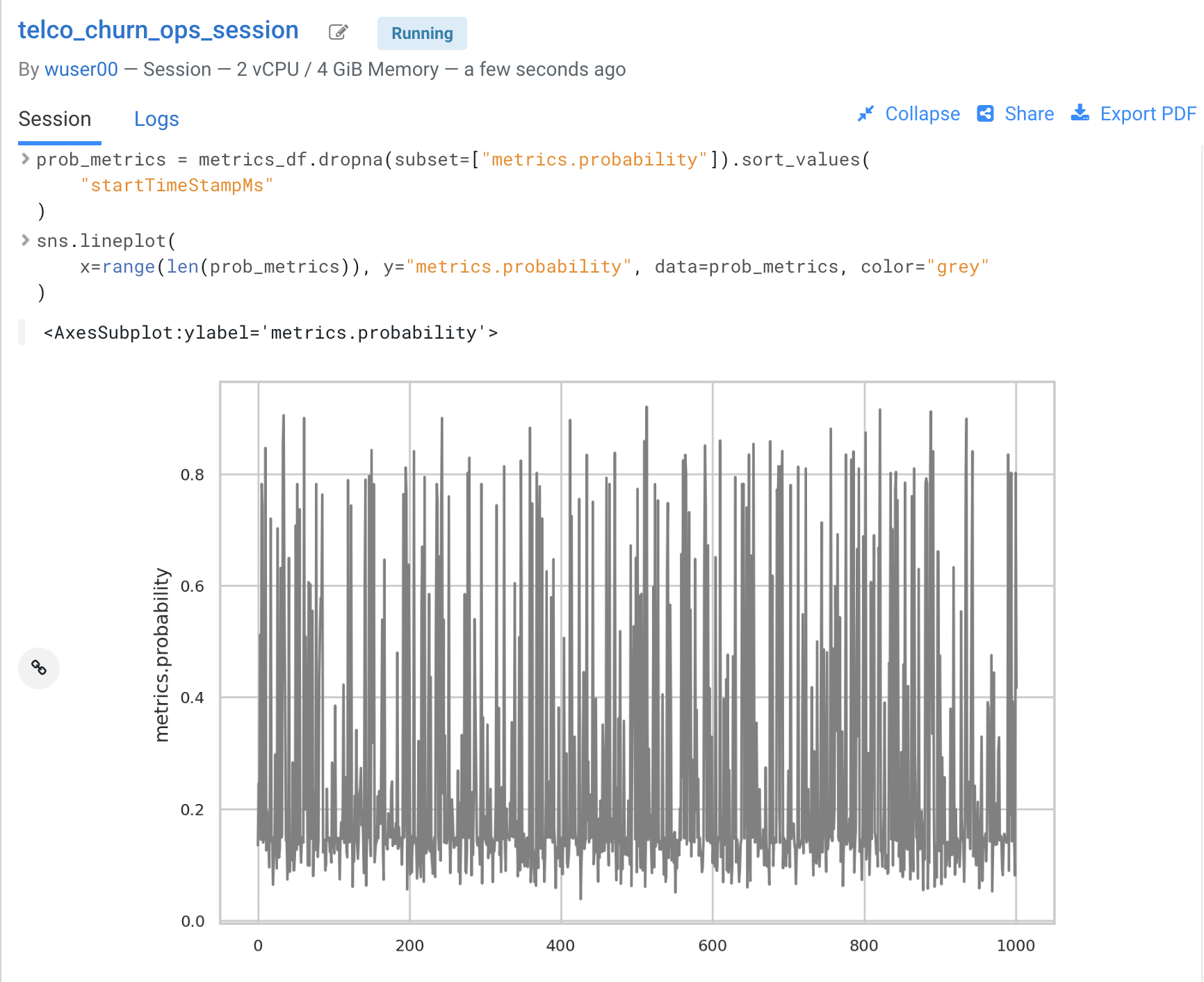
-
Similarly, you can plot processing time as shown in the third diagram. This represents the time duration required to process a particular request.
-
As an example, this information could be used to trigger the deployment of more resources to support this model endpoint when a particular threshold is passed. You can deploy more resources manually via the UI, or programmatically and in an automated CI/CD pipeline with CML APIv2 and CML Jobs.
