

Waterdrop 是一个非常易用,高性能、支持实时流式和离线批处理的海量数据处理产品,架构于Apache Spark 和 Apache Flink之上。
请点击进入快速入门:https://interestinglab.github.io/waterdrop-docs/#/zh-cn/v1/quick-start
Waterdrop 提供可直接执行的软件包,没有必要自行编译源代码,下载地址:https://github.com/InterestingLab/waterdrop/releases
文档地址:https://interestinglab.github.io/waterdrop-docs/
各种线上应用案例,请见: https://interestinglab.github.io/waterdrop-docs/#/zh-cn/v1/case_study/
如果你遇到任何问题,请联系项目负责人 Gary(微信: garyelephant) , RickyHuo(微信: chodomatte1994),加微信备注"waterdrop",我们把你拉到Waterdrop & Spark & Flink 交流群里,并为你提供全程免费服务,你也可以与其他伙伴交流大数据技术。扫码加我,拉你入群:

想了解Waterdrop的设计与实现原理,请查看视频:https://time.geekbang.org/dailylesson/detail/100028486
Databricks 开源的 Apache Spark 对于分布式数据处理来说是一个伟大的进步。我们在使用 Spark 时发现了很多可圈可点之处,同时我们也发现了我们的机会 —— 通过我们的努力让Spark的使用更简单,更高效,并将业界和我们使用Spark的优质经验固化到Waterdrop这个产品中,明显减少学习成本,加快分布式数据处理能力在生产环境落地。
除了大大简化分布式数据处理难度外,Waterdrop尽所能为您解决可能遇到的问题:
- 数据丢失与重复
- 任务堆积与延迟
- 吞吐量低
- 应用到生产环境周期长
- 缺少应用运行状态监控
"Waterdrop" 的中文是“水滴”,来自**当代科幻小说作家刘慈欣的《三体》系列,它是三体人制造的宇宙探测器,会反射几乎全部的电磁波,表面绝对光滑,温度处于绝对零度,全部由被强互作用力紧密锁死的质子与中子构成,无坚不摧。在末日之战中,仅一个水滴就摧毁了人类太空武装力量近2千艘战舰。
- 海量数据ETL
- 海量数据聚合
- 多源数据处理
- 简单易用,灵活配置,无需开发
- 实时流式处理
- 离线多源数据分析
- 高性能
- 海量数据处理能力
- 模块化和插件化,易于扩展
- 支持利用SQL做数据处理和聚合
- 支持Spark Structured Streaming
- 支持Spark 2.x
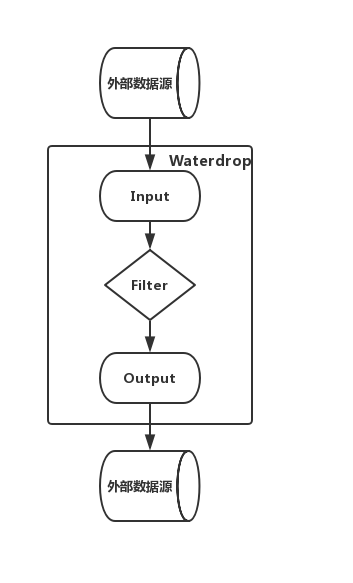
Input[数据源输入] -> Filter[数据处理] -> Output[结果输出]
多个Filter构建了数据处理的Pipeline,满足各种各样的数据处理需求,如果您熟悉SQL,也可以直接通过SQL构建数据处理的Pipeline,简单高效。目前Waterdrop支持的Filter列表, 仍然在不断扩充中。您也可以开发自己的数据处理插件,整个系统是易于扩展的。
- Input plugin
Fake, File, Hdfs, Kafka, S3, Socket, 自行开发的Input plugin
- Filter plugin
Add, Checksum, Convert, Date, Drop, Grok, Json, Kv, Lowercase, Remove, Rename, Repartition, Replace, Sample, Split, Sql, Table, Truncate, Uppercase, Uuid, 自行开发的Filter plugin
- Output plugin
Elasticsearch, File, Hdfs, Jdbc, Kafka, Mysql, S3, Stdout, 自行开发的Output plugin
-
java运行环境,java >= 8
-
如果您要在集群环境中运行Waterdrop,那么需要以下Spark集群环境的任意一种:
- Spark on Yarn
- Spark Standalone
- Spark on Mesos
如果您的数据量较小或者只是做功能验证,也可以仅使用local模式启动,无需集群环境,Waterdrop支持单机运行。
关于Waterdrop的详细文档
-
2018-09-08 Elasticsearch 社区分享 Waterdrop:构建在Spark之上的简单高效数据处理系统
-
2017-09-22 InterestingLab 内部分享 Waterdrop介绍PPT
- 微博, 增值业务部数据平台

微博某业务有数百个实时流式计算任务使用内部定制版Waterdrop,以及其子项目Guardian做Waterdrop On Yarn的任务监控。
- 新浪, 大数据运维分析平台
![]()
新浪运维数据分析平台使用waterdrop为新浪新闻,CDN等服务做运维大数据的实时和离线分析,并写入Clickhouse。
- 字节跳动,广告数据平台
![]()
字节跳动使用Waterdrop实现了多源数据的关联分析(如Hive和ES的数据源关联查询分析),大大简化了不同数据源之间的分析对比工作,并且节省了大量的Spark程序的学习和开发时间。
- 搜狗,搜狗奇点系统
![]()
搜狗奇点系统使用 waterdrop 作为 etl 工具, 帮助建立实时数仓体系
- 趣头条,趣头条数据中心
![]()
趣头条数据中心,使用waterdrop支撑mysql to hive的离线etl任务、实时hive to clickhouse的backfill技术支撑,很好的cover离线、实时大部分任务场景。
- 一下科技, 一直播数据平台
- 永辉超市子公司-永辉云创,会员电商数据分析平台
![]()
Waterdrop 为永辉云创旗下新零售品牌永辉生活提供电商用户行为数据实时流式与离线SQL计算。
- 水滴筹, 数据平台
![]()
水滴筹在Yarn上使用Waterdrop做实时流式以及定时的离线批处理,每天处理3~4T的数据量,最终将数据写入Clickhouse。
- 浙江乐控信息科技有限公司
![]()
Watedrop 为浙江乐控信息科技有限公司旗下乐控智能提供物联网交互数据实时流sql分析(Structured Streaming 引擎)和离线数据分析。每天处理的数据量8千万到一亿条数据 最终数据落地到kafka和mysql数据库。
- 上海分蛋信息科技,大数据数据分析平台
![]()
分蛋科技使用Waterdrop做数据仓库实时同步,近百个Pipeline同步处理;数据流实时统计,数据平台指标离线计算。
- 其他公司 ... 期待您的加入,请联系微信: garyelephant
Waterdrop已进入高速成长期,如果你支持此项目,请点Star.

提交问题和建议:https://github.com/InterestingLab/waterdrop/issues
贡献代码:https://github.com/InterestingLab/waterdrop/pulls
感谢所有开发者
Garyelephant : garygaowork@gmail.com, 微信: garyelephant
RickyHuo : huochen1994@163.com, 微信: chodomatte1994