Status update for all.
-
What are you working on?
-
What have you done so far? Did you meet your expectations for this week yet?
-
What do you hope to accomplish by next week? How? (Who’s doing what, if this is a team?)
-
What do you need to move forward?
Status update for all.
-
Who are you working with, if anybody?
-
What are you working on?
-
What have you done so far?
-
What do you hope to accomplish by next week? How? (Who’s doing what, if this is a team?)
-
What do you need to move forward?
|
Warning
|
The commuter rail train was delayed over an hour this morning. Sorry 8am section! To make it up to you, have a free small slurpee at 7-11 today! |
Ah memory management. Regardless of how it happens, it must happen, unless you like leaking memory.
It helps to remember modern computer systems give us three kinds of memory:
-
Static memory
-
Stack memory
-
Heap memory
Static memory is pretty straighforward: it’s a chunk of memory that comes and goes with the program itself, and thus does not grow or shrink over the lifetime of the program. Stack memory is managed using, ahem, a stack. (Who’da thunk it?)
When we think of memory management, we’re almost certainly thinking about the heap: dynamically-allocated memory from the operating system with no pre-set lifespan. Therefore, either the programmer has to specify when the memory is no longer needed, or we can rely on garbage collector to clean up after our mess.
Garbage collection algorithms must know the difference between pointer and an integer. This is why C doesn’t have it. Just kidding, you can do garbage collection in C, but it must be conservative: it can’t make guarantees that it collected all the garbage.
- Strategy
-
Just count how many things point to this object, and when that count drops to 0, free the object.
- Pros
-
-
Simple to implement
-
Reasonably fast
-
Reasonably good (if Python uses it, it must be somewhat good)
-
- Cons
-
-
Now, every object has to have an extra integer just for the reference count.
-
What happens when you got two objects pointing to each other (like in a circular linked list)? Crap! The reference count never drops to zero, that’s what!
-
There’s many variations of tracing (mark-sweep) garbage collection.
- Strategy
-
-
Maintain a root set (a set of objects reachable throughout the program and in the current scope of the program).
-
Traverse (trace) the object graph starting from the root set, looking for garbage (objects unreachable from the root set)
-
- Pros
-
-
This can deal properly with all garbage, including circular linked lists that nobody else references
-
No space overhead of reference counts
-
- Cons
-
-
Naive implementations are slow, and briefly hang programs
-
Not what you’d use when precise timing is important (e.g., launching a rocket, autonomous cars)
-
Essentially, this algorithm is what gave garbage collection its bad reputation
-
- Naive mark sweep
-
Tracing garbage collection that runs when we’re out of memory, and stops the program during garbage collection.
- Concurrent/incremental mark sweep
-
The program still runs during GC (which happens in a separate thread), but marked objects are locked as necessary.
- Generational
-
Most objects on the heap are short-lived: they’re dynamically allocated and freed almost right away. Other objects, fewer in number, live long, productive and happy lives. This form of GC moves reachable objects between two or more memory pools called generations, without touching garbage.
|
Note
|
Good compilers will optimize away as much heap allocation as possible using escape analysis, checking at compile time to see if an object could be referenced outside a function. If not, allocate on the stack. |
From July 15 through August 5, we will use lab time to update each other on our progress.
During each lab period, each team should have answers to these questions.
-
What did you do? (Nothing isn’t a good answer to that question)
-
Did you achieve what you set out to achieve from the prior week?
-
What are you struggling with or what obstacles do you face?
-
What do you plan to achieve by next week?
SSA is a transformation on code that is a prerequisite for many low-level optimizations, such as dead/duplicate code elimination. Think of it like version control for variables. Each variable gets a new version number when an assignment is made, hence single assignment. If we have multiple branches (i.e., loops or conditionals), we need to merge different variable versions together (denoted by the phi function).
Pseudocode |
SSA form |
Basic block: a = 5 a = a + 10 print a |
SSA Basic block: a_0 = 5 a_1 = a_0 + 10 print a_1 |
Conditional a = 5
if (a < 10) {
a++
} else {
a--
}
a = a * 2
print a
|
SSA conditional a_0 = 5
if (a_0 < 10) {
a_1 = a_0 + 1
} else {
a_2 = a_0 - 1
}
a_3 = phi(a_1,a_2) * 2
print a_3
|
Informally, I’d like to know your end-goal and the steps you’ll need to get there.