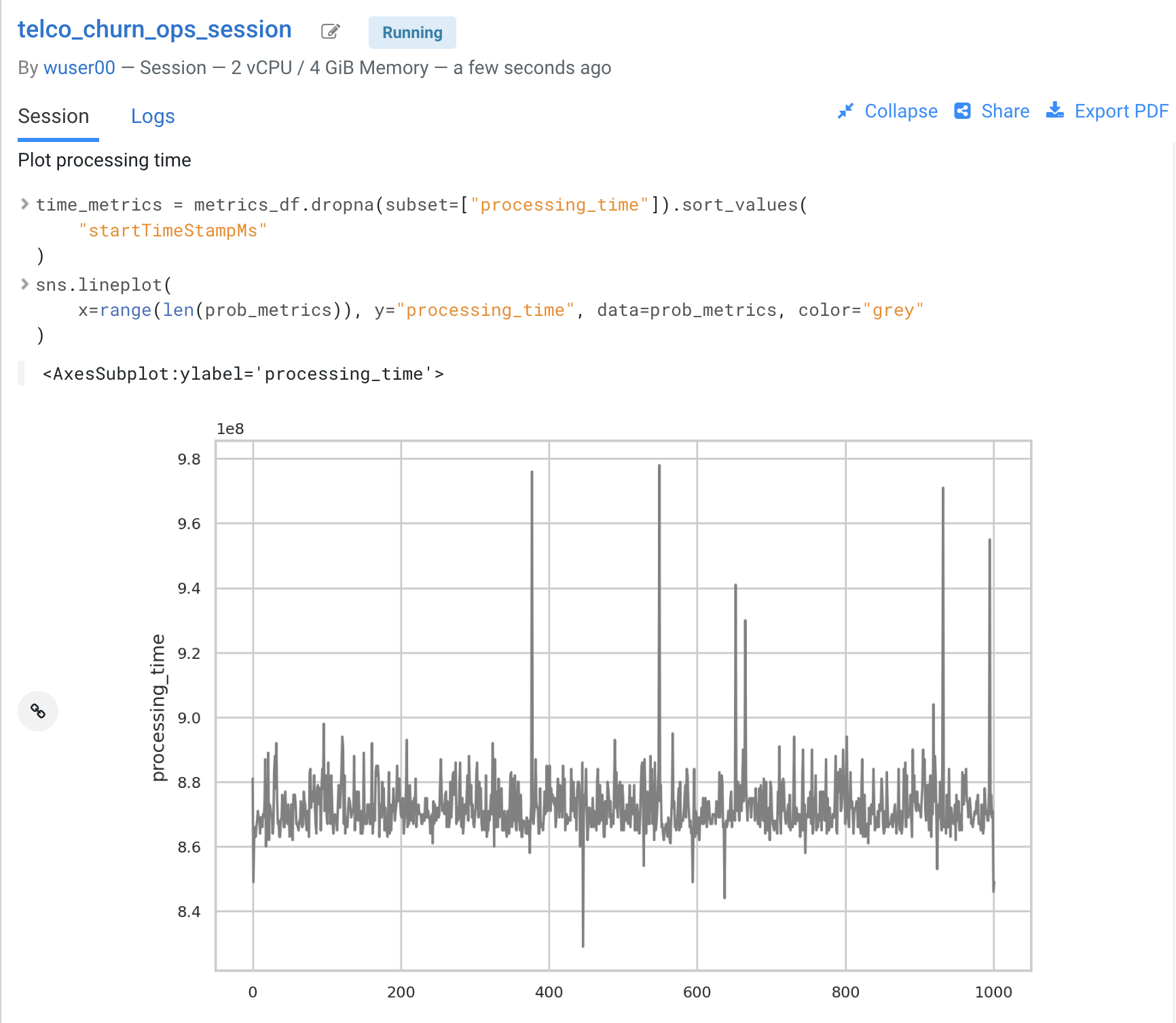
-
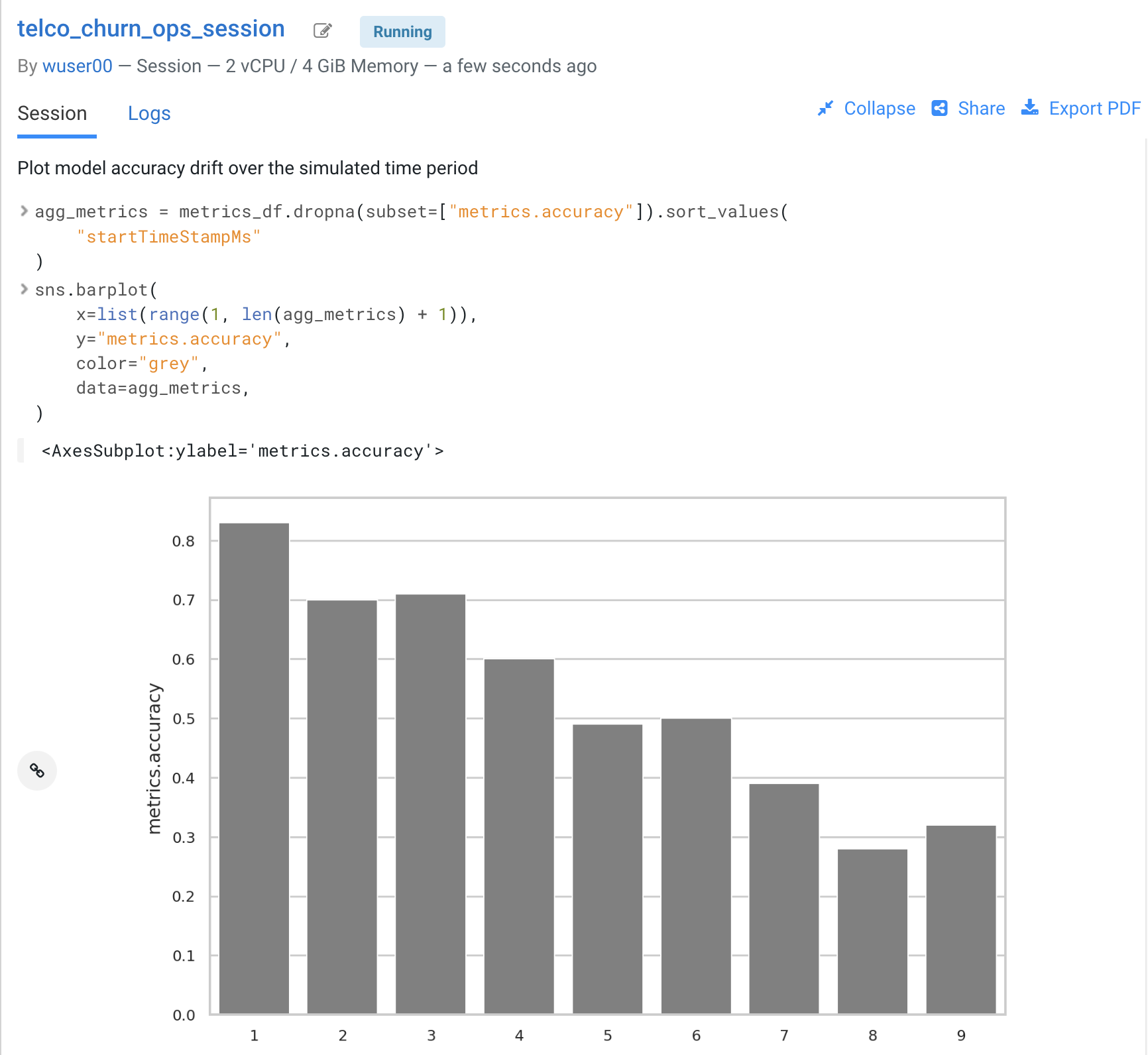
You can also monitor the model’s accuracy over time. For example, the below diagram shows a line plot of prediction accuracy sorted over time. As you can see, the trend is negative and the model is making increasingly less accurate predictions.
-
Just like with processing time and other metrics, CML allows you to implement ML Ops pipelines that automate actions related to model management. For example, you could use a combination of CML Jobs and CML APIv2 to trigger the retraining and redeployment of a model when its accuracy reaches a particular threshold over a particular time period.
-
As always this is a relatively basic example. CML is an open platform for hands-on developers which gives users the freedom to implement more complex ML Ops pipelines.
-
Ground truth metrics can be collected with the cdsw.track_delayed_metrics method. This allows you to compare your predictions with the actual event after the prediction was output. In turn, this allows you to calculate the model accuracy and create visualizations such as the one above.
-
For an example of the cdsw.track_delayed_metrics method open the “7a_ml_ops_simulation.py” script and review lines 249 - 269. Keep in mind that this is just a simulation.
