Hyperfiddle abstracts over client/server data sync for APIs. If React.js is managed DOM, Hyperfiddle is managed database and network.
Hyperfiddle models API inter-dependencies as a graph (I need query-X and also query-Y which depends query-Z). This graph lets the I/O runtime understand the structure and data flows of the application, which permits interesting optimization opportunities.
Hyperfiddle extends Datomic's immutable database semantics to the API. Unlike REST/GraphQL/whatever, Hyperfiddle's data sync composes. APIs are defined with simple Clojure functions, for example
(defn api-blog-index [state peer]
[(->QueryRequest
'[:find (pull ?e [:db/id :post/title :post/content]) :where [?e :post/title]]
{"$" (hc/db peer #uri "datomic:free://datomic:4334/samples-blog" nil)})])These API functions are
- referentially transparent and compose
- coded in CLJC
- don't know the difference between API client or API server
- run simultaneously in both API client and API server
API functions' lifecycle is managed by an "I/O runtime", analogous to React's managed virtual-dom functions. Managed I/O is not the point; the point is: what does managed I/O make possible that wasn't possible before?
[com.hyperfiddle/hyperfiddle "0.0.0"]
Hyperfiddle is alpha software. The core is quite mature and stable and in prod at http://hyperfiddle.net. The public API is not frozen.
https://www.reddit.com/r/hyperfiddle/ will aggregate all our scattered blog posts, tutorials and documentation.
- Slack: #Hyperfiddle @ clojurians, come say hi, tell us why you care, and hang out!
- Twitter: https://twitter.com/dustingetz
- developer mailing list
We're nearing a 0.1 open-source release in Q1 2018.
Performance (Hyperfiddle must respond as fast as a Clojure repl)
- API: data loop running in JVM
- API: automatically optimize hydrates for cache locality (using link graph)
- API: Release CLI to serve your fiddles (no http/backend boilerplate for application developers)
- UI: improve popovers, finish stage/discard UX
- UI: Human readable URLs and customizable URL router
- UI: Fix query param tooltips when you hover an anchor
- release Hyperblog, a markdown
static site generatorstatic application backed by Datomic - Edit React.js/Reagent expressions side-by-side with the running app (like JSFiddle)
- IDE user experience, including links panel
Hyperfiddle is built in layers. Higher layers are optional and implemented in terms of lower.
- Managed I/O primitives: API defined as a function
- API modeled as graph: data-driven CRUD model, API defined in EDN
- Data-driven UI: automatic UI (like Swagger)
- IDE for applications: structural editor for APIs
Hyperfiddle IDE, the structural editor (http://www.hyperfiddle.net) is also the open-source reference application to teach you how Hyperfiddle works. Hyperfiddle IDE runs on your machine from a CLI (hyperfiddle serve datomic:free://localhost:4334/my-fiddles); it runs in your application as a jar file from github, and as managed elastic cloud infrastructure.
The dashboard UI components are built with Reagent and support SSR, but it should be straightforward to use any managed dom rendering strategy.
Hyperfiddle makes forms and such really easy to write (something a web designer can do), because when I/O is managed, there is nothing left but markup. Hyperfiddle comes batteries included with a library of UI components, but you don't have to use them.
Hyperfiddle's data sync loop runs in the JVM (to solve N+1 problem of REST).
A simple API function, with two database queries:
(def datomic-samples-blog #uri "datomic:free://datomic:4334/samples-blog")
(def db-branch nil) ; This is the datomic time-basis; nil is HEAD
(def race-registration-query
'[:find (pull ?e [:db/id :reg/email :reg/gender :reg/shirt-size])
:in $ :where [?e :reg/email]])
(def gender-options-query
'[:find (pull ?e [:db/id :reg.gender/ident])
:in $ :where [?e :reg.gender/ident]])
(defn request [state peer]
(let [$ (hc/db peer datomic-samples-blog db-branch)]
[(->QueryRequest race-registration-query {"$" $})
(->QueryRequest gender-options-query {"$" $})]))Notes:
- API fns return seq (use
mapcatetc to hydrate many queries in bulk) - I/O runtime will call API fn repeatedly until its return value stabalizes
- This permits queries that depend on the results of earlier queries
- CLJC can run in client, server, or both simultaneously (useful for optimizations)
- Data loop typically runs in JVM Datomic Peer, so no network hops or N+1 problem
- Data loop sometimes runs in browser (e.g. in response to incremental ui state change)
- Userland sheltered from I/O and async
- All fiddles speak the same API
- API tooling built-in (like Swagger or OData)
- No low level backend/frontend http boilerplate
- No REST, no browser/service round trips
- No ORM, no GraphQL resolver, no service/database round trips
- Massively parallelizable, serverless, elastic
- all responses are immutable, all requests have a time-basis
- CDN integration that understands your app (serve APIs like static sites)
Now that we have a properly composable I/O primitive, we can use it as a basis to build composable abstractions:
An API defined as EDN ("fiddle"). Fiddles have links to other fiddles, this forms a graph.