-
Figure out what it is that you want to do.
-
Either create or fork an existing repository for said thing.
-
Flesh out the things you and your team expect to implement (your goals) in your project’s README file somewhere.
-
Describe your team on your Team page.
-
Use the issue tracker to assign tasks to folks on your team.
Hint: Please don’t start from scratch if possible. Try to leverage something that already exists, because it’ll be more impressive in the end. If you insist on working from scratch, please study something that already exists so that you can distinguish what you’re doing from what has already been done.
-
Also, for the folks interested in using clang, here’s a clang-project.
Off-site meeting
-
8am: Starbucks 283 Longwood Ave, Boston, MA 02115
-
10am:
-
1pm: J.P. Licks Mission Hill 1618 Tremont St Boston, MA 02120
Perform static analysis of Java code.
-
Fork and clone jdt-project.
-
Next, add JAVA_HOME to your environment variables:
Windows: Search for "environment variables" and click 'Edit the system environment variables'. Click 'Environment Variables…' → 'New…'
Variable name: JAVA_HOME
Variable value: C:\Program Files\Java\jdk1.8.0_05 (or whatever version you’re using)
-
Click OK, OK, OK.
Close and reopen Git Bash. If you get the same error, try turning it off and on again
-
Import the project into eclipse.
./gradlew eclipse
'File' → 'Import' → 'General' → 'Existing projects into workspace'
-
Read through the code. Open Main and run it. Nothing will happen. You’ll need to supply the root folder of a Java project to main.
Go to 'Run Configurations' → 'Main' → 'Arguments' → 'Program arguments'. Enter the path to a Java project. Click 'Run'. If you have no other Java projects, you can supply the source of jdt-project to itself. Huzzah!
-
Modify AstVisitor to do one of the following (pick one):
-
Generate UML class diagram for source code (Show members of classes) See this for insipration
-
Generate a graph of class dependencies (Type uses Types) See this for inspiration
-
Generate a graph of package dependencies (Package uses Packages)
-
Generate a graph of method dependencies (Method uses Methods)
-
Generate a graph of class inheritance / interface implementation
-
Suggest some other graph-related static analysis
-
Also, let’s get teams formed for our final project.
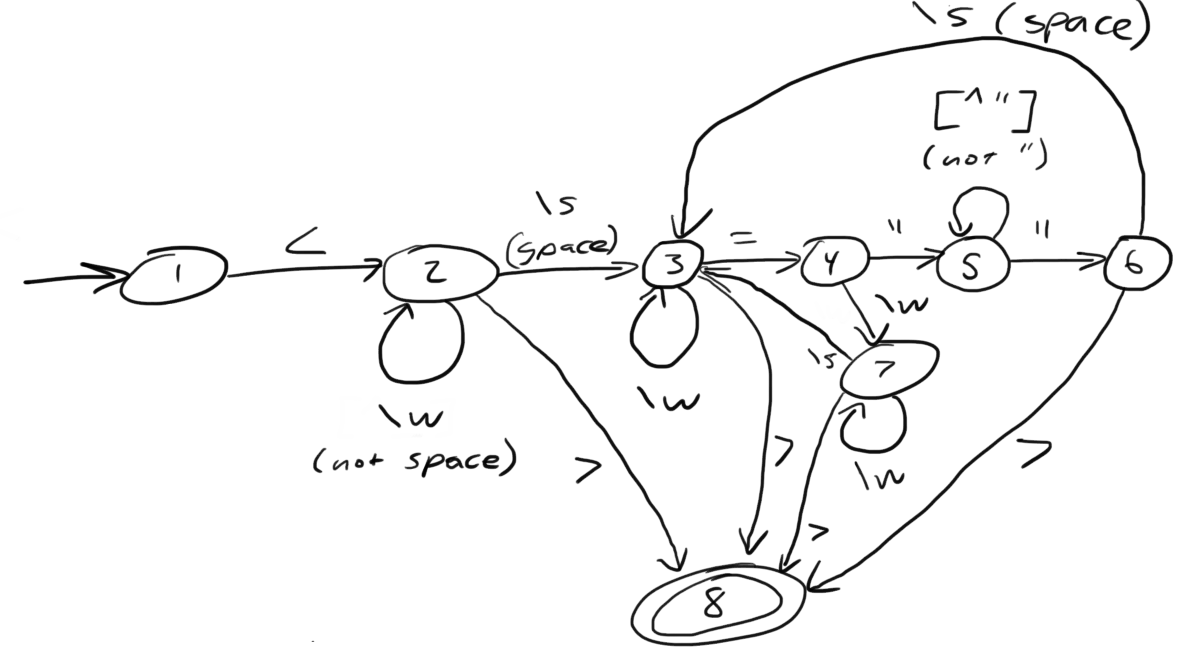 .
