- доработать модель на слое stg с учетом эндпойнтов для получения информации о структурных подразделениях и статусах, а также с учетом json'ов c учебными планами;
- доработать модель на stg с учетом SCD2;
- доработать скрипт из dag'а get_data для сбора данных по всем эндпойнтам;
- доработать модель данных для слоя dds, учивающую все необходимые поля для построения дэшборда;
- создать скрипт для переноса данных из stg на dds;
- спроектировать модель для cdm (слой витрин);
- подключить Metabase к модели на слое cdm (при первом подключении нужно зарегистрироваться, хост:порт de-pg-cr-af:5432);
- сформировать дэшборд в соответствии с требованиями.
Требования:
- доля учебных планов в статусе "одобрено" (только для 2023 года)
- доля/количество учебных планов с некорректной трудоемкостью (корректная трудоемкость у бакалавров - 240, а магистров - 120)
- доля заполненных аннотаций в динамике
- долю дисциплин в статусе "одобрено" в динамике
В разрезах:
- ОП (с учетом года)
- структурных подразделений для дисциплин
- уровней образования (бакалавр, специалист, магистр)
- структурных подразделений для ОП
- учебного года (текущий и следующий)
- Создаются таблицы слоя stg. (скрипт stg_dll.sql) Таблицы этого слоя хранят сырые данные.
- Раз в какое-то время данные берутся с разных API и добавляются в таблицы слоя stg. При этом данные не обрабатываются (вложенные в список объекты Json не разбираются)
- Создаются таблицы слоя dds. (скрипт dds_dll.sql)
- Нужные для логики витрин поля извлекаются из таблиц stg, преобразуются, структурируются и добавляются в таблицы на слой dds.
- Наконец, слой cdm предоставляет готовые для анализа данные, которые могут быть использованы для создания отчетов, дашбордов и другой бизнес-аналитики.
- Структурные подразделения (факультеты) реализуют дисциплины.
- У каждой дисциплины есть код и редакторы, статус и аннотации.
- На каждом направлении (“Мобильные и облачные технологии”) есть дисциплины, год набора на направление, трудоемкость программы и уровень образования.
-
Создал виртуальное окружение через poetry (команда poetry init)
-
Добавил пакеты pandas, airflow-apache, apache-airflow-providers-postgres (poetry add …)
-
Запустил собрал и запустил контейнеры ‘docker compose up -d’
-
Подключился к БД через DBeaver (пароль jovyan):

-
Зарегистрировался на op.itmo.ru (логин: asdfg, пароль: itmo2023)
-
Зашел в Airflow по localhost:3000/airflow (логин: AirflowAdmin, пароль: airflow_pass)
-
Вписал переменные в Airflow (Admin -> Variables):

-
Добавил соединение к БД (Admin -> Connections):

-
Запустил скрипт stg_dll.sql через DBeaver (создались таблицы для сырых данных)
-
Запустил даг get_data, убедился что данные появились в таблице stg.work_programs



Использовалось расширение Thunder Client.
Токен брался из куков op.itmo.ru (csrftoken)


Структурные подразделения (факультеты) и дисциплины, которые они реализуют (SCD0)
endpoint 1: https://op.itmo.ru/api/record/structural/workprogram
disc_list:
{
"id": 17969,
"title": "Название дисциплины",
"discipline_code": "21201",
"editors": [
{
"id": 1277,
"username": "313131",
"first_name": "Иван",
"last_name": "Иванов",
"email": "example@gmail.com",
"isu_number": "313131"
}
]
}
Показывает какие дисциплины есть на направлении
- из направления берется год набора
- из дисциплин берется статус (его динамику надо отслеживать)
endpoint 2: https://op.itmo.ru/api/record/academic_plan/academic_wp_description/all
dir_list: в каждом таком списке только одно направление
[
{
"id": 6859,
"ap_isu_id": 10572,
"year": 2018,
"title": "Нанофотоника и квантовая оптика"
}
]
disc_list:
[
{
"id": 2623,
"discipline_code": "5546",
"title": "История",
"description": null,
"status": "WK"
},
{
"id": 2625,
"discipline_code": "5664",
"title": "Физическая культура",
"description": null,
"status": "WK"
}
]
Образовательная программа и направления
- берется статус и трудоёмкость образовательной программы (их динамика отслеживается)
- из направления возьмется год набора и уровень образования
endpoint 4: https://op.itmo.ru/api/academicplan/detail/{op_id}?format=json
dir_list:
[
{
"id": 6859,
"year": 2018,
"qualification": "bachelor",
"title": "Нанофотоника и квантовая оптика",
"field_of_study": [
{
"number": "16.03.01",
"id": 15772,
"title": "Техническая физика",
"qualification": "bachelor",
"educational_profile": null,
"faculty": null
}
],
"plan_type": "base",
"training_period": 0,
"structural_unit": null,
"total_intensity": 0,
"military_department": false,
"university_partner": [],
"editors": []
}
]