-
In a real world scenario the requests would be coming from an external system or be logged in a SQL or NoSQL database. In turn, the script above would be used to set ground truth values in batch via a CML Job or in real time with a CML Model endpoint.




CDP is an end-to-end hybrid enterprise data platform. Every user, workload, and dataset and machine learning model can be governed from a central location via SDX, the Shared Data Experience.
Under the hood, SDX tracks and secures activity related to each CDP Data Service via “Hooks” and “Plugins”, including CML. If you want your models to be logged in SDX you have to add them to the lineage.yml file located in your project home folder.
-
Click on Overview and find lineage.yml file
-
Click on the file to open


Take note of the metadata that is present here, including the source table name and the query used to create the training dataset. Additional metadata can be provided here.
-
Click on the top left corner menu (Bento menu)
-
Click on Management Console
-
Click on the CDP environment you have been working in (where ML Workspace is deployed)
-
Click on Atlas under QUICK LINKS
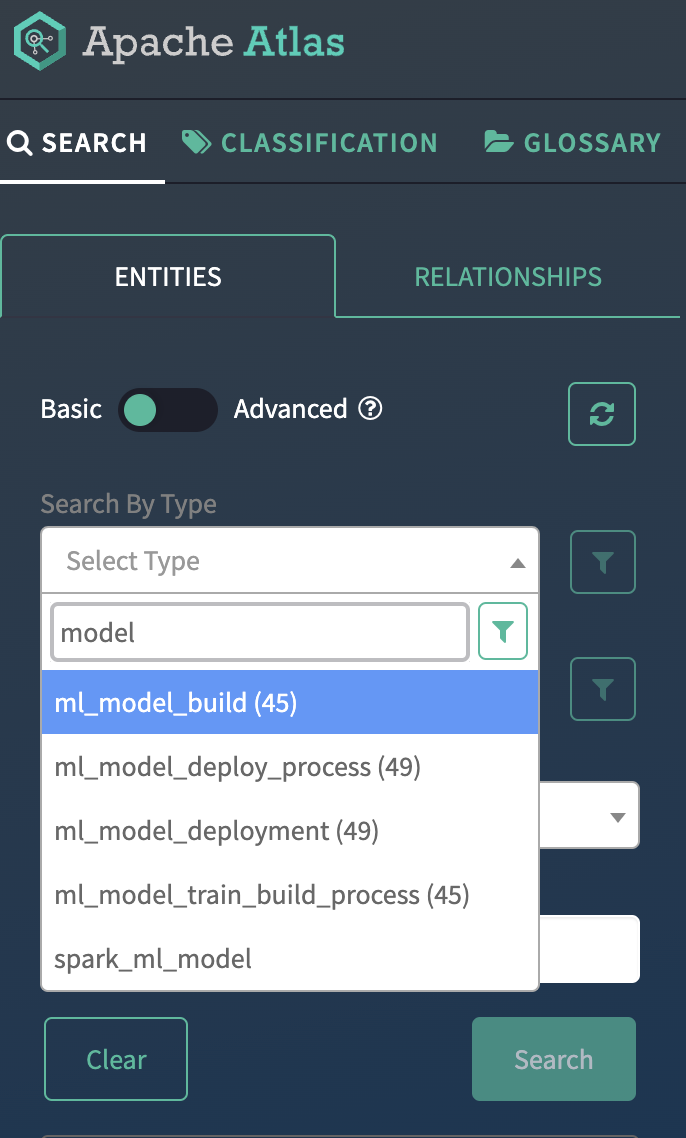
From the Atlas UI, search for ML models by entering the “ml_model_build” type. Notice that there are various Atlas entities to browse for models.
In the output, you will see all models that your colleagues deployed in this workshop. Notice that each model is assigned a unique ID at the end. That ID corresponds to the Model Build from CML. Identify your model using the Build Id noted down when you deployed your model. select the model you created.
-
Open your model by clicking its Model Name - Build Id.