.
-
What does it appear that this state machine is matching?
HTML start tags (well, that’s what I was going for anyway in the 10 minutes it took to draw this)
-
What regular expression matches the langauge this state machine accepts?
Hmm
-
What is the derivative of that regex, with respect to the letter m?
The empty set, because the automaton does not match m at the start.
-
What is the derivative of your original regex, with respect to the letter <?
Hmm
-
Is this state machine deterministic or nondeterministic? Why?
It’s deterministic, because there’s no epsilon transitions or choices about where to go next.
 .
.
-
Choose among: context-free, context-sensitive, LL(k), LR(k), Recursively-enumerable, Regular.
-
Match the automaton/parsing strategy with the language. Choose among: finite automaton, linear-bounded Turing machine, pushdown automaton, recursive descent, shift-reduce, Turing machine.
From outside to inside:
-
Recursively-enumerable (Turing machine)
-
Context-sensitive (Linear bounded Turing machine)
-
Context-free (Pushdown automaton)
-
LR(k) (Shift-reduce)
-
LL(k) (Recursive descent)
-
Regular (Finite automaton)
 .
.
-
Give an example string that this grammar recognizes.
See below, derp!
-
Is this language LL(k)? Why or why not?
No, it’s not LL(k), because it has left recursion in it (see: StmtList → StmtList).
-
Is this language LR(k)? Why or why not?
Yes, because there’s some shift-reduce question coming up later. It’s non-ambiguous.
-
Is this language context-free? Why or why not?
Yes, because the left side of all production rules are nonterminals, and the right side are sequences of terminals or nonterminals.
-
Is this language regular? Why or why not?
No, because it has recursion in it. Grammars for regular languages must consist of a nonterminal deriving a sequence of terminals, optionally followed by only one nonterminal at the end.
-
Is this language context-sensitive? Why or why not?
Yes, because it’s context-free, and context-sensitive languages have fewer restrictions on their grammar.
-
What is First(Block)?
begin
-
What is Follow(Expr)?
end, ;, ], \+ )
-
Show the shift-reduce steps for the the following string:
begin x = 5; y = x end
Steps
-
shift begin
-
shift x
-
reduce x to Id
-
reduce Id to Var
-
shift =
-
shift 5
-
reduce 5 to T
-
reduce T to Expr
-
reduce Var = Expr to Stmt
-
reduce Stmt to StmtList
-
shift ;
-
shift y
-
reduce y to Id
-
reduce Id to Var
-
shift =
-
shift x
-
reduce x to Id
-
reduce Id to Var
-
reduce Var to T
-
reduce T to Expr
-
reduce Var = Expr to Stmt
-
reduce StmtList; Stmt to StmtList
-
shift end
-
reduce begin StmtList end to Block
-
reduce Block to Prog
Chat with me if you’re working on something else.
Also, don’t forget to clone it!
Challenge Here’s an old midterm for practice purposes. How much can you answer without your peripheral brain?
|
Note
|
The real midterm consists of extremely short answers (not sentences), with similar content. |
Optimize your compiler and interpreter developed in Lab 3.