{:db/id 17592186045418, ; Root query
:fiddle/type :query,
:fiddle/query "[:find (pull ?e [:db/id :reg/email :reg/gender :reg/shirt-size]) :in $ :where [?e :reg/email]]",
:fiddle/links #{{:db/id 17592186045427, ; link to gender options
:link/rel :options,
:link/render-inline? true, ; embedded like an iframe
:link/path "0 :reg/gender",
:link/fiddle {:db/id 17592186045428, ; select options query
:fiddle/type :query,
:fiddle/query "[:find (pull ?e [:db/id :reg.gender/ident]) :in $ :where [?e :reg.gender/ident]]",
:fiddle/links #{{:db/id 17592186045474, ; link to new-gender-option form
:link/rel :sys-new-?e,
:link/fiddle #:db{:id 17592186045475} ; new-gender form omitted
}}}}
{:db/id 17592186045434, ; link to shirt-size options
:link/rel :options,
:link/render-inline? true, ; embedded like an iframe
:link/dependent? true, ; dependency on parent fiddle's data
:link/path "0 :reg/shirt-size",
:link/formula "(fn [ctx] {:request-params {\"?gender\" (get-in ctx [:cell-data :reg/gender])}})",
:link/fiddle #:db{:id 17592186045435} ; shirt size options query omitted
}
{:db/id 17592186045481, ; link to new-registration form
:link/rel :sys-new-?e,
:link/fiddle #:db{:id 17592186045482} ; new-registration form omitted
}}}- Automatic I/O partitioning and batching, optimized for cache hits
- Server preloading, prefetching and optimistic push
- Machine learning can analyze the graph to do optimzations
We do some of this already today.
Batteries included tooling, your API "just works" out of the box. A picture is worth 1000 words:

Above EDN definition, rendered. Pink highlights indicate a link to another fiddle. click here for the live fiddle.

All Hyperfiddle APIs must resolve to a function, and this is no different. Fiddles are interpreted by a very special function called the Hyperfiddle Browser. The Browser interprets fiddles by navigating the link graph.
web browser : HTML documents :: hyperfiddle browser :: hyperfiddle EDN values
The Browser has the following hook points for progressive enhancement with Reagent expressions:
- Fiddle root
- Datomic attributes #{:post/content :post/title :post/date ...}
- Datomic type #{string keyword bool inst long ref ...}
- UI controls #{form table tr th label value ...}
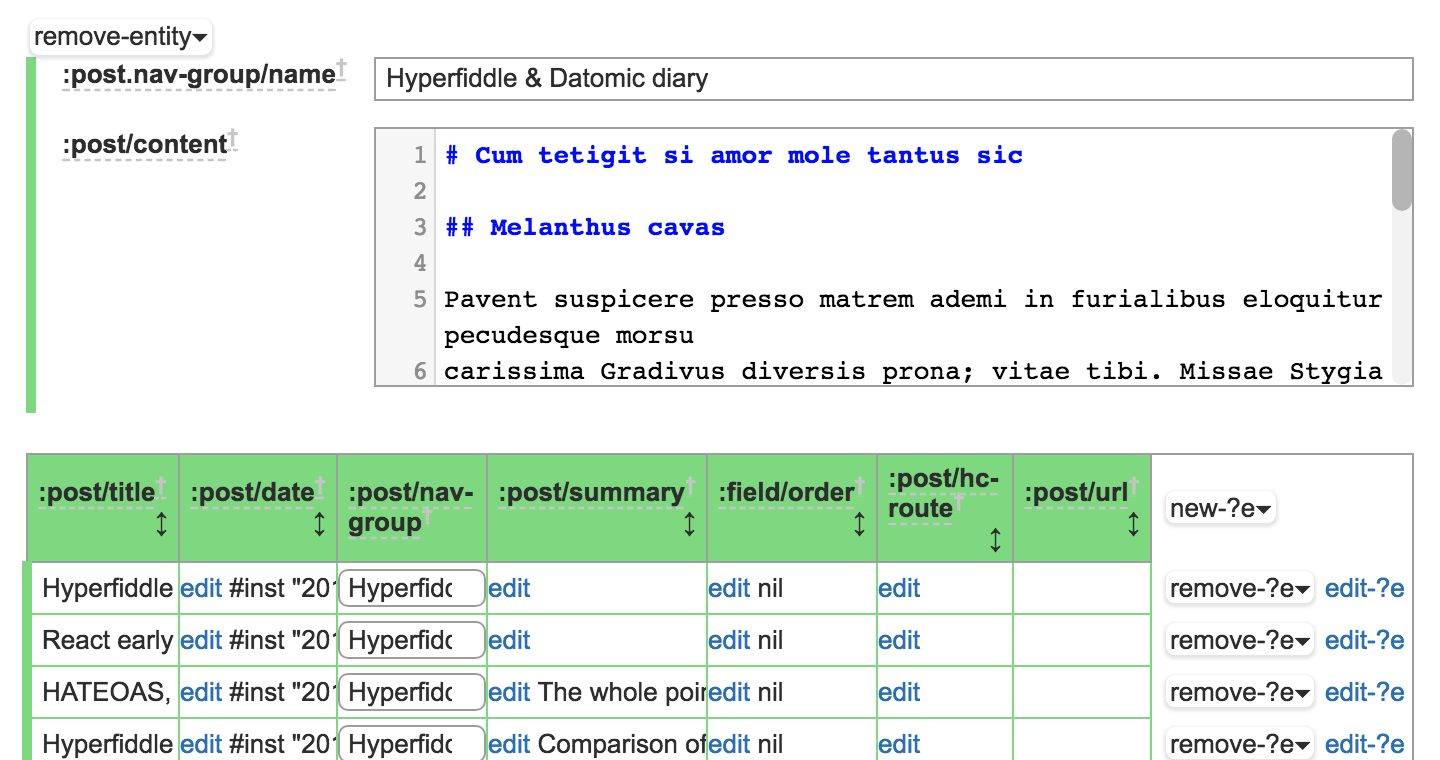
This dashboard is fully data driven. The markdown editor is defined by ClojureScript code, stored in a database and eval'ed at runtime.

