20Q-selfplay
LLM play 20questions with itself. Browse the dataset here : https://evanthebouncy.github.io/20Q-selfplay/
Tested on 1823 hypotheses from the THINGS dataset, llm = OpenAI(model_name="gpt-3.5-turbo-0301"), score of 68 / 1823.
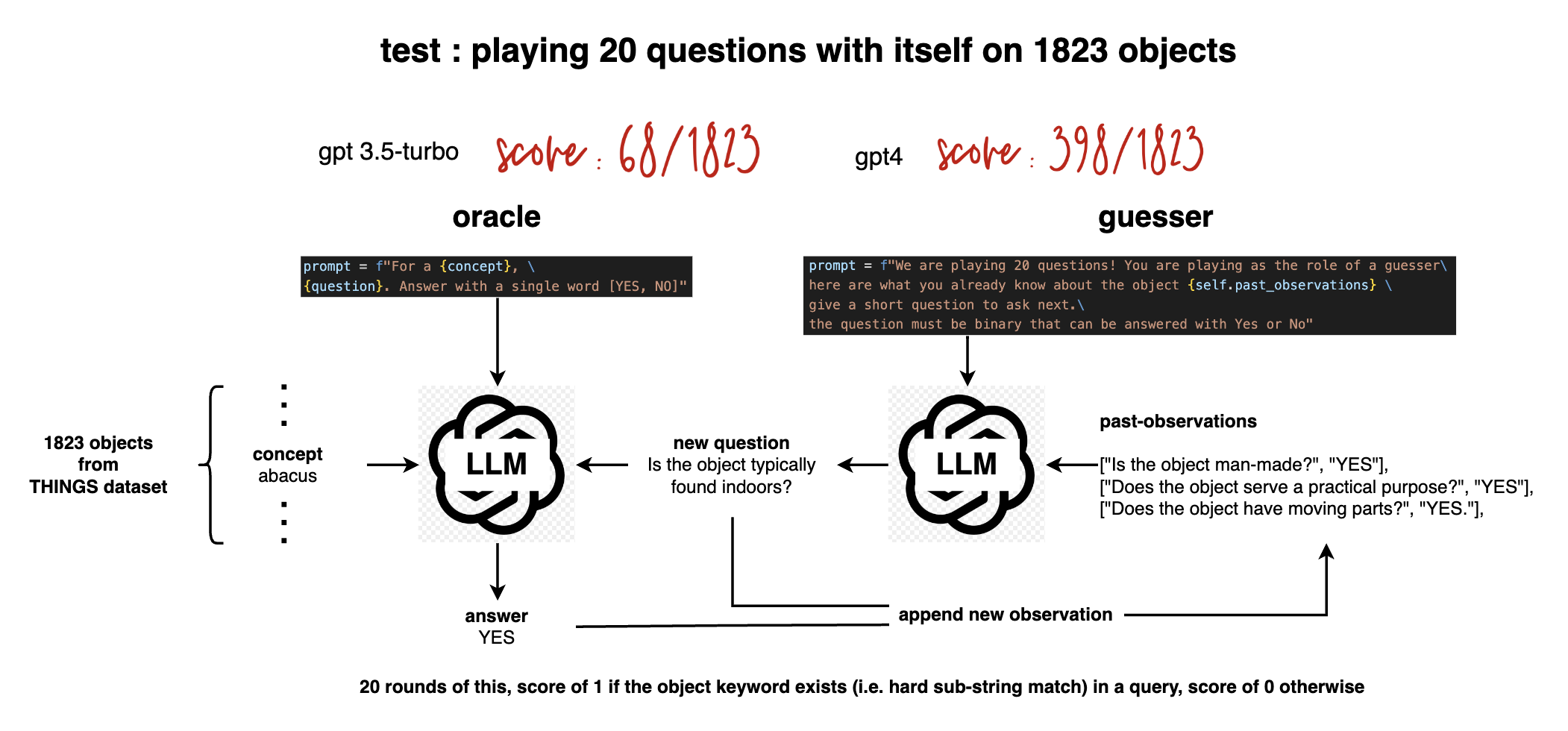
Original 1854 objects de-duplicated: bat(animal) and bat(sport tool) collapsed into 1 concept.
The scoring of success / fail needs more work, as currently it'll count a query ""Is the object smaller than a breadbox?" as being successful in guessing the concept "bread". Conversely, if the guesser had used the word "bouguetteux" it would've been counted as incorrect, even though conceptually it is also "bread" except with some errors.
Read the blog for full details:
https://evanthebouncy.medium.com/llm-self-play-on-20-questions-dee7a8c63377
20Questions is also explored in BIG-bench (albeit with only 40 objects):
https://github.com/google/BIG-bench/tree/main/bigbench/benchmark_tasks/twenty_questions

2023-03-27