-
Modify CommandNode so that it includes a counter (presumably an int or the like).
-
Modify the parser a bit so that it only emits a command node after it has encountered a full run of the same command. (e.g., ----- becomes CommandNode(\'-', 5))
-
Modify the interpreter and compiler accordingly.
In short: do an optimization that performs run-length encoding on Brainfuck code.
A map among identifiers, scopes and other information (e.g., its type, where it’s defined).
-
In an interpreter, these can be used for data storage.
-
In a compiler, these are used to generate code.
Traditional approaches to parsing:
-
Hand-written parsers (tedious, error-prone)
-
Parser generator (tedious, steep learning curve)
Explain parser combinators through code.
This is a two-parter, building upon Lab 2.
-
Compile Brainfuck to a language of your choice. Copypasta the Printer visitor class into, say, CCompiler or JavaCompiler. It should just print out equivalent C or Java or whatever source code.
-
Interpret the abstract syntax tree (AST) by writing a Interpreter visitor that just executes commands based on the tree structure.
You can tell if your compiler is working if you can take the source code it generated and pass that on to the compiler for the language you’re targeting.
You can tell if your interpreter is working if the program prints Hello, world given src/helloworld.bf. Don’t forget to zero out the array! (In C, use memset)
For our project, we’ll begin after we’re done with our common labs (there aren’t many left). You’re welcome to work with as few or as many people as you wish either in this section or others. Start thinking about which of these you’d like to do, or suggest new ideas.
You’re welcome to pursue these traditional project ideas:
These ideas are also welcome:
-
A parser combinator library to target multiple parsing strategies (derivative, shift-reduce, or recursive descent parsing).
These projects build upon tools like clang (for C/C++), JDT (for Java), Python’s ast module to do work:
-
Automated refactoring tool for existing languages to serve education and large projects
-
Search engine for identifiers and literals in code that makes good recommendations, (e.g., PageRank)
-
Something like Quickcheck, but can generate characterization tests automatically and efficiently.
LR(k) means Left to right, Rightmost derivation, with k tokens of lookahead.
LR(k) grammars are a subset of the context-free grammars, and a proper superset of the LL(k) grammars (the LL(k) grammars are a proper subset of the LR(k) grammars). For a grammar to be LR(k):
-
It must be unambiguous
LR(k) grammars can be parsed using 'shift-reduce'.
Shift-reduce parsing is also known as bottom up parsing, because the parser works from the terminals up to the starting nonterminal. A shift-reduce parser shifts terminals onto a stack, and reduces the stack to a nonterminal when the stack matches the right hand side of a production (rule). Programmers rarely write shift-reduce parsers by hand, and use parser generators instead.
Go ahead and pull from me:
cd COMP603-2014 git pull upstream master
Do you have Visual Studio or GCC installed?
Write a recursive descent parser for Brainfuck.
See src/brainfuck.cpp for a starting point. It makes use of the Visitor design pattern. If your C++ is rusty, check out the C++ Reference. To see an example of how to do recursive descent parsing, check out src/RecursiveDescent.java.
The Printer traverses the tree the parser built and prints out the equivalent Brainfuck code. Therefore, you can tell if your program is working if the Printer produces the exact same program as what your parser read in.
To parse, you can’t avoid using some form of recursion or a Node stack. Your options:
-
Use mutually recursive functions that stuff child nodes into programs or loops
-
Maintain an explicit stack of nodes inside the existing parse function
-
Use an implicit stack by modifying Node to include a pointer to a parent Node
Answer in a file called warmup.txt
-
What does it mean for two sets to be disjoint?
-
What is the union of two sets?
- First set
-
the set of terminals that can appear first in any derivation of a nonterminal.
- Follow set
-
the set of terminals that can appear first after derivation of a nonterminal.
See the scribbles (from page 148 of the textbook).
LL(k) means parse from Left to right, Leftmost derivation, with at most k tokens of lookahead.
LL(k) grammars are a subset of the context-free grammars. For a grammar to be LL(k):
-
The first and follow sets for each nonterminal must be disjoint
-
It must be unambiguous
-
No left-recursion is allowed
-
No common prefixes on the right hand side are allowed
LL(k) grammars can be parsed using 'recursive descent'.