Here is a markdown attribute renderer:
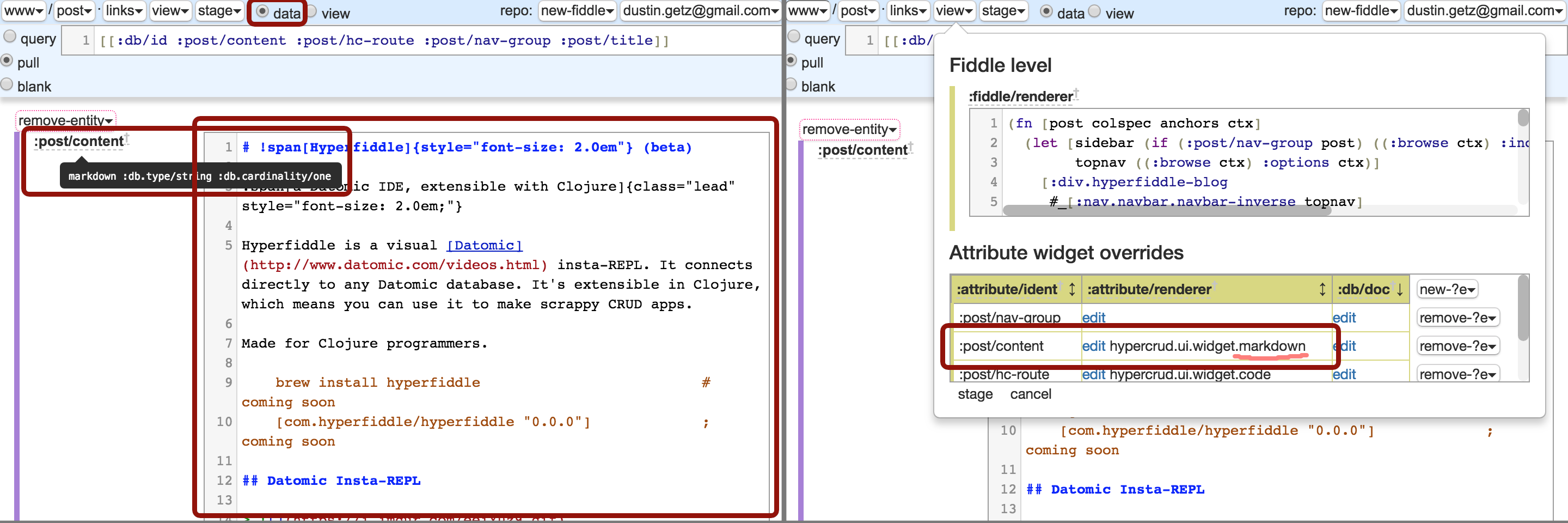
On the left, we see
:post/contentattribute is a Datomic:db.type/string, being rendered as a CodeMirror with markdown syntax highlighting. On the right, we see it wired up. Renderers can be any ClojureScript expression and are eval'ed at runtime.

