AttentionPathExplainer(APE) is a tool to help understand how GNN/BERT model makes prediction leveraging the attention mechanism.
MessagePassing is a common GNN framework expressed as a neighborhood aggregation scheme (information of each node is aggregated and updated by its neighbors in previous layer). Thus we consider model as a multi-layer structure whose all layer is of size
- For instance, applying a 3-layer GNN model to a graph with 7 nodes (left), its message flow can be modelled as a lattice (right).
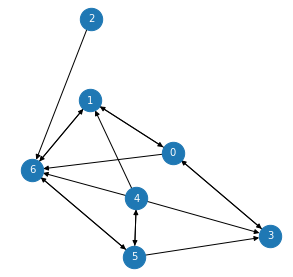 |
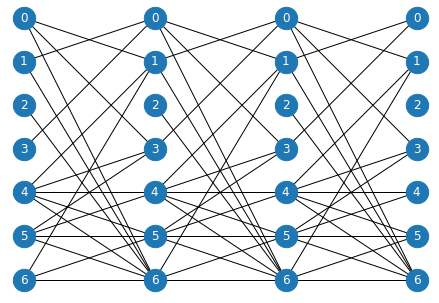 |
- If the model layer aggregates information based on attentions, using attention weights as edge weights, the lattice might look like this.
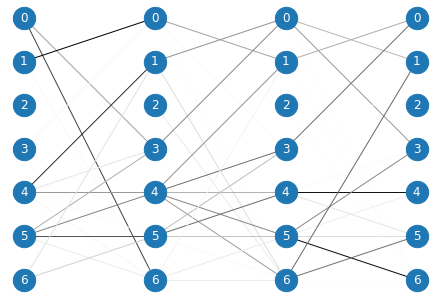
- Then we use
viterbi algorithmto get top k paths of total weights(products of edge weights on the path). The time complexity is$O(|Layer| \times |E| \times k \log |V|)$ , and space complexity is$O(k |Layer| |V|)$ .
- Since Transformer can be thought as a special case of GNN, so Transformer-based model (or any multi-layer attention model) such as BERT can also take advantage of it.
- Besides attention marchanism, other components like dense/conv/residual layers may also affect the information flow. As deep learning models are difficult to truly understand, APE is not guaranteed to make an reasonable explanation.
- Attention mechanism itself is also arguable. Attention is not Explanation and Attention is not not Explanation posed quite different arguments about the usefulness, and Synthesizer found that even fixed attention initialized at random is not useless.
-
Prerequisites
- Since APE is independent of model and learning framework, so only NetworkX is necessary to draw explanatory graphs.
-
Prepare attention weights
- Modify your model so that it returns a list of AttentionTensors
-
AttentionTensors is a tuple of (indices, attn_weights), indices is a numpy array with shape (
$|E|$ , 2), attn_weights ($|E|$ ,), representing aggregating flows of each layer - Multi-head attentions should be pooled or selected first
-
Node Classification
ex = explainer.NodeClassificationExplainer() # run viterbi algorithm, only need to be called once ex.fit(attention_tensors, topk=16) # draw subgraph of L(#layer)-hop neighbors of node 1, with edge score as weight and returns path scores ({Path: score}), Path is a tuple of node ids path_scores = ex.explain([1], visualize=True)
- e.g
-
Link Predition
ex = explainer.LinkPredictionExplainer() # run viterbi algorithm, only need to be called once ex.fit(attention_tensors, topk=16) # draw subgraph of L(#layer)-hop neighbors of node pair (1,2), with edge score as weight and returns path scores ({Path: score}), Path is a tuple of node ids path_scores = ex.explain((1, 2), visualize=True)
- e.g
-
BERT(Transformer-based)
tokens = ['[CLS]', 'Hello', 'world', '[SEP]'] logits, attentions = model(**inputs) attentions = [_.squeeze().permute(1, 2, 0).numpy() for _ in attns] # [#tokens, #tokens, #heads] ex = explainer.BERTExplainer('seq_cls') # task type, seq_cls or token_cls ex.explain(tokens, attentions, show_sep=False, topk=32, visualize=True)
- e.g
it's just incredibly dull.
- e.g
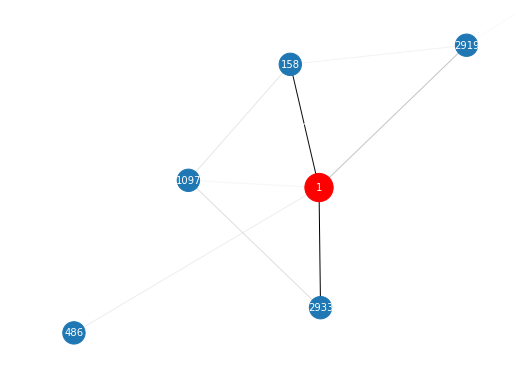
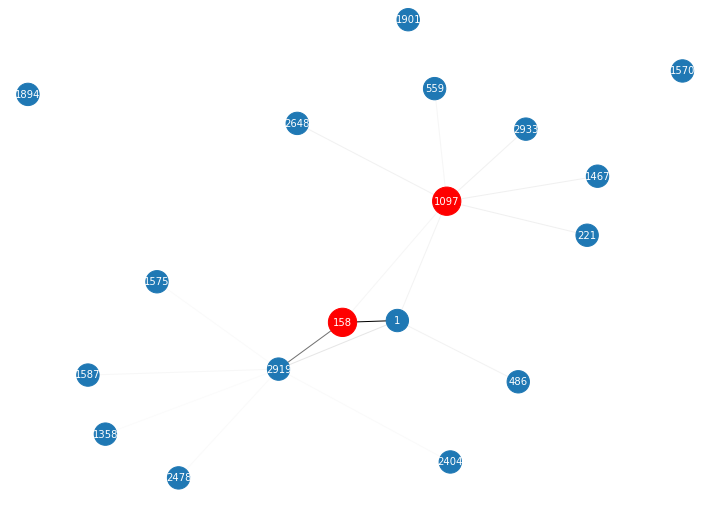

- More test cases can be found in
examples.node_classification.ipynbandlink_prediction.ipynbdo experiments using pytorch_geometric as GNN framework.BERT_sequence_classification.ipynbgives some cases in sentiment analysis task using BERT.
- Prettify graph visualization
- Edge and path score renormalization
- Node labels (currently only shows ids)