Le projet DGML vise à la construction d'un catalogue de jeux de données de data.gouv.fr pour le Machine Learning.
🔗 datascience.etalab.studio/dgml/
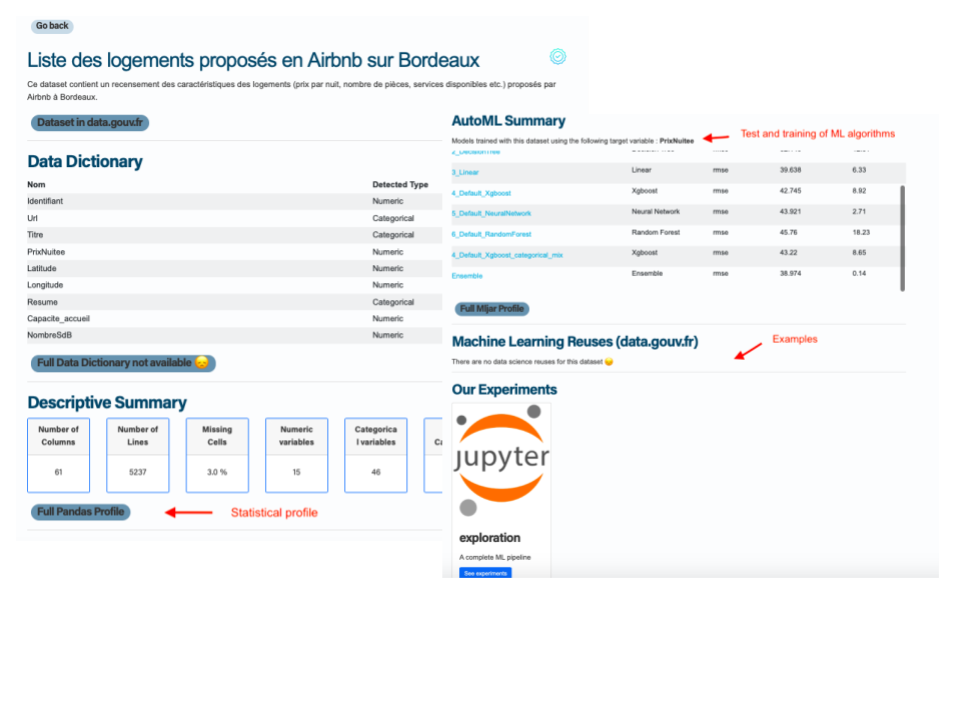
Parmi le grand nombre de données ouvertes disponibles sur data.gouv.fr, il peut s'avérer difficile de trouver rapidement des jeux de données réutilisables par des algorithmes de ML et de déterminer si elles seraient adaptées à cette tâche. Dans DGML, vous pouvez rapidement séléctionner un jeu de données de data.gouv.fr pour le Machine Learning et avoir un aperçu rapide des informations utiles pour faire du Machine Learning sur ce jeu de données.
- 60 jeux de données réutilisables par des algorithmes de ML (cliquez ici pour avoir plus d'informations sur le choix des datasets), que vous pouvez trier par tâche (régression ou classification), par taille etc.
Pour chaque jeux de données vous trouvez:
-
Un profiling statistique , qui vous donne des infos sur les statistiques du jeu de données, la distribution de ses variables et des valeurs manquantes et les corrélations
-
Les résultats de l'entraînement et de la validation automatique d'algorithmes de ML sur ces datasets (cliquez ici pour mieux comprendre ces résultats)
-
Des exemples simples de code et les réutilisations faites sur data.gouv.fr
- Cloner/Forker le repo (plus d'info ici)
- Une fois dans le repo, installer les requirements à partir du fichier
requirements.txt:- Avec pip:
pip install -r requirements.txt - Avec conda:
conda env create --name envname --file=environment.yml
- Avec pip:
- Activer l'environnement
Pour lancer l'application, depuis votre ligne de commande, à la racine:
cd openml_app
python main.py
- pandas profiling pour le profiling statistique
- mljar-supervised pour l'entraînement et test automatique des algortihmes de Machine Learning