Here is a fiddle root renderer:
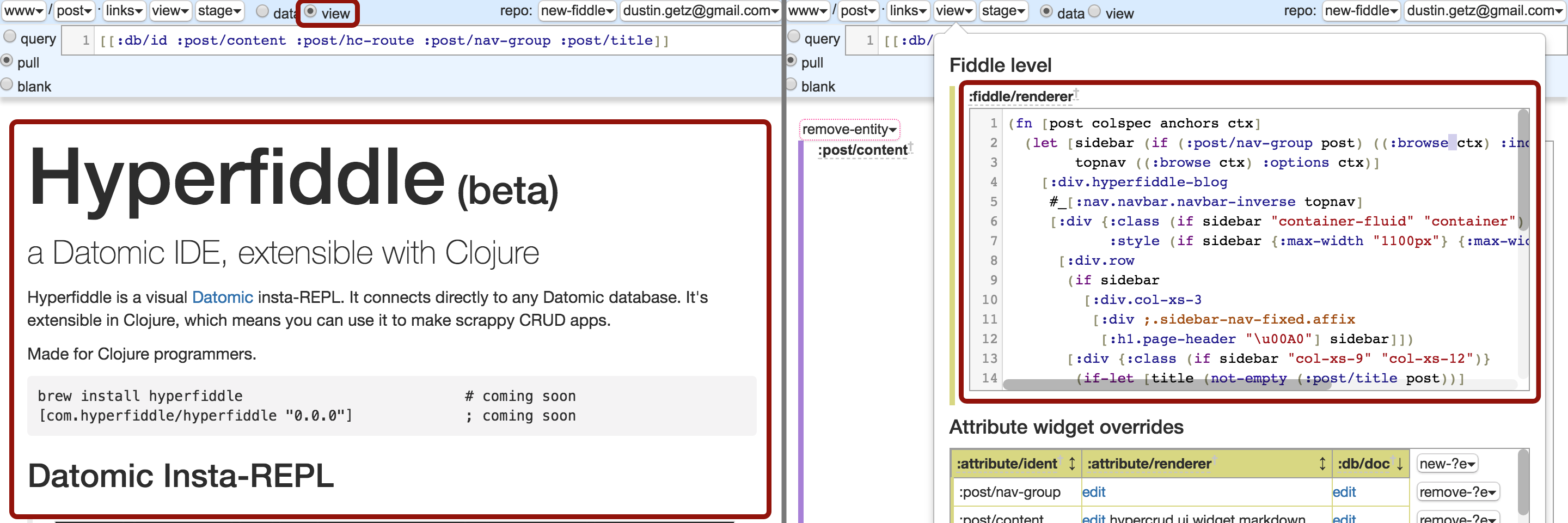
On the left, we see the fiddle's final rendering. It is no longer a form at all, we've rendered the data as HTML. On the right, we see the Reagent expression. The data/view toggles the fiddle renderer, so you can always get to the admin dashboard.

Here is the Datomic schema renderer, TODO this should be a core.match config stored in a database...
Views are very easy to code since they're just functions.
