

This is a collection of simple PyTorch implementations of neural networks and related algorithms. These implementations are documented with explanations,
The website renders these as side-by-side formatted notes. We believe these would help you understand these algorithms better.
We are actively maintaining this repo and adding new
implementations almost weekly.
- Multi-headed attention
- Transformer building blocks
- Transformer XL
- Rotary Positional Embeddings
- Attention with Linear Biases (ALiBi)
- RETRO
- Compressive Transformer
- GPT Architecture
- GLU Variants
- kNN-LM: Generalization through Memorization
- Feedback Transformer
- Switch Transformer
- Fast Weights Transformer
- FNet
- Attention Free Transformer
- Masked Language Model
- MLP-Mixer: An all-MLP Architecture for Vision
- Pay Attention to MLPs (gMLP)
- Vision Transformer (ViT)
- Primer EZ
- Hourglass
✨ LSTM
✨ ResNet
✨ U-Net
- Original GAN
- GAN with deep convolutional network
- Cycle GAN
- Wasserstein GAN
- Wasserstein GAN with Gradient Penalty
- StyleGAN 2
Solving games with incomplete information such as poker with CFR.
- Proximal Policy Optimization with Generalized Advantage Estimation
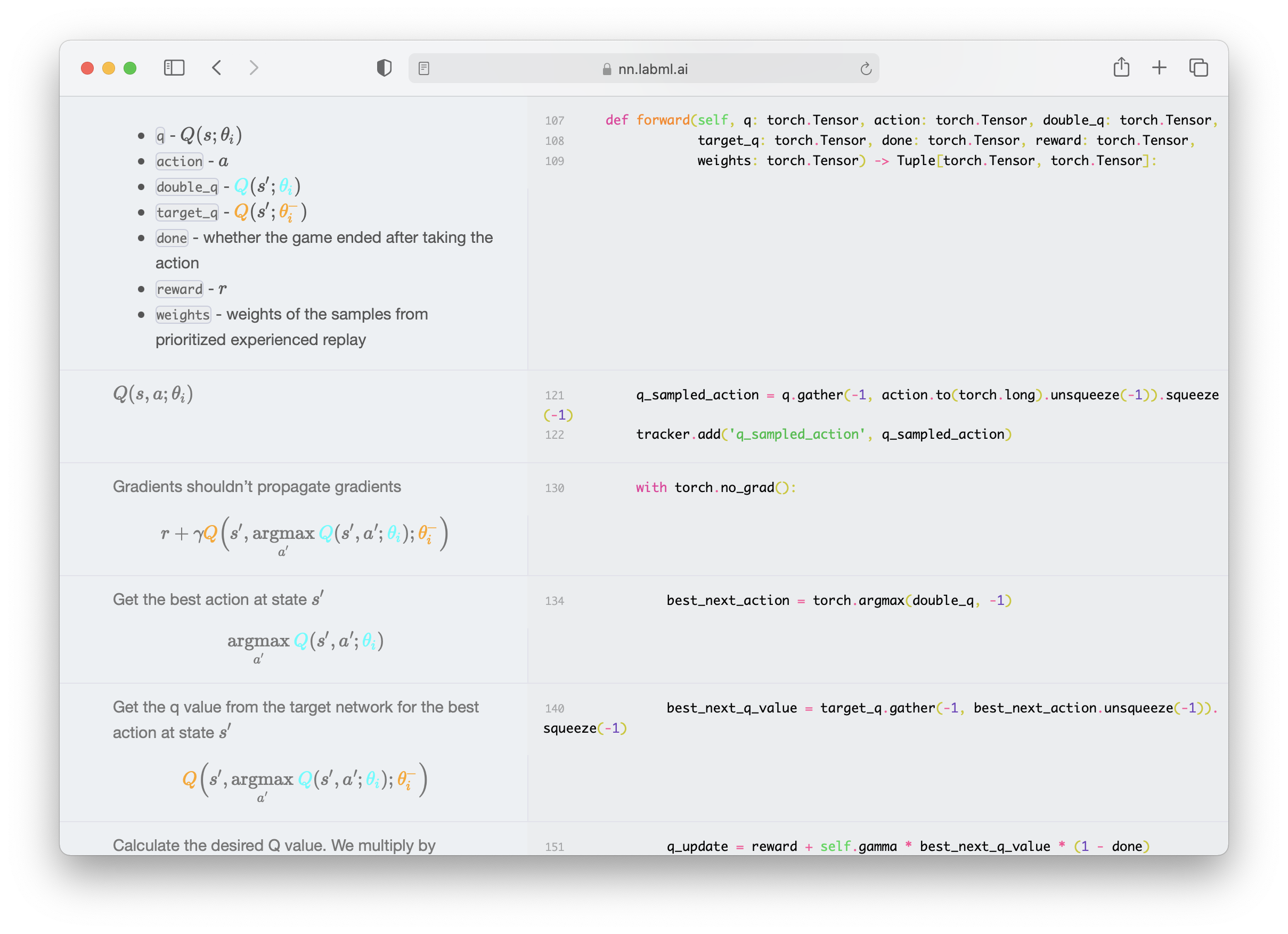
- Deep Q Networks with with Dueling Network, Prioritized Replay and Double Q Network.
- Batch Normalization
- Layer Normalization
- Instance Normalization
- Group Normalization
- Weight Standardization
- Batch-Channel Normalization
- DeepNorm
- FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness
- Autoregressive Search Engines: Generating Substrings as Document Identifiers
- Training Compute-Optimal Large Language Models
- ZeRO: Memory Optimizations Toward Training Trillion Parameter Models
- PaLM: Scaling Language Modeling with Pathways
- Hierarchical Text-Conditional Image Generation with CLIP Latents
- STaR: Self-Taught Reasoner Bootstrapping Reasoning With Reasoning
- Improving language models by retrieving from trillions of tokens
- NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis
- Attention Is All You Need
- Denoising Diffusion Probabilistic Models
- Primer: Searching for Efficient Transformers for Language Modeling
- On First-Order Meta-Learning Algorithms
- Learning Transferable Visual Models From Natural Language Supervision
- The Sensory Neuron as a Transformer: Permutation-Invariant Neural Networks for Reinforcement Learning
- Meta-Gradient Reinforcement Learning
- ETA Prediction with Graph Neural Networks in Google Maps
- PonderNet: Learning to Ponder
- Mastering Atari, Go, Chess and Shogi by Planning with a Learned Model
- GANs N’ Roses: Stable, Controllable, Diverse Image to Image Translation (works for videos too!)
- An Image is Worth 16X16 Word: Transformers for Image Recognition at Scale
- Deep Residual Learning for Image Recognition
- Distilling the Knowledge in a Neural Network
pip install labml-nnIf you use this for academic research, please cite it using the following BibTeX entry.
@misc{labml,
author = {Varuna Jayasiri, Nipun Wijerathne},
title = {labml.ai Annotated Paper Implementations},
year = {2020},
url = {https://nn.labml.ai/},
}This shows the most popular research papers on social media. It also aggregates links to useful resources like paper explanations videos and discussions.
This is a library that let's you monitor deep learning model training and hardware usage from your mobile phone. It also comes with a bunch of other tools to help write deep learning code efficiently.