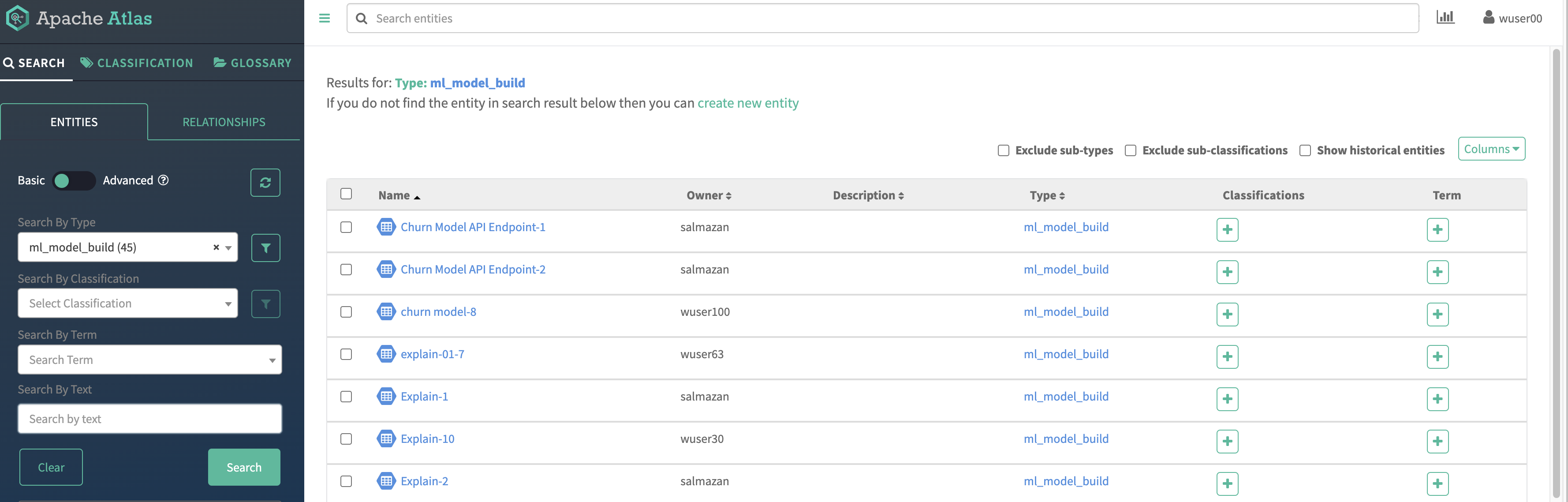
Familiarize yourself with the Model properties tab. Notice that each model logged is associated with rich metadata. You can customize Atlas Model metadata by editing the lineage.yml file in the CML Project Home folder
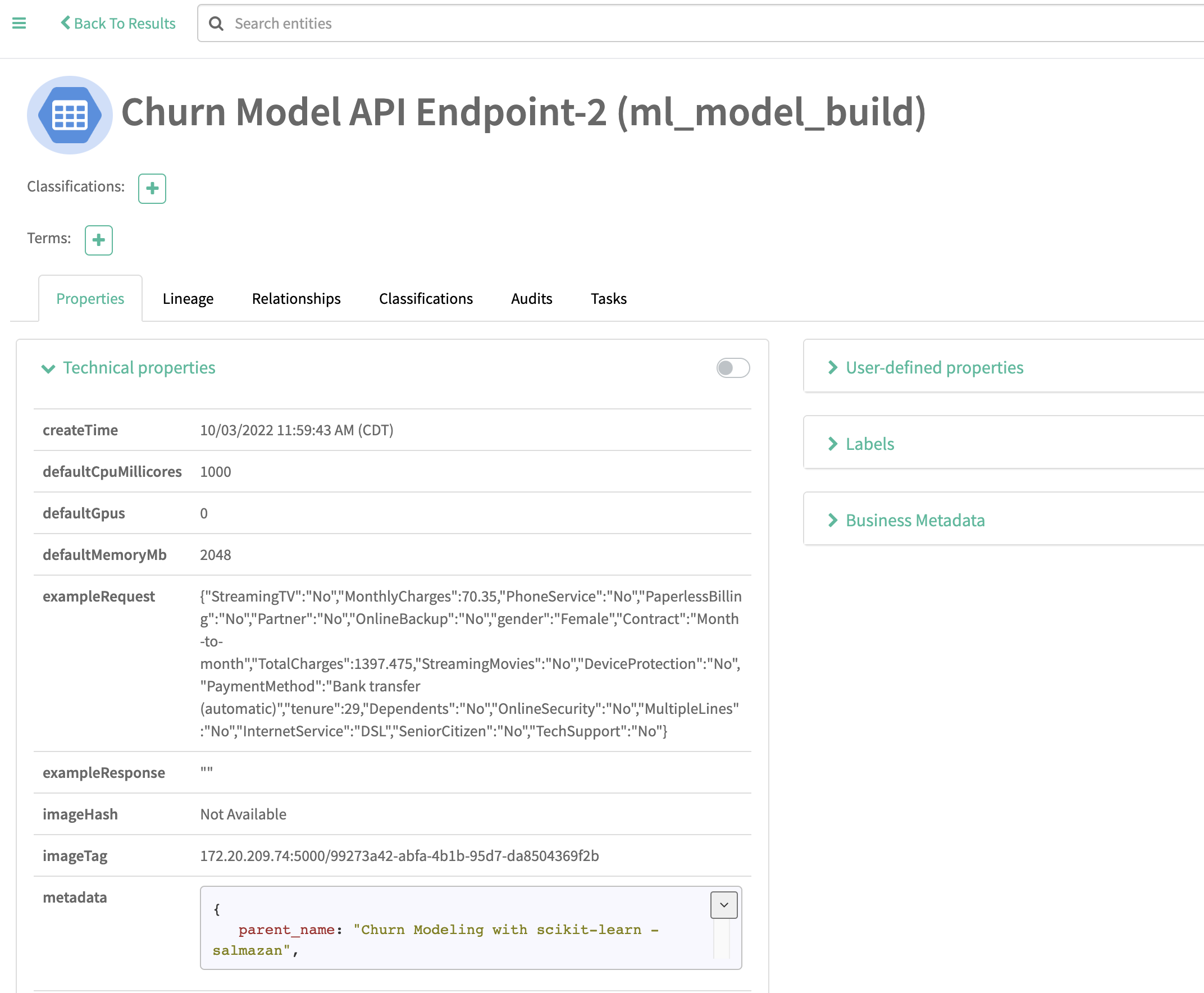

Atlas and Ranger provides a rich set of Governance and Security capabilities. For example, you can apply Atlas tags to your entities across Data Services and then propagate Ranger policies to automatically secure applications across complex pipelines.
A detailed exploration of SDX in the context of CML is not in scope for this workshop but please visit the “Next Steps” section to find out more on this and other topics.






APIv2 is a powerful tool for automating ML workflows for managing projects, jobs, models, and applications. In this section we explore the use of the API and use it to cleanup the artifacts created in this lab.
-
Go back to your ML Workspave an retrieve an API key from User Settings > API Keys > Create API Key
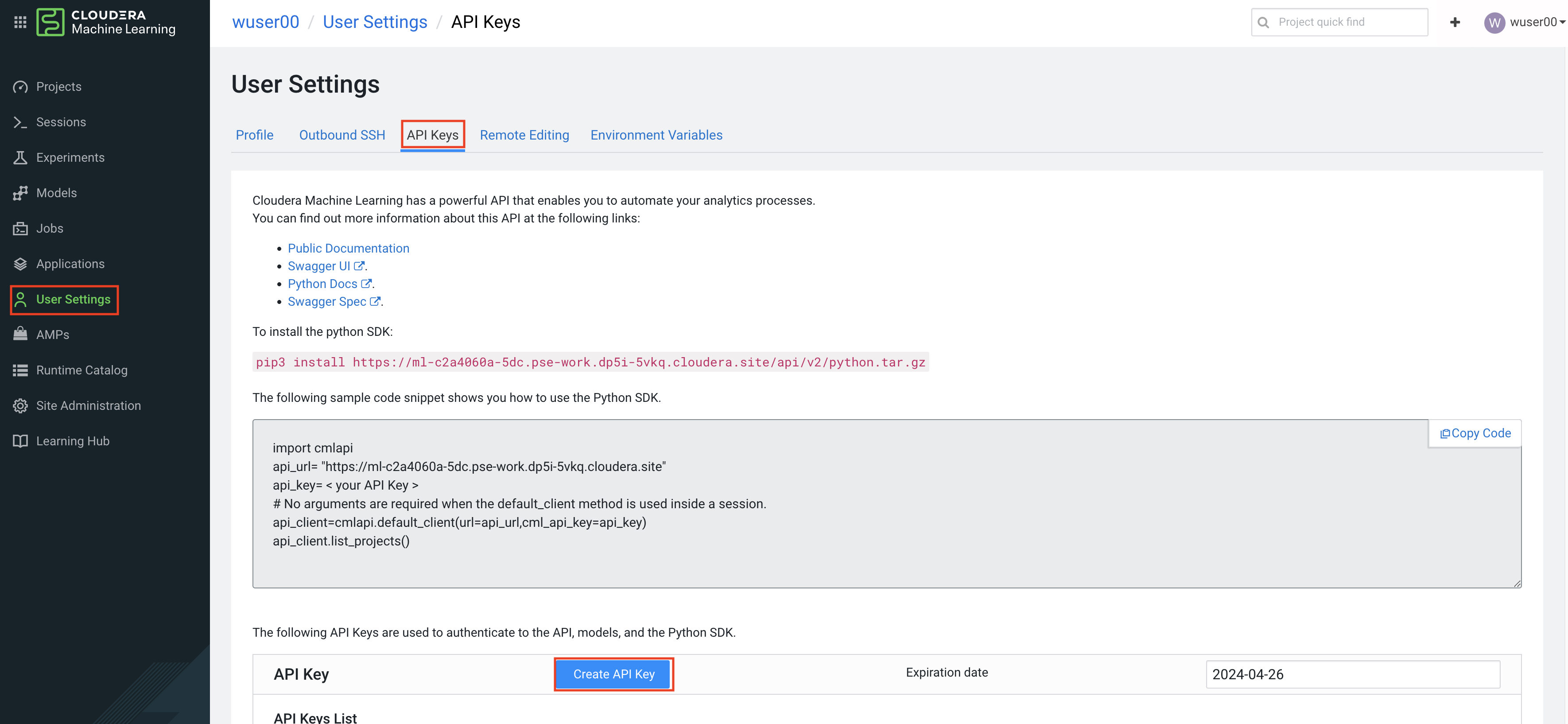
-
Copy the Python code in the box on this same page
-
Create a new Session or open an existing one
-
Create a new file (you choose the file name)
-
Paste the code into this new file