The dashboard is backed by an API, which hydrates a route (URL), except instead of HTML the server the server returns EDN (transit). There is also an "open" API for development that will respond to any query, not just valid routes. The "open" API has future implications for the semantic web.
Once you start coding "data" (data-ing?), a few ideas form:
- Data is vastly more productive than code, the surface area for bugs is tiny–mostly just typos
- Working with EDN-serialized text on a filesystem is stupid
Hyperfiddles are graphs, not text, so instead of git they are stored in Datomic. This means you can query the graph e.g. "which fiddles link to me". Like git and the web, there is no central database. The future implications of this are profound.
Hyperfiddle IDE is out of scope for this readme, but here is a picture.
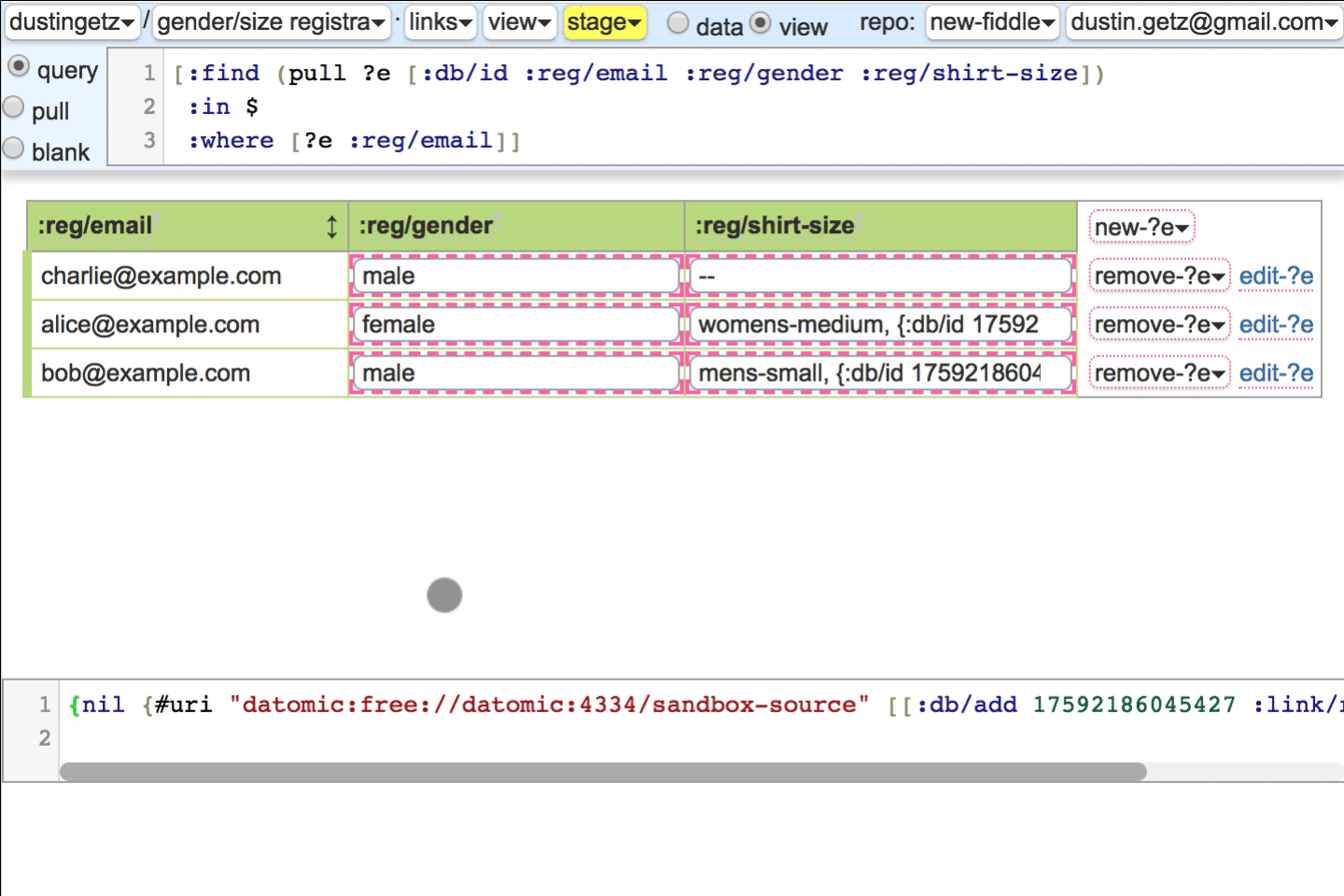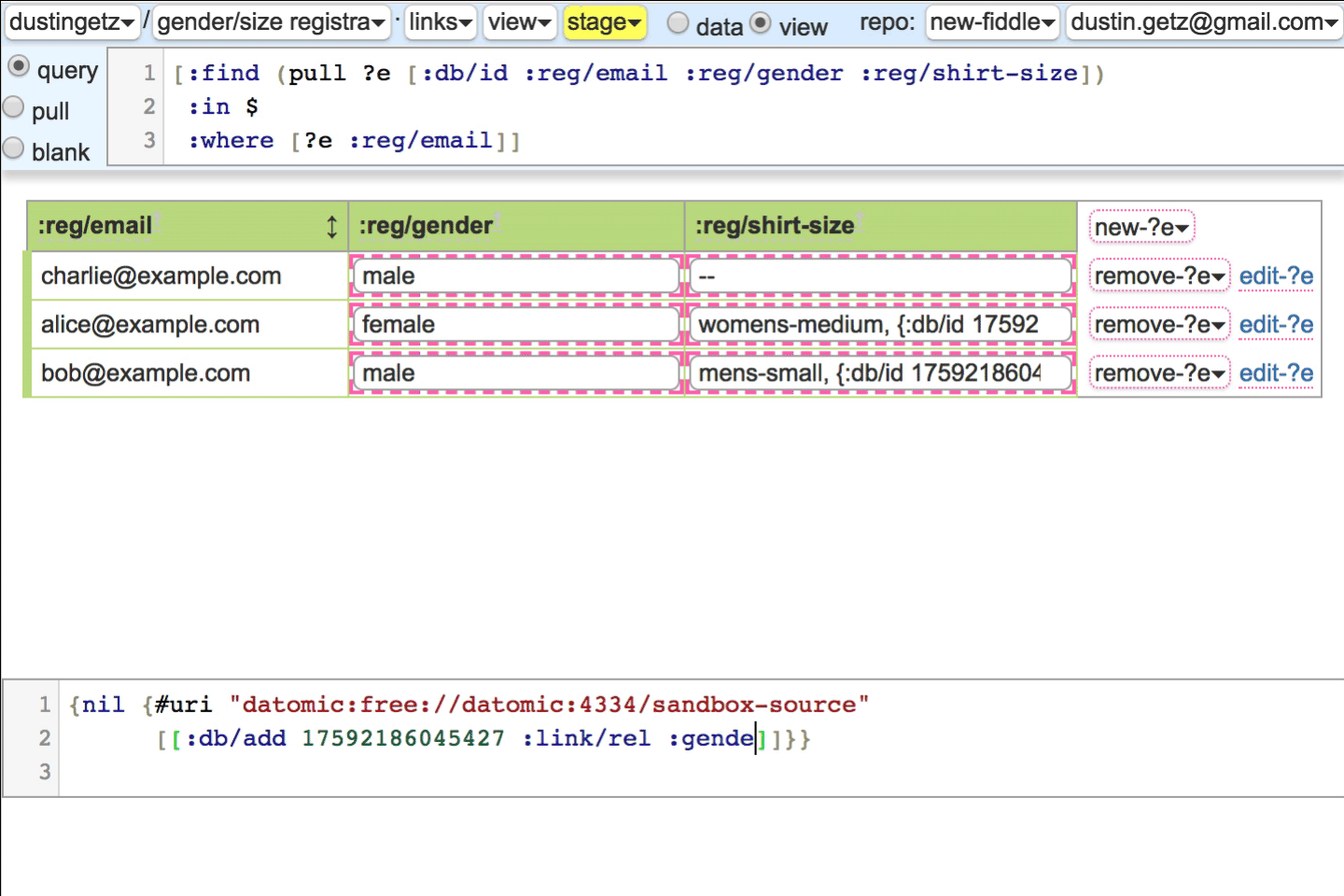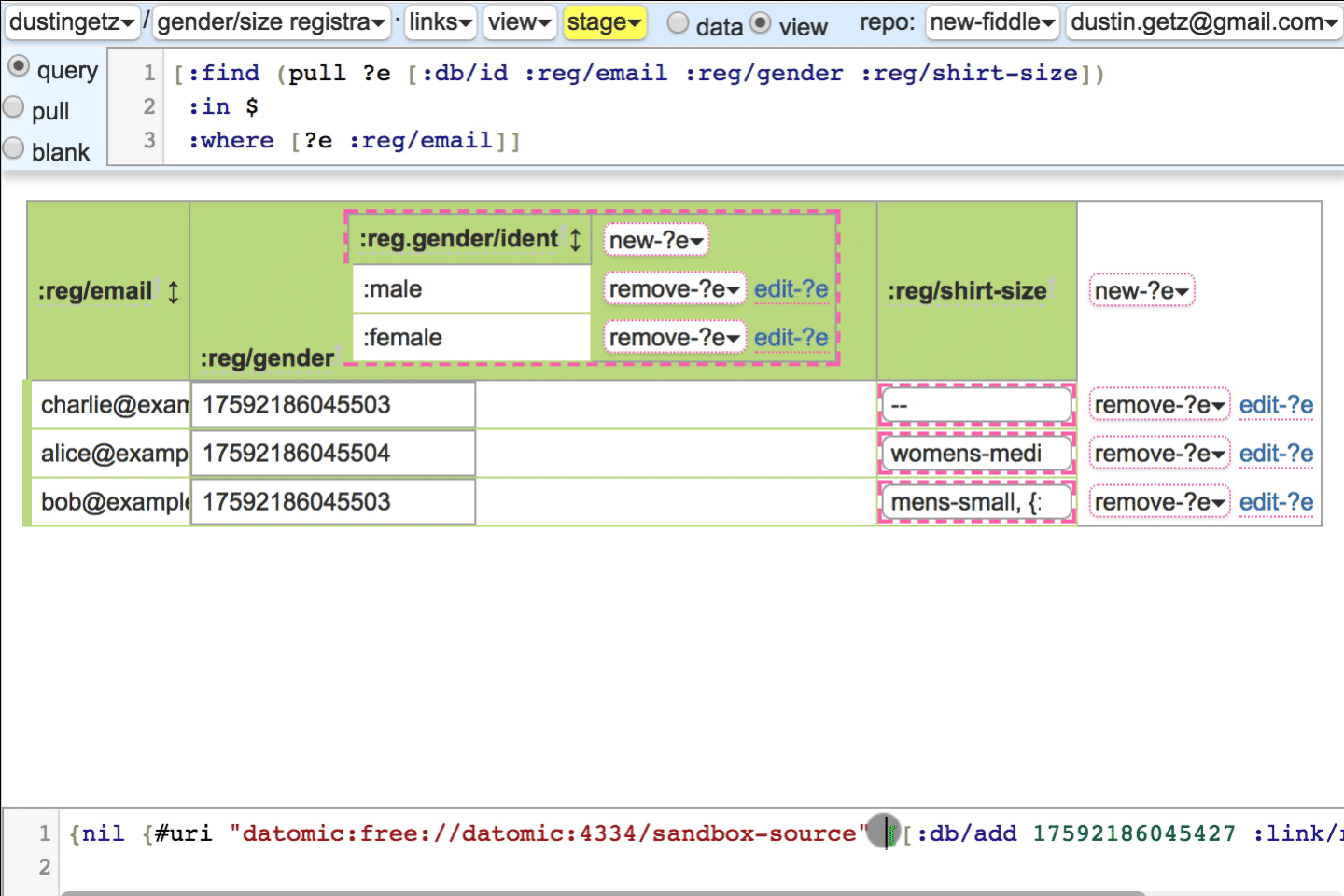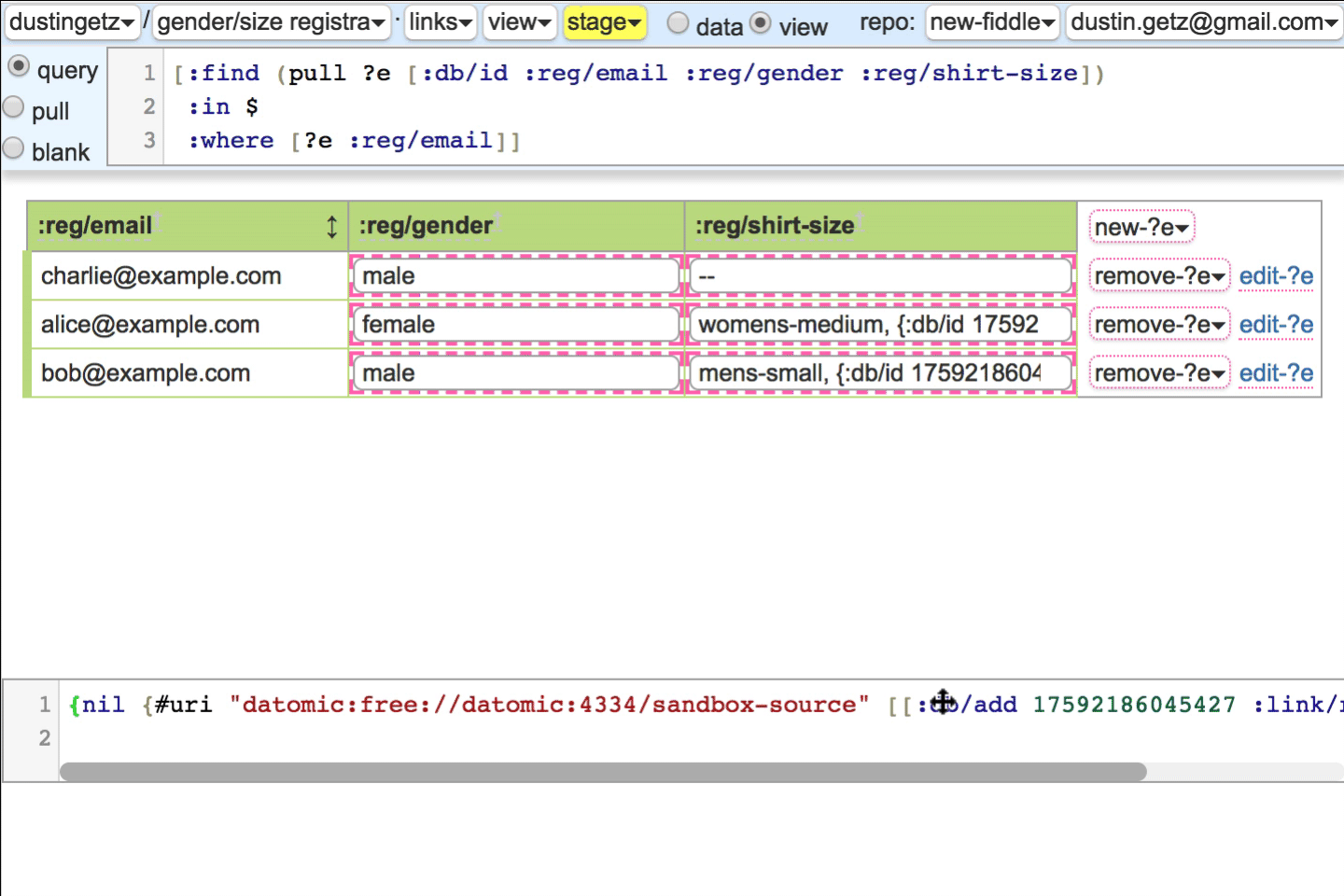
Select options are iframes with style.
:link/relhas semantic meaning like html,:optionsmatches up with the:db.type/refrenderer. When the gender semantic renderer is toggled off, the link is in the header, because the query runs once, not per-row. If you override the:db.type/refrenderer, you may care to use:link/relas semantic hint, or not. Imagine a link/rel registry like HTML.

The following screenshot is fully defined as Hyperfiddle EDN and simple Reagent expressions that a web designer could write.
