VictorianLit Dataset for Deep Learning-Based Sentiment Analysis of Victorian Literary Texts | by Hoyeol Kim
Download: VictorianLit (Kaggle)
https://elibooklover.github.io/VictorianLit/VictorianLit.csv
Here is example code for loading the VictorianLit dataset:
df=pd.read_csv('https://elibooklover.github.io/VictorianLit/VictorianLit.csv')
df.head()
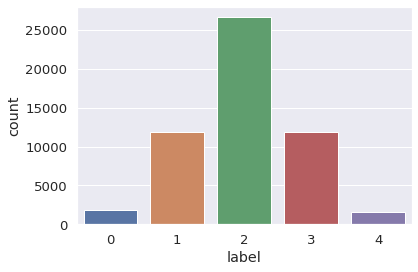
There are two columns: sentences and label. The VictorianLit dataset has five labels based on sentiment: 0 (very negative), 1 (negative), 2 (neutral), 3 (positive), 4 (very positive).
The VictorianLit dataset, which has 53,826 rows and 2 columns, consists of five different novels from the Victorian era: Charles Dickens' Little Dorrit and Oliver Twist, Elizabeth Gaskell's North and South, George Eliot's Adam Bede, and Mary Elizabeth Braddon's Lady Audley's Secret. The maximum sentence length of the VictorianLit dataset is 372.
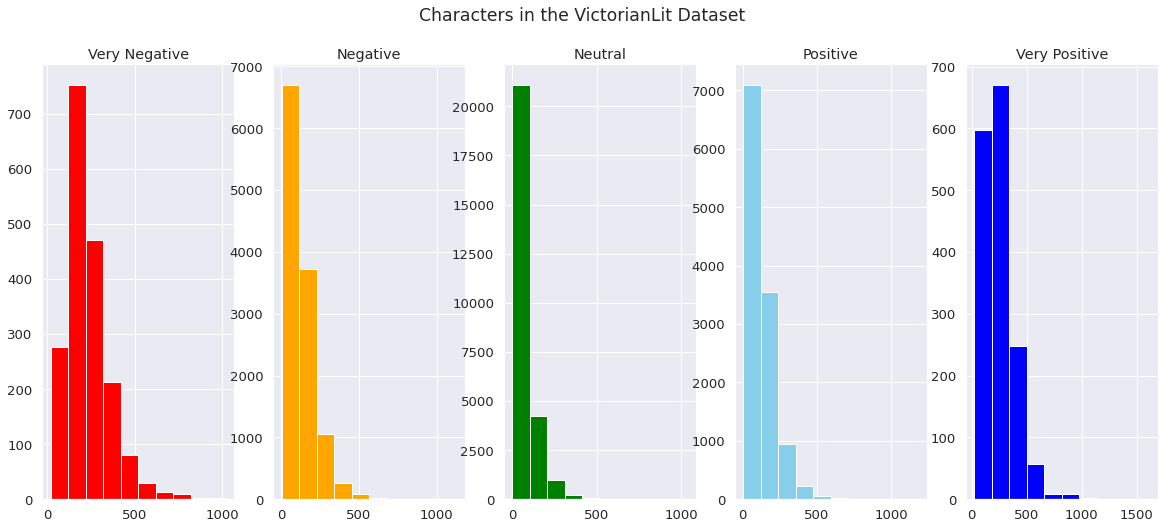
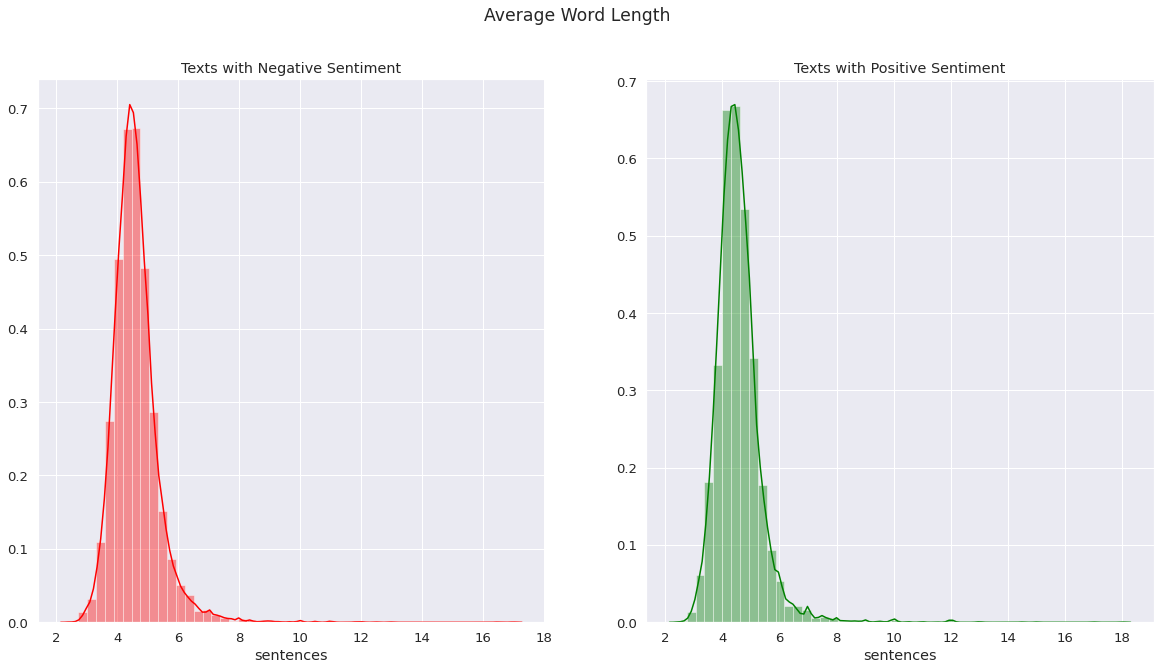
The VictorianLit dataset was tested with the BERT-Base model released by Google Research. The BERT-Base, Uncased model (12-layer, 768-hidden, 12-heads, 100M parameters) was run with the VictorianLit dataset in order to validate the dataset.
For fine-tuning BERT for sentiment analysis, the following hyperparameters and training environments were set:
- tokenizer: BertTokenizer
- max_sequence_length: 400
- batch_size: 16
- model_name: BERT-base, Uncased (12-layer, 768-hidden, 12-heads, 110M parameters)
- learning_rate: 1e-5
- epochs: 4
- GPU: Tesla T4
The accuracy is 93%, and the average training loss is 0.12. If the batch_size was larger, the accuracy would be higher. If your GPU ram is enough to cover the large batch_size, I recommend you set the batch_size to 64 or 128.
The VictorianLit dataset will be continuously updated, added upon, and tested. Please feel free to provide any feedback or suggest sentiment value changes with supporting statements.
Please use the following reference to cite the dataset:
@phdthesis{Kim2022,
author = {Hoyeol Kim},
title = {Computational Approaches in the Humanities: from Sentiment Analysis to Deep Learning Colorization},
school = {Texas A&M University},
year = {2022},
note = {Chapter 4: Dickensian Sentiment and Sentiment Analysis of Victorian Novels}
}
or
Kim, Hoyeol. Computational Approaches in the Humanities: from Sentiment Analysis to Deep Learning Colorization. 2022. Texas A&M University, PhD dissertation. Chapter 4: "Dickensian Sentiment and Sentiment Analysis of Victorian Novels."
