Spracherkennung auf Ende-zu-Ende-Satzebene mit DeepMind's WaveNet
Eine Tensorflow-Implementierung der Spracherkennung basierend auf DeepMinds [WaveNet: A Generative Model for Raw Audio] (https://arxiv.org/abs/1609.03499). (Im Folgenden das Paper)
Obwohl ibab und tomlepaine bereits WaveNet mit Tensorflow implementiert haben, haben sie keine Spracherkennung implementiert. Deshalb haben wir beschlossen, sie selbst zu implementieren.
Einige der jüngsten Arbeiten von Deepmind sind schwer zu reproduzieren. Das Papier ließ auch spezifische Details über die Implementierung aus, und wir mussten die Lücken auf unsere eigene Weise füllen.
Hier sind ein paar wichtige Hinweise.
Erstens: Während im Paper der TIMIT-Datensatz für das Spracherkennungsexperiment verwendet wurde, haben wir den freien VTCK-Datensatz verwendet.
Zweitens fügte das Paper eine Mean-Pooling-Schicht nach der dilatierten Faltungsschicht zum Down-Sampling hinzu. Wir extrahierten MFCC aus wav-Dateien und entfernten die letzte Mean-Pooling-Schicht, da die ursprüngliche Einstellung auf unserem TitanX-Grafikprozessor nicht lauffähig war.
Drittens: Da der TIMIT-Datensatz Phonem-Etiketten enthält, wurde das Modell in der Arbeit mit zwei Verlusttermen trainiert, der Phonem-Klassifikation und der Vorhersage des nächsten Phonems. Wir haben stattdessen einen einzigen CTC-Verlust verwendet, da VCTK Labels auf Satzebene liefert. Infolgedessen verwendeten wir nur dilated conv1d-Schichten ohne dilated conv1d-Schichten.
Schließlich haben wir aus Zeitgründen keine quantitativen Analysen wie BLEU-Score und Post-Processing durch Kombination eines Sprachmodells durchgeführt.
Die endgültige Architektur ist in der folgenden Abbildung dargestellt.
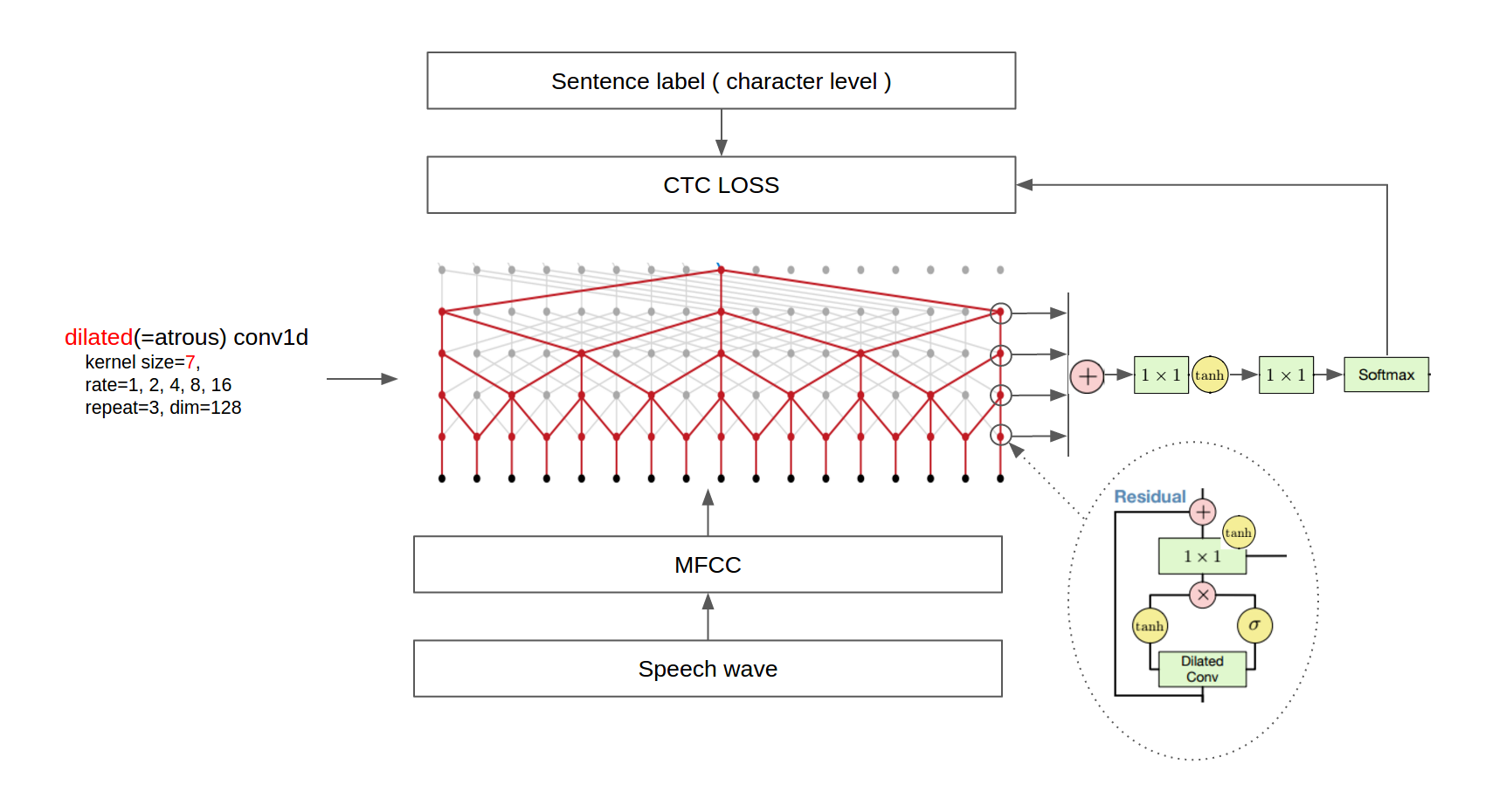
Aktuelle Version : 0.0.0.2
- tensorflow == 1.0.0
- sugartensor == 1.0.0.2
- pandas >= 0.19.2
- librosa == 0.5.0
- scikits.audiolab==0.11.0
Wenn Sie Probleme mit der librosa-Bibliothek haben, versuchen Sie, ffmpeg mit dem folgenden Befehl zu installieren. ( Ubuntu 14.04 )
sudo add-apt-repository ppa:mc3man/trusty-media
sudo apt-get update
sudo apt-get dist-upgrade -y
sudo apt-get -y install ffmpeg
