A PyTorch implementation of the attention-based Policy Gradient RL for learning to solve Travelling Salesperson Problem based on the paper https://doi.org/10.1007/978-3-319-93031-2_12
This project is the PyTorch implementation of the attention-based policy gradient for solving TSP based on the paper Learning Heuristics for the TSP by Policy Gradient [PDF here]
The paper also incorporates a 2-opt heuristic to the RL algorithm, which we did not include here. Please refer to the paper for a more detailed explanation of the methodology.
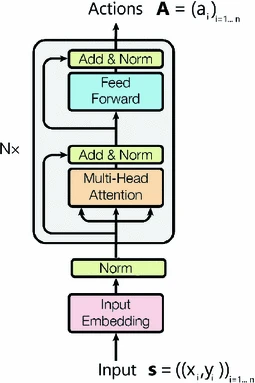
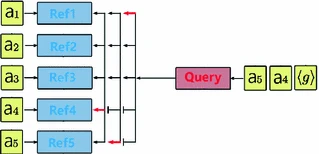
The agent is trained using the REINFORCE (policy gradient) algorithm. refer to the REINFORCE original paper.