FHIR Works on AWS is a framework to deploy a FHIR server on AWS. This package is an example implementation of this framework. The power of this framework is being able to customize and add in additional FHIR functionality for your unique use-case. An example of this, is this implementation uses DynamoDB. Say you don't want to use DynamoDB, you could implement your own persistence component and plug it into your deployment package. With FHIR Works on AWS you control how your FHIR server will work!
This deployment implementation utilizes Lambda, DynamoDB, S3 and Elasticsearch to provide these FHIR capabilities:
- CRUD operations for all R4 or STU3 base FHIR resources
- Search capabilities per resource type
- Ability to do versioned reads (vread)
- Ability to post a transaction bundle of 25 entries or less
Do you want to just try it out? Please follow the instructions below:
Clone or download the repository to a local directory. Note: if you intend to modify FHIR Works on AWS you may wish to create your own fork of the GitHub repo and work from that. This allows you to check in any changes you make to your private copy of the solution.
Git Clone example:
git clone https://github.com/awslabs/fhir-works-on-aws-deployment.gitInstructions for making local code changes
The system architecture consists of multiple layers of AWS serverless services. The endpoint is hosted using API Gateway. The database and storage layer consists of Amazon DynamoDB and S3, with Elasticsearch as the search index for the data written to DynamoDB. The endpoint is secured by API keys and Cognito for user-level authentication and user-group authorization. The diagram below shows the FHIR server’s system architecture components and how they are related.

FHIR Works on AWS is powered by many singly functioned components. We built it this way to give customers the flexibility to plug in their own implementations if needed. The components used in this deployment are:
- Interface - Responsible for defining the communication between all the other components
- Routing - Responsible for taking an HTTP FHIR request and routing it to the other component, catching all thrown errors, transforming output to HTTP responses and generating the Capability Statement
- Authorization - Responsible for taking the access token found in the HTTP header and the action the request is trying to perform and determine if that is allowed or not
- Persistence - Responsible for all CRUD interactions. FHIR also supports ‘conditional’ CRUD actions and patching
- Bundle - Responsible for supporting many requests coming in as one request. Think of someone wanting to create 5 patients at once instead of 5 individual calls. There are two types of Bundles: batch & transaction
- Search - Responsible for both system-wide searching (/?name=bob) and type searching (/Patient/?name=bob)
- History - NOT IMPLEMENTED Responsible for searching all archived/older versioned resources. This can be done at a system, type or instance level.
This project is licensed under the Apache-2.0 License.
After installation, all user-specific variables (such as USER_POOL_APP_CLIENT_ID) can be found in the INFO_OUTPUT.yml file. You can also retrieve these values by running serverless info --verbose --region <REGION> --stage <STAGE>. NOTE: default stage is dev and region is us-west-2.
If you are receiving Error: EACCES: permission denied when executing a command, try re-running the command with sudo.
The FHIR API can be accessed through the API_URL using REST syntax as defined by FHIR here
using this command
curl -H "Accept: application/json" -H "Authorization:<COGNITO_AUTH_TOKEN>" -H "x-api-key:<API_KEY>" <API_URL>Other means of accessing the API are valid as well, such as Postman. More details for using Postman are detailed below in the Using Postman to make API Requests section.
Postman is an API Client for RESTful services that can run on your development desktop for making requests to the FHIR Server. Postman is highly suggested and will make accessing the FHRI API much easier.
Included in this code package, under the folder “postman”, are JSON definitions for some requests that you can make against the server. To import these requests into your Postman application, you can follow the directions here. Be sure to import the collection file.
After you import the collection, you need to set up your environment. You can set up a local environment, a dev environment, and a prod environment. Each environment should have the correct values configured for it. For example the API_URL for the local environment might be localhost:3000 while the API_URL for the dev environment would be your API Gateway’s endpoint.
Instructions for importing the environment JSON is located here. The three environment files are:
- Fhir_Local_Env.json
- Fhir_Dev_Env.json
- Fhir_Prod_Env.json
The variables required in the POSTMAN collection can be found in Info_Output.yml or by running serverless info --verbose
API_URL: from Service Information:endpoints: ANY
API_KEY: from Service Information: api keys: developer-key
CLIENT_ID: from Stack Outputs: UserPoolAppClientId
AUTH_URL: https://<CLIENT_ID>.auth.<REGION>.amazoncognito.com/oauth2/authorize,
To know what all this FHIR API supports please use the GET Metadata postman to generate a Capability Statement.
FHIR Works on AWS solution uses role based access control (RBAC) to determine what operations and what resource types the requesting user has access too. The default ruleset can be found here: RBACRules.ts. For users to access the API they must use an OAuth access token. This access token must include scopes of either:
openid profileMust have bothaws.cognito.signin.user.admin
Using either of the above scopes will include the user groups in the access token.
In order to access the FHIR API, an ACCESS_TOKEN is required. This can be obtained following the below steps within postman:
- Open postman and click on the operation you wish to make (i.e.
GET Patient) - In the main screen click on the
Authorizationtab - Click
Get New Access Token - A sign in page should pop up where you should put in your username and password (if you don't know it look at the init-auth.py script)
- Once signed in the access token will be set and you will have access for ~1 hour
A Cognito OAuth access token can be obtained using the following command substituting all variables with their values from INFO_OUTPUT.yml or the previously mentioned serverless info --verbose command.