Verwenden Sie VCTK, LibriSpeech und TEDLIUM release 2 Korpus. Die Gesamtzahl der Sätze in der Trainingsmenge, die aus den drei oben genannten Korpussen besteht, beträgt 240.612. Der Gültigkeits- und Testsatz wird nur aus LibriSpeech- und TEDLIUM-Korpus gebildet, da das VCTK-Korpus keinen Gültigkeits- und Testsatz hat. Nach dem Herunterladen der einzelnen Korpusse extrahieren Sie diese in die Ordner 'asset/data/VCTK-Corpus', 'asset/data/LibriSpeech' und 'asset/data/TEDLIUM_release2' entpackt.
Audio wurde durch das Schema in der Arbeit von [Tom Ko et al] (http://speak.clsp.jhu.edu/uploads/publications/papers/1050_pdf.pdf) ergänzt.
Der TEDLIUM-Release-2-Datensatz stellt Audiodaten im SPH-Format bereit, daher sollten wir sie in ein bestimmtes Format konvertieren librosa-Bibliothek verarbeiten kann. Führen Sie den folgenden Befehl im Verzeichnis „asset/data“ aus, konvertieren Sie SPH in das Wave-Format.
find -type f -name '*.sph' | awk '{printf "sox -t sph %s -b 16 -t wav %s\n", $0, $0".wav" }' | bash
Wenn Sie sox nicht installiert haben, installieren Sie es bitte zuerst.
sudo apt-get install sox
Wir haben festgestellt, dass der Hauptengpass die Lesezeit der Festplatte beim Training ist, also haben wir uns entschieden, die gesamten Audiodaten vorzuverarbeiten die MFCC-Funktionsdateien, die viel kleiner sind. Und wir empfehlen dringend, eine SSD anstelle einer Festplatte zu verwenden. Führen Sie den folgenden Befehl in der Konsole aus, um das gesamte Dataset vorzuverarbeiten.
python-preprocess.py
Ausführen
python train.py ( <== Alle verfügbaren GPUs verwenden )
oder
CUDA_VISIBLE_DEVICES=0,1 python train.py ( <== Nur GPU 0, 1 verwenden)
um das Netzwerk zu trainieren. Sie können die resultierenden ckpt-Dateien und Protokolldateien im Verzeichnis „asset/train“ sehen. Starten Sie tensorboard --logdir asset/train/log, um den Trainingsprozess zu überwachen.
Wir haben dieses Modell auf 3 Nvidia 1080 Pascal GPUs während 40 Stunden bis 50 Epochen trainiert und wir haben die Epoche ausgewählt, in der die Validierungsverlust ist minimal. In unserem Fall ist es Epoche 40. Wenn Sie mit dem Fehler „Speichermangel“ konfrontiert werden, reduzieren Sie „batch_size“ in der Datei „train.py“ von 16 auf 4.