Recursive descent parsing is also known as top-down parsing, because the parse starts from the starting nonterminal. Each nonterminal is a function, and the first and follow sets determine which production (rule) to choose. See src/RecursiveDescent.java for an example recursive descent parser.
Grammars consist of:
-
a finite set of derivation rules (productions)
-
a finite set of nonterminals (variables)
-
a finite set of terminals (literals)
-
a starting nonterminal
Chomsky recognized that the restrictions placed on the form of derivation rules implies what category of language the grammar can recognize or generate.
|
Note
|
We will focus primarily on two subsets of context-free grammars, LL and LR grammars, since they have efficient parsing algorithms. |
| Chomsky hierarchy | Description | Equivalent automaton |
|---|---|---|
Unrestricted |
Arbitrary sequences of terminals and non-terminals can derive arbitrary sequences of terminals and nonterminals. |
Turing machine (finite state machine with an infinite tape having a read/write head) |
Context-sensitive |
A nonterminal flanked on either side by terminals and nonterminals (the context) derives a nonempty string of terminals or nonterminals surrounded by the same context. |
Turing machine with finite tape (finite state machine with a finite tape having a read/write head) |
Context-free |
Nonterminals derive sequences of terminals and nonterminals. |
Pushdown automaton (finite state machine with a stack) |
Regular |
A nonterminal can derive a terminal followed by a nonterminal or nothing at all. |
Finite state machine |
Challenge: Derive the parse tree for int a = 5; using the C grammar. 'Hint:' it’s a declaration.
Consider the following (fire up your command line and try these out):
echo 'Joey Lawrance' | sed -e 's/\(\w\w*\).*/Hello, \1!/' echo 'lawrancej@wit.edu' | sed 's/\(.*\)@\(.*\)\.\(.*\)/\1 at \2 dot \3/' echo 'deadbeef' | sed -e 's/^\([0-9a-f][0-9a-f]*\)$/Hex: \1/' echo 'deadhorse' | sed -e 's/^\([0-9a-f][0-9a-f]*\)$/Hex: \1/'
With somebody sitting nearby, read the commands carefully and discuss these questions. 'Hint': sed -e s/'REGEX'/'REPLACEMENT'/
-
How do you think it works?
-
What do you think \w means?
-
What do \1, \2 and \3 mean?
-
What does [0-9a-f] mean?
-
Challenge: Can you write a sed command to match only identifiers in, say, C/C++ or Java? Don’t worry about reserved words. 'Hint': massage the last regex into something appropriate.
Regular expressions and finite state machines (finite automata) are interchangeable; we can always convert between them. Even non-deterministic and deterministic finite automata are interchangeable.
Challenge: Can you write finite state machines that correspond to the regular expressions above?
Compilers translate source language(s) to target language(s), and typically consist of the following 'phases':
| Phase | Description | Input | Output |
|---|---|---|---|
Scanning / Tokenization |
Break source code up into small chunks (tokens) such as identifiers, reserved words, literals, operators, etc. |
Source code |
Token stream |
Parsing |
Check the syntax of the source code |
Token stream |
Parse tree |
Translation |
Translate low level syntax into high-level abstract syntax tree |
Parse tree |
Abstract syntax tree, symbol table |
Optimization |
Improve performance or structure |
Abstract syntax tree, symbol table |
Abstract synatx tree, symbol table |
Code generation |
Traverse the AST to generate code. |
Abstract syntax tree, symbol table |
Target code |
Do this individually, or in pairs.
|
Note
|
If working in a pair, go to your github repository settings (on the right side) and add the other person as a collaborator. Then, in your local git repository, add the collaborator’s repository as a remote, using git remote add 'COLLABORATOR' 'SSH_URL'. Then git fetch --all. DO NOT push to your collaborator’s repository, otherwise they’ll be forced to merge in your changes before they can push. Always push to origin (your github repository). |
-
Choose a single compiler implementation to review (suggestions welcome!)
-
Identify which files/functions are responsible for each phase in the compiler source.