For Windows:
scripts/init-auth.py <CLIENT_ID> <REGION>For Mac:
python3 scripts/init-auth.py <CLIENT_ID> <REGION>The return value is an ACCESS_TOKEN that can be used to hit the FHIR API without going through the Oauth Sign In page. In POSTMAN, instead of clicking the Get New Access Token button, you can paste the ACCESS_TOKEN value into the Available Tokens text field.
Binary resources are FHIR resources that consist of binary/unstructured data of any kind. This could be X-rays, PDF, video or other files. This implementation of the FHIR API has a dependency on the API Gateway and Lambda services, which currently have limitations in request/response sizes of 10MB and 6MB respectively. This size limitation forced us to look for a workaround. The workaround is a hybrid approach of storing a Binary resource’s metadata in DynamoDB and using S3's get/putPreSignedUrl APIs. So in your requests to the FHIR API you will store/get the Binary's metadata from DynamoDB and in the response object it will also contain a pre-signed S3 URL, which should be used to interact directly with the Binary file.
Bulk Export allows you to export all of your data from DDB to S3. We currently only support System Level export. For more information about Bulk Export, please refer to this implementation guide.
The easiest way to test this feature on FHIR Works on AWS is to make API requests using the provided Fhir.postman_collection.json.
- In the collection, under the "Export" folder, use
GET System Exportrequest to initiate an Export request. - In the response, check the header field
Content-Locationfor a URL. The url should be in the format<base-url>/$export/<jobId>. - To get the status of the export job, in the "Export" folder used the
GET System Job Statusrequest. That request will ask for thejobIdvalue from step 2. - Check the response that is returned from
GET System Job Status. If the job is in progress you will see a header with the fieldx-progress: in-progress. Keep polling that URL until the job is complete. Once the job is complete you'll get a JSON body with presigned S3 URLs of your exported data. You can download the exported data using those URLs.
Note: To cancel an export job that is in progress, you can use the Cancel Export Job request in the "Export" folder in POSTMAN collections.
To test we suggest you to use Postman, please see here for steps.
To test this with cURL, use the following command:
- POST a Binary resource to FHIR API:
curl -H "Accept: application/json" -H "Authorization:<COGNITO_AUTH_TOKEN>" -H "x-api-key:<API_KEY>" --request POST \
--data '{"resourceType": "Binary", "contentType": "image/jpeg"}' \
<API_URL>/Binary- Check the POST's response. There will be a
presignedPutUrlparameter. Use that pre-signed url to upload your file. See below for command
curl -v -T "<LOCATION_OF_FILE_TO_UPLOAD>" "<PRESIGNED_PUT_URL>"-
If changes are required for the Elasticsearch instances you may have to do a replacement deployment. Meaning that it will blow away your Elasticsearch cluster and build you a new one. The trouble with that is the data inside is also blown away. In future iterations we will create a one-off lambda that can retrieve the data from DynamoDB to Elasticsearch. A couple of options to work through this currently are:
- You can manually redrive the DynamoDB data to Elasticsearch by creating a lambda
- You can refresh your DynamoDB table with a back-up
- You can remove all data from the DynamoDB table and that will create parity between Elasticsearch and DynamoDB
-
Support for STU3 and R4 releases of FHIR is based on the JSON schema provided by HL7. The schema for R4 is more restrictive than the schema for STU3. The STU3 schema doesn’t restrict appending additional fields into the POST/PUT requests of a resource, whereas the R4 schema has a strict definition of what is permitted in the request.
-
When making a POST/PUT request to the server, if you get an error that includes the text
Failed to parse request body as JSON resource, check that you've set the request headers correctly. The header forContent-Typeshould be eitherapplication/jsonorapplication/fhir+jsonIf you're using Postman for making requests, in theBodytab, be sure to also set the setting torawandJSON.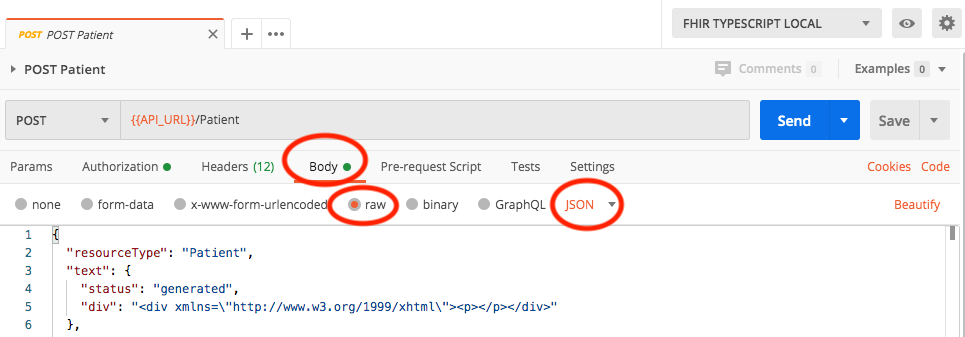

We'd love to hear from you! Please reach out to our team: fhir-works-on-aws-dev for any feedback.