-
Replace < your API Key > with your actual API key, in quotes
-
Run the code snippet and determine your projectId from the output (e.g.
19yp-be0v-acb4-8pdm) -
Run api_client.list_jobs("19yp-be0v-acb4-8pdm")
-
Run create_job_run(cmlapi.CreateJobRunRequest(), project_id=”<project id>”,job_id=”<job id>”) functions to kick off the job we created in Lab 4. For reference, see API v2 Usage.
-
Caution! Irreversible step! Do only if you are done with the project!
Delete your project with delete_project() command.

In this workshop you created an end to end project to support a Machine Learning model in Production.
-
You easily created a Spark Session and explored a large dataset with the PySpark library. Thanks to CML Runtimes and Sessions you were able to switch between editors, resources, and optionally Python and Spark versions at the click of a button.
-
You created a Model REST Endpoint to serve predictions to internal or external business applications. Then, you built an interactive dashboard to make the “black box model” interpretable for your business stakeholders.
-
You explored the foundations of a basic ML Ops pipeline to easily retrain, monitor, and reproduce your model in production. With the CML Models interface you unit tested and increased model observability. Then, you monitored its performance with CML APIv2.
-
Finally, you used CDP SDX to log and visualize Model Metadata and Lineage.
If you want to learn more about CML and CDP we invite you to visit the following assets and tutorials or ask your Cloudera Workshop Lead for a follow up.
-
Learn how to use Cloudera Applied ML Prototypes to discover more CML Projects using MLFlow, Streamlit, Tensorflow, PyTorch and other popular libraries. The AMP Catalog is maintained by the Cloudera Fast Forward Labs team and allows you to automatically deploy complex use cases within minutes.
-
CML HowTo: A series of tips and tricks for the CML beginner
-
Sentiment Analysis in R: and end to end ML project with SparklyR and GPU training
-
CSA2CML: Build a real time anomaly detection dashboard with Flink, CML, and Streamlit
-
SDX2CML: Explore ML Governance and Security features in more detail to increase legal compliance and enhance ML Ops best practices.
-
CML2CDE: Create CI/CD Pipelines for Spark ETL with CML Notebooks and CDE Virtual Cluster
-
API v2: Familiarize yourself with API v2, CML’s goto Python Library for ML Ops and DevOps
-
Distributed PyTorch with Horovod: A quickstart for distributing Horovod with the CML Workers API