Die CTC-Verluste in jeder Epoche sind wie in der folgenden Tabelle dargestellt:
| Epoche | Zugset | gültiger Satz | Testsatz |
|---|---|---|---|
| 20 | 79,541500 | 73.645237 | 83.607269 |
| 30 | 72.884180 | 69,738348 | 80.145867 |
| 40 | 69,948266 | 66.834316 | 77.316114 |
| 50 | 69.127240 | 67,639895 | 77,866674 |
Nach Abschluss des Trainings können Sie den gültigen CTC-Verlust mit dem folgenden Befehl überprüfen oder testen.
python test.py --set train|valid|test --frac 1.0(0.01~1.0)
Die Option „frac“ ist nützlich, wenn Sie nur den Bruchteil des Datensatzes für eine schnelle Auswertung testen möchten.
Ausführen
python detect.py --file
um eine Sprachdatei in den Deutschen Satz umzuwandeln. Das Ergebnis wird auf der Konsole ausgegeben.
Versuchen Sie zum Beispiel den folgenden Befehl.
python detect.py --file asset/data/LibriSpeech/test-clean/1089/134686/1089-134686-0000.flac
python detect.py --file asset/data/LibriSpeech/test-clean/1089/134686/1089-134686-0001.flac
python detect.py --file asset/data/LibriSpeech/test-clean/1089/134686/1089-134686-0002.flac
python detect.py --file asset/data/LibriSpeech/test-clean/1089/134686/1089-134686-0003.flac
python detect.py --file asset/data/LibriSpeech/test-clean/1089/134686/1089-134686-0004.flac
Das Ergebnis wird wie folgt aussehen:
er hoffte, dass es zum Abendessen einen Platz für Rüben und Saiblinge und zerdrückte Kartoffeln und fette Hammelstücke geben würde, die in der dicken Pfefferblumen-Fatan-Sauce ausgeschöpft würden
in dich hineingestopft, riet ihm sein Bauch
nach Einbruch der frühen Nacht hüpfen hier und da die noch Lampen, woich Licht auf dem squaled Viertel der Browfles
o Berty und er Gott in deinem Kopf
numbrt tan fresh nalli wartet auf deinen kalten nit ehemann
Die Grundwahrheit ist wie folgt:
Er hoffte, dass es zum Abendessen einen Eintopf geben würde, Rüben und Karotten und zerquetschte Kartoffeln und fette Hammelstücke, die in einer dicken, mit Pfeffermehl gemästeten Soße ausgeschöpft würden
Stopf es in deinen Bauch, riet ihm sein Bauch
NACH FRÜHER NACHT WÜRDEN HIER UND DA DIE GELBEN LAMPEN AUFLEUCHTEN IN DEN SQUALIDEN VIERTELN DER BORDEL
HALLO BERTIE IRGENDWELCHES GUTES IN IHREM VERSTAND
NUMMER ZEHN FRESH NELLY WARTET AUF EUCH GUTE NACHT EHEMANN
Wie bereits erwähnt, gibt es kein Sprachmodell, also dass es einige Fälle gibt, in denen Großbuchstaben, Satzzeichen und Wörter falsch geschrieben sind.
Sie können eine Sprachwellendatei mit dem auf dem VCTK-Korpus vortrainierten Modell in englischen Text umwandeln. Entpacken Sie die folgende Zip-Datei in das Verzeichnis 'asset/train/'.
Siehe Docker README.md.
-
Sprachmodell
-
Polyglotten (mehrsprachiges) Modell
Wir denken, dass wir den CTC-Beam-Decoder durch ein praktisches Sprachmodell ersetzen sollten und das polyglotte Spracherkennungsmodell wird ein guter Kandidat für zukünftige Referenzen sein.
- ibabs WaveNet(Sprachsynthese) Tensorflow-Implementierung
- [Fast WaveNet (Sprachsynthese) Tensorflow-Implementierung von Tomlepaine] (https://github.com/ibab/tensorflow-wavenet)
Wenn Sie diesen Code nützlich finden, zitieren Sie uns bitte in Ihrer Arbeit:
Kim und Park. Speech-to-Text-WaveNet. 2016. GitHub-Repository. https://github.com/buriburisuri/.
Namju Kim (namju.kim@kakaocorp.com) bei KakaoBrain Corp.
Kyubyong Park (kbpark@jamonglab.com) bei KakaoBrain Corp.
Hoeun Yu (hoeuyu@ethz.ch) bei ETHZ Hörerin.