This repository contains the PyTorch (1.2+) implementation of our branch of Open-Unmix: a study on different loss functions for Music Source Separation. For mor details on the architecture, visit the main respository.
Related Projects: open-unmix-pytorch | musdb | museval | norbert
Researchers have proposed several alternatives to L2 that can be found in recent literature, but usually tested in different conditions. These can be summarized in the following taxonomy:

First and foremost, traditional spectrogram losses may be computed with an spectral source separator such as Open-Unmix. Next, performing the ISTFT inside the model additionally allows us to implement losses that are normally used in time domain models. Besides, we can adapt the whole training loop from supervised learning into an semi-supervised approach with adversarial losses. Lastly, deep features might be incorporated into the supervised loop through the use of pre-trained models' embeddings. This taxonomy categorization also depends on the point at which each loss is computed in the model's pipeline:

TODO
For installation we recommend to use the Anaconda python distribution. To create a conda environment for open-unmix, simply run:
conda install -c pytorch torchaudio
pip install museval
conda env create -f environment-X.yml where X is either [cpu-linux, gpu-linux-cuda10, cpu-osx], depending on your system. For now, we haven't tested windows support.
Once installed, update the dataset and outpupt paths on run_experiments.sh and run it:
sh run_experiments.shOpen-Unmix yields state-of-the-art results compared to participants from SiSEC 2018. The performance of UMXHQ and UMX is almost identical since it was evaluated on compressed STEMS.
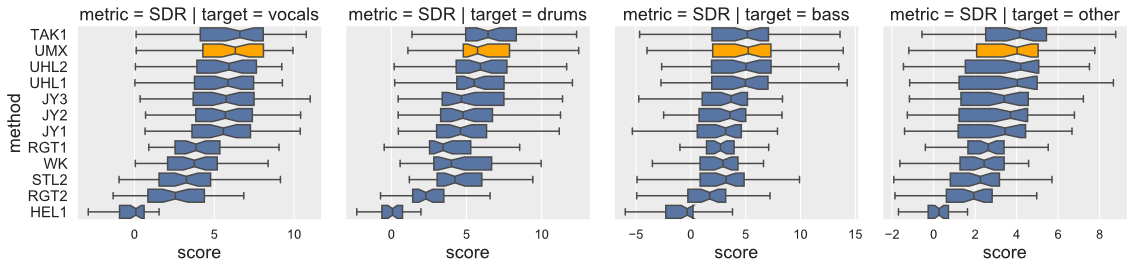
Note that
- [
STL1,TAK2,TAK3,TAU1,UHL3,UMXHQ] were omitted as they were not trained on only MUSDB18. - [
HEL1,TAK1,UHL1,UHL2] are not open-source.
| target | SDR | SIR | SAR | ISR | SDR | SIR | SAR | ISR |
|---|---|---|---|---|---|---|---|---|
model |
UMX | UMX | UMX | UMX | UMXHQ | UMXHQ | UMXHQ | UMXHQ |
| vocals | 6.32 | 13.33 | 6.52 | 11.93 | 6.25 | 12.95 | 6.50 | 12.70 |
| bass | 5.23 | 10.93 | 6.34 | 9.23 | 5.07 | 10.35 | 6.02 | 9.71 |
| drums | 5.73 | 11.12 | 6.02 | 10.51 | 6.04 | 11.65 | 5.93 | 11.17 |
| other | 4.02 | 6.59 | 4.74 | 9.31 | 4.28 | 7.10 | 4.62 | 8.78 |
Details on the training is provided in a separate document here.
Details on how open-unmix can be extended or improved for future research on music separation is described in a separate document here.
we favored simplicity over performance to promote clearness of the code. The rationale is to have open-unmix serve as a baseline for future research while performance still meets current state-of-the-art (See Evaluation). The results are comparable/better to those of UHL1/UHL2 which obtained the best performance over all systems trained on MUSDB18 in the SiSEC 2018 Evaluation campaign.
We designed the code to allow researchers to reproduce existing results, quickly develop new architectures and add own user data for training and testing. We favored framework specifics implementations instead of having a monolithic repository with common code for all frameworks.
open-unmix is a community focused project, we therefore encourage the community to submit bug-fixes and requests for technical support through github issues. For more details of how to contribute, please follow our CONTRIBUTING.md. For help and support, please use the gitter chat or the google groups forums.
Fabian-Robert Stöter, Antoine Liutkus, Inria and LIRMM, Montpellier, France
If you use open-unmix for your research – Cite Open-Unmix
@article{stoter19,
author={F.-R. St\\"oter and S. Uhlich and A. Liutkus and Y. Mitsufuji},
title={Open-Unmix - A Reference Implementation for Music Source Separation},
journal={Journal of Open Source Software},
year=2019,
doi = {10.21105/joss.01667},
url = {https://doi.org/10.21105/joss.01667}
}If you use the MUSDB dataset for your research - Cite the MUSDB18 Dataset
@misc{MUSDB18,
author = {Rafii, Zafar and
Liutkus, Antoine and
Fabian-Robert St{\"o}ter and
Mimilakis, Stylianos Ioannis and
Bittner, Rachel},
title = {The {MUSDB18} corpus for music separation},
month = dec,
year = 2017,
doi = {10.5281/zenodo.1117372},
url = {https://doi.org/10.5281/zenodo.1117372}
}If compare your results with SiSEC 2018 Participants - Cite the SiSEC 2018 LVA/ICA Paper
@inproceedings{SiSEC18,
author="St{\"o}ter, Fabian-Robert and Liutkus, Antoine and Ito, Nobutaka",
title="The 2018 Signal Separation Evaluation Campaign",
booktitle="Latent Variable Analysis and Signal Separation:
14th International Conference, LVA/ICA 2018, Surrey, UK",
year="2018",
pages="293--305"
}MIT
![]()
