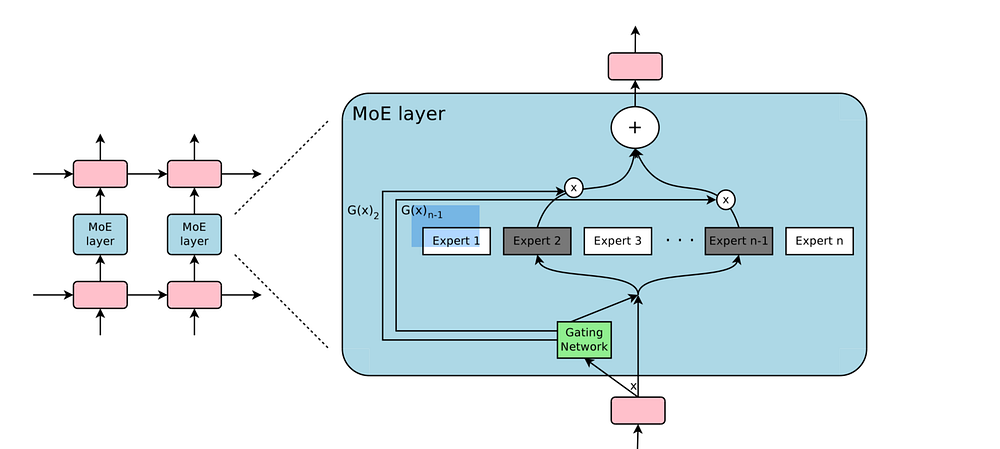
This repository contains the PyTorch re-implementation of the sparsely-gated MoE layer described in the paper Outrageously Large Neural Networks for PyTorch.
from moe import MoE
import torch
# instantiate the MoE layer
model = MoE(input_size=1000, num_classes=20, num_experts=10,hidden_size=66, k= 4, noisy_gating=True)
X = torch.rand(32, 1000)
#train
model.train()
# forward
y_hat, aux_loss = model(X)
# evaluation
model.eval()
y_hat, aux_loss = model(X)This example was tested using torch v1.0.0 and Python v3.6.1 on CPU.
To install the requirements run:
pip install -r requirements.py
The file example.py contains an minimal working example illustrating how to train and evaluate the MoE layer with dummy inputs and targets. To run the example:
python example.py
The file cifar10_example.py contains a minimal working example of the CIFAR 10 dataset. It achieves an accuracy of 39% with arbitrary hyper-parameters and not fully converged. To run the example:
python cifar10_example.py
FastMoE: A Fast Mixture-of-Expert Training System This implementation was used as a reference PyTorch implementation for single-GPU training.
The code is based on the TensorFlow implementation that can be found here.
@misc{rau2019moe,
title={Sparsely-gated Mixture-of-Experts PyTorch implementation},
author={Rau, David},
journal={https://github.com/davidmrau/mixture-of-experts},
year={2019}
}