- my_up (для требования 1 и 2)
- disc (для требования 3 и 4)
- остальные таблицы используются для просмотра данных в разрезах
На примере с отслеживаем изменений трудоёмкости и статусов в учебных планах:
Перед тем как добавиться в таблицу stg.op_dir каждый новый датафрейм проверяется на новизну:
# Проверяем, существует ли запись с такими же данными
existing_data = postgres_hook.get_pandas_df(
sql.SQL('''
WITH t AS (
SELECT *
FROM stg.op_dir
WHERE constr_id = {}
ORDER BY update_ts DESC
LIMIT 1
)
SELECT *
FROM t
WHERE constr_id = {}
AND labor = {}
AND status = {}
AND dir_list = {}
''')
.format(
sql.Literal(df['constr_id'][0])
,sql.Literal(df['constr_id'][0])
,sql.Literal(df['labor'][0])
,sql.Literal(df['status'][0])
,sql.Literal(df['dir_list'][0])
)
)
if existing_data.empty:
postgres_hook.insert_rows("stg.op_dir", df.values, target_fields=target_fields)
logging.info(f"Added constr_id={df['constr_id'][0]}")Аналогично, для добавления на слой dds, выполняется проверка, есть ли уже в таблице этот рабочий план с такими же значениями:
def my_up():
PostgresHook(postgres_conn_id="PG_WAREHOUSE_CONNECTION").run(
"""
-- берет только последнюю по времени запись для каждого constr_id (при условии что rn = 1)
WITH NewRecords AS (
SELECT
id,
constr_id,
isu_id,
status,
labor,
(json_array_elements(dir_list::JSON)->>'year')::integer AS year,
json_array_elements(dir_list::JSON)->>'qualification' AS qualification,
update_ts,
ROW_NUMBER() OVER (PARTITION BY constr_id ORDER BY update_ts DESC) AS rn
FROM stg.op_dir
)
INSERT INTO dds.my_up (
constr_id,
isu_id,
status,
labor,
year,
qualification,
update_ts
)
SELECT
nr.constr_id,
nr.isu_id,
nr.status,
nr.labor,
nr.year,
nr.qualification,
nr.update_ts
FROM NewRecords nr
LEFT JOIN dds.my_up mu ON mu.constr_id = nr.constr_id
WHERE
nr.rn = 1
AND (
mu.constr_id IS NULL
OR mu.status != nr.status
OR mu.labor != nr.labor
)
"""
)-
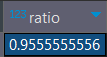
Доля учебных планов в статусе одобрено для 2023 года:
with t as( SELECT COUNT(*) AS total_2023, SUM(CASE WHEN status = 'verified' THEN 1 ELSE 0 END) AS verified_2023 FROM dds.my_up WHERE year = 2023 ) select cast(verified_2023 as numeric) / total_2023 as ratio from t
-
Доля/количество учебных планов с некорректной трудоемкостью (только для 2023 года, корректная трудоемкость у бакалавров - 240, а магистров - 120):
WITH t AS ( SELECT COUNT(*) AS total_2023, SUM( CASE WHEN ( (qualification = 'bachelor' AND labor != 240) OR (qualification = 'master' AND labor != 120) ) THEN 1 ELSE 0 END ) AS incorrect_laboriousness_2023 FROM dds.my_up WHERE year = 2023 ) SELECT total_2023 ,incorrect_laboriousness_2023 AS incorrect ,CAST(incorrect_laboriousness_2023 AS numeric) / total_2023 AS ratio FROM t;

-
Также, с помощью поля update_ts, на слое cdm можно будет отслеживать динамику статусов и трудоёмкости учебных планов. Проверка выполнялась путем изменения значений статусов и трудоемкости на слое stg.


Аналогично для статусов и аннотаций дисциплин.