-
What was the most ridiculous thing you found? (funny comments? awful code?)
-
Take notes along the way (if you find something that’s unrelated to a compiler phase, try to infer what it’s doing).
-
Write up your findings in a short document and post to your repository (no more than two pages, please). For example:
git add findings.txt git commit -m "Lab 1 findings." git push origin master
Cheat at crosswords (and learn about merge conflicts), the easy way!
-
Pull from upstream
cd ~/COMP603-2014 # Go to your repo first git pull upstream master # Pull (fetch and merge) the latest and greatest from me git mergetool # Use KDiff3 to merge my stuff in (if you have a conflict)
-
Find words that match something interesting, for example:
grep foo... american-english.txt
|
Warning
|
Theory of Computation ahead |
-
The first compiler (for Fortran) took 18 man-years of effort to produce back in the 1950s.
-
CS theory has enabled CS undergraduates understand how to construct compilers within a semester.
Even though languages are sets of strings, it’d be difficult to define useful languages by enumerating all the strings in the set. Therefore, CS theorists and mathematicians have developed handy short-cuts (formal grammars, state machines, etc.) to define languages. Noam Chomsky categorized languages into a hierarchy that bears his name.
You’ve had experience with the most primitive languages (regular languages) and the most complex (recursively enumerable).
Regular expressions define regular languages using only three primitives and three rules:
| Name | Meaning | Example |
|---|---|---|
Empty Set |
Reject everything. |
{} |
Empty String |
Match the empty string. |
{""} |
Symbol |
Match a single character. |
{'a'} |
Sequence |
Match one regular expression followed by one after another. |
If a and b are regular expressions, ab matches a followed by b |
Alternation |
Match either one regular expression or another. |
If a and b are regular expressions, a|b matches {a, b}. |
Kleene Star |
Match a regular expression zero or more times. |
If a is a regular expression, a* matches {"",a,aa,aaa,…} |
|
Important
|
If you haven’t already done so by now, install git and frontends, and then setup your course repository. |
|
Note
|
Don’t worry, this isn’t graded (but please do it anyway) |
Pretend we’re taking a closed-book exam. Answer these questions in a file called prequiz.txt in your repo.
-
What is the difference between a set, a bag, and a sequence?
Sets, bags and sequences are all collections of items. Sets are unordered collections of unique items, bags are unordered collections of potentially duplicated items, and sequences are ordered collections of potentially duplicated items.
-
What is a language (in terms of sets and sequences)?
Languages are sets of strings.
-
What is a compiler? Name some.
Compilers transform one language into another (typically a source language to a machine language).
Examples include: gcc, javac, ghc, etc.
-
What is the derivative of a language?
-
What is a regular expression?
-
What is a finite automaton, and what is the difference between an NFA and a DFA?
-
What is a grammar, and what is the difference between regular grammars, context-free grammars, LL(k) and LR(k)?
-
What is the difference between derivative parsing, recursive-descent parsing, shift-reduce parsing and parser combinators?
-
What is a visitor?
-
What is the difference between a parse tree and an abstract syntax tree?
-
Name some optimizations.
-
What questions do you have for me?
Now, let’s stage, commit and push our stuff off to ensure git is working.
git add prequiz.txt # Stage prequiz.txt (include in next commit) git commit -m "Prequiz answers" # Commit changes with a message git push origin master # Send work to your private repository
-
What’s your name?
-
Why did you pick computer science?
-
What do you still want to learn and/or what do you aspire to do after graduation?
-
Tell us something nobody else knows about you.
-
Even though you may develop mobile/web apps or games, compilers are relevant to your career.
-
Writing compilers give you superpowers: (e.g., RoboVM, emscripten)
- Windows
-
Install Git Extensions, MSysGit and KDiff3.
NoteStick to the default settings, but when asked, choose OpenSSH (not PuTTY). - Mac OS X
-
Note
XCode developer tools ships with git; otherwise, install the latest git from here. - Linux
-
Install git using your package manager. QGit, a git frontend may also be available for your distribution.
NoteDon’t forget to use sudo with your package manager.