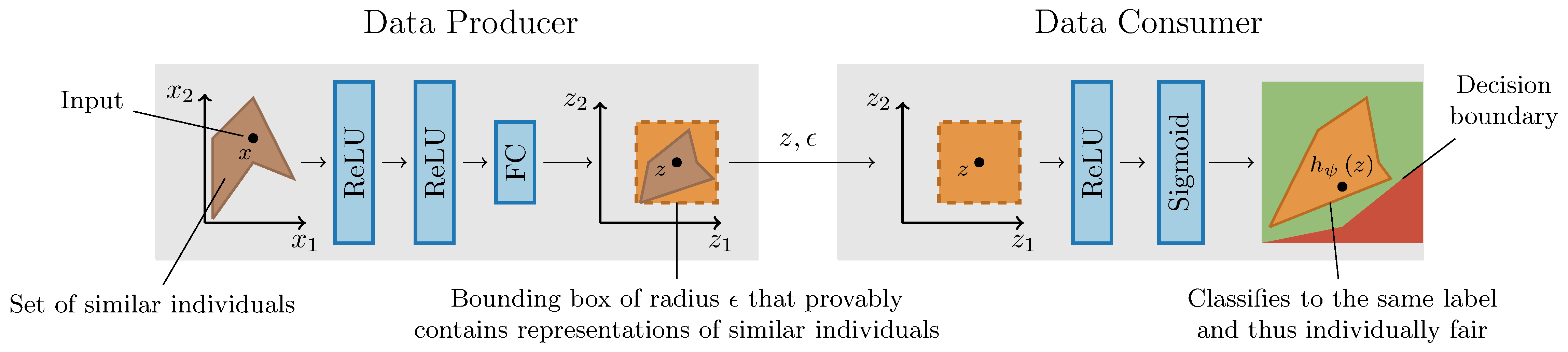
LCIFR is a state-of-the art system for training neural networks with provable certificates of individual fairness. LCIFR enables the definition of individual fairness constraints via interpretable logical formulas, enforces these constraints by mapping similar individuals close to each other in latent space, and leverages this proximity in latent space to compute certificates of equal outcome for all similar individuals.
LCIFR leverages the theoretical framework introduced by McNamara et al. which partitions the task of learning fair representations into three parties:
- data regulator: defines a fairness property for the particular task at hand
- data producer: processes sensitive user data and transforms it into a latent representation
- data consumer: performs predictions based on the new representation
The key idea behind LCIFR is to learn a representation that provably maps similar individuals to latent representations at most epsilon apart in l-infinity distance, enabling data consumers to certify individual fairness by proving epsilon-robustness of their classifier. Furthermore, LCIFR allows data regulators to define rich similarity notions via logical constraints.
This implementation of LCIFR can be used as a library compatible with PyTorch and contains all code, datasets and preprocessing pipelines necessary to reproduce the results from our NeurIPS 2020 paper. This system is developed at the SRI Lab, Department of Computer Science, ETH Zurich as part of the Safe AI project.
Clone this repository and its dependencies
$ git clone --recurse-submodules https://github.com/eth-sri/lcifr.gitCreate a conda environment with the required packages
$ conda env create -f environment.ymlWe use the GUROBI solver for certification. To run our code, apply for and download an academic GUROBI License.
.
├── README.md - this file
├── code
│ ├── attacks - for adversarial training
│ ├── constraints - data regulator: individual fairness notions
│ ├── datasets - downloads and preprocesses datasets
│ ├── experiments
│ │ ├── args_factory.py - defines training parameters
│ │ ├── certify.py - runs end-to-end certification
│ │ ├── train_classifier.py - data consumer: trains model
│ │ └── train_encoder.py - data producer: learns representation
│ ├── metrics - group/individual fairness metrics
│ ├── models - model architectures
| └── utils
├── data - created when running experiments
├── dl2 - dependency
├── models - created when running experiments
├── logs - created when running experiments
├── results - created when running experiments
|── environment.yml - conda environment
└── setup.sh - activates conda environment and sets paths
Some files omitted.
Activate the conda environment and set the PYTHONPATH
$ source setup.shEnter the experiments directory
$ cd code/experimentsRun the end-to-end framework for all constraints
$ ./noise.sh
$ ./cat.sh
$ ./cat_noise.sh
$ ./attribute.sh
$ ./quantiles.shThe trained models, logs and certification results are stored in the
directories models, logs and results respectively under project root.
Once started, the training progress can be monitored in Tensorboard with
$ tensorboard --logdir logsIn a similar way, the experiments on transfer learning can be reproduced with
$ cd code/experiments
$ ./transfer.sh@inproceedings{ruoss2020learning,
title = {Learning Certified Individually Fair Representations},
author = {Ruoss, Anian and Balunovic, Mislav and Fischer, Marc and Vechev, Martin},
booktitle = {Advances in Neural Information Processing Systems 33},
year = {2020}
}
- Anian Ruoss (anruoss@ethz.ch)
- Mislav Balunović
- Marc Fischer
- Martin Vechev
- Copyright (c) 2020 Secure, Reliable, and Intelligent Systems Lab (SRI), ETH Zurich