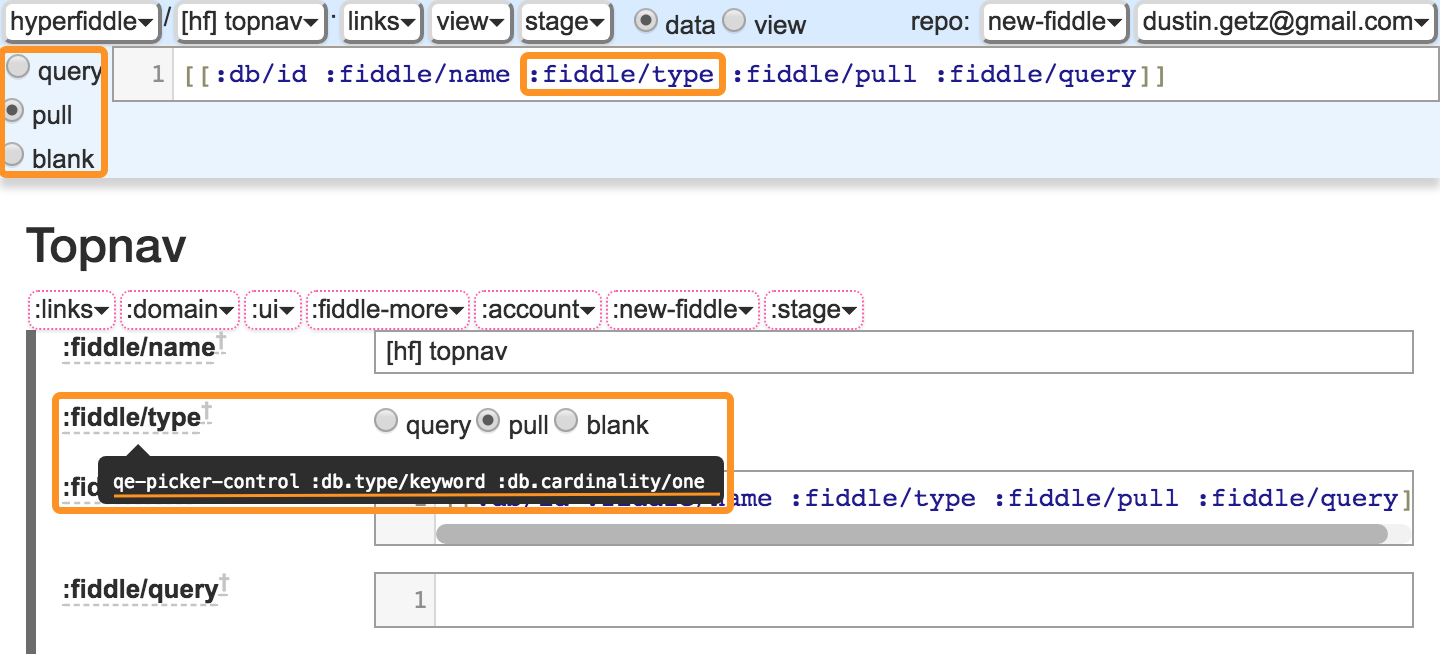
The radio control on
:fiddle/typeis a custom attribute renderer,qe-picker-control, which is defined in the view menu and eval'ed at runtime.:fiddle/query's custom renderer is a CodeMirror with syntax highlighting, balanced parens etc. The fiddle's own layout (including button labels and local state) is a fiddle renderer, about 100 lines of Reagent markup, defined in the view menu and eval'ed at runtime. Each menu is a:buttonlink to another fiddle, with its own data dependencies and renderers.

Integration with REST/fiat APIs: Hyperfiddle can't help you with foreign data sync but it doesn't get in the way either. Do what you'd do in React. You'll lose out-of-the-box SSR.
Local state in UI: Hyperfiddle is about data sync; Do what you'd do in React. Keep in mind that Hyperfiddle data sync is so fast (on par with static sites) that you may not need much local state; just use page navigation (the URL is a perfectly good place to store state). Local state is perfectly allowable and idiomatic
Reframe: Reframe does not support SSR, and we want SSR by default. It should be straightforward to swap in reframe or any other rendering strategy.
Why Reagent? Vanilla React is memoized rendering oriented around values. It's not fast enough; Hyperfiddle UIs can get very sophisticated very fast, the reactive abstraction is required to feel snappy.
Query subscription issues: Relational/graph databases aren't designed for this, because in the general case you'd need to re-run all the queries on a page to know if new data impacts them (and on Facebook there are hundreds of queries per page). However in the average case, we just want subscriptions on simple queries for which a heuristic works, or for only specific queries, which I believe the Posh project has working, see this reddit thread
- Eric: I would like to understand where caching actually happens
- Eric: What happens from top to bottom when a form is rendered
- Eric: synchronous and reactive - what does this mean?
Without immutability in the database, all efforts to abstract higher will fail; because to achieve the necessary performance, requires writing imperative optimizations to imperative platforms (object-relational impedance mismatch, N+1 problems, deeply nested JOINs, caching vs batching tradeoffs). Hyperfiddle cannot be built on RDBMS or Neo4J; their imperative nature leaks through all attempts to abstract. This is why all 4GLs historically fail. Immutability, as always, to the rescue.
How high can we abstract? We aren't sure yet. It will scale until Datomic's app-as-a-value abstraction breaks down, at which point programmers will manually optimize their Datomic services. Datomic Peer vs Client vs Cloud makes a difference here as they all have different stories for code/data locality.
Hyperfiddle's abstraction has scaled quite far already, see Hyperfiddle-in-Hyperfiddle. We think there is much more room to go. Imagine a world of composable applications.