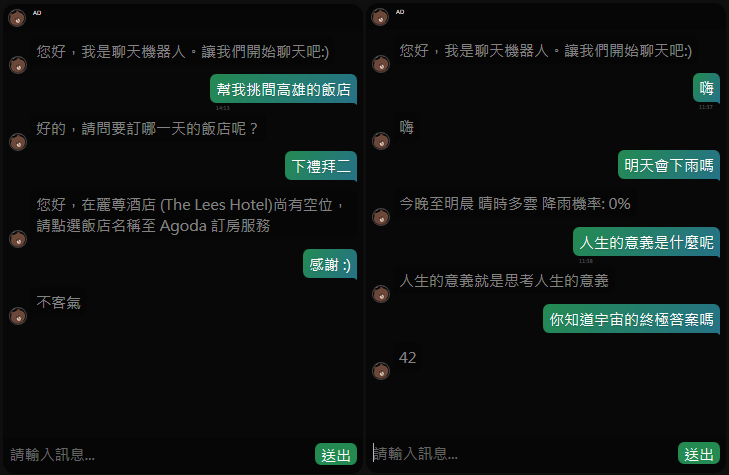
Mianbot 是採用樣板與檢索式模型搭建的聊天機器人,目前有兩種產生回覆的方式,專案仍在開發中:)
- 其一(左圖)是以詞向量進行短語分類,針對分類的目標模組實現特徵抽取與記憶回覆功能,以進行多輪對話,匹配方式可參考Semantic Graph(目前仍在施工中 ΣΣΣ (」○ ω○ )/)。
- 其二(右圖)除了天氣應答外,主要是以 PTT Gossiping 作為知識庫,透過文本相似度的比對取出與使用者輸入最相似的文章標題,再從推文集內挑選出最為可靠的回覆,程式內容及實驗過程請參見PTT-Chat_Generator。
更多的樣例可以參照 example/output.txt
輸入:明天早上叫我起床。
| 相似度 | 概念 | 匹配元 |
|---|---|---|
| 0.4521 | 鬧鐘 | 起床 |
| 0.3904 | 天氣 | 早上 |
| 0.3067 | 住宿 | 起床 |
| 0.1747 | 病症 | 起床 |
| 0.1580 | 購買 | 早上 |
| 0.1270 | 股票 | 早上 |
| 0.1096 | 觀光 | 早上 |
輸入:明天上海會不會下雨?
| 相似度 | 概念 | 匹配元 |
|---|---|---|
| 0.5665 | 天氣 | 下雨 |
| 0.3918 | 鬧鐘 | 下雨 |
| 0.1807 | 病症 | 下雨 |
| 0.1362 | 住宿 | 下雨 |
| 0.0000 | 股票 | |
| 0.0000 | 觀光 | |
| 0.0000 | 購買 |
- 安裝 python3 開發環境
- 安裝 gensim – Topic Modelling in Python
- 安裝 jieba 结巴中文分词
- 有已訓練好的中文詞向量,並根據檔案位置調整
Console class的初始化參數。
import Chatbot.console as console
c = console.Console(model_path='your_model')- 如要使用 QA 模組,請先依照問答測試用資料集進行配置,或透過將
chatbot.py中的self.github_qa_unupdated設為True選擇關閉 QA 模組
import Chatbot.chatbot as chatbot
chatter = chatbot.Chatbot(w2v_model_path='your_model')
chatter.waiting_loop()import Chatbot.console as console
c = console.Console(model_path='your_model')
speech = input('Input a sentence:')
res,path = c.rule_match(speech)
c.write_output(speech,res,path)規則採用 json 格式,樣板規則放置於\RuleMatcher\rule中,
{
"domain": "代表這個規則的抽象概念",
"response": [
"對應到該規則後",
"機器人所會給予的回覆",
"機器人會隨機抽取一條 response"
],
"concepts": [
"該規則的可能表示方式"
],
"children": ["該規則的子規則","如購買 -> 購買飲料,購買衣服......"]
} {
"domain": "購買",
"response": [
"正在將您導向購物模組"
],
"concepts": [
"購買","購物","訂購"
],
"children": [
"購買生活用品",
"購買家電",
"購買食物",
"購買飲料",
"購買鞋子",
"購買衣服",
"購買電腦產品"
]
},請點擊這裡下載部分測試用資料集,內容包含了 PTT C_Chat、Gossiping 版非新聞類問答約 250,000 則。檔案解壓縮後請放置於 QuestionAnswering/data/ 資料夾下,reply.rar 解壓縮後的資料夾請放置於 QuestionAnswering/data/processed 下:
QuestionAnswering
└── data
├── SegTitles.txt
├── processed
│ └── reply
│ ├── 0.json
│ ├── .
│ ├── .
│ ├── .
│ └── xxx.json
└── Titles.txt
完成配置後,可以將chatbot.py 中的 self.github_qa_unupdated 設為 False 打開問答模組進行測試。
- 網路探勘暨跨語知識系統實驗室
- 智慧型知識管理實驗室
- Legoly
- 給予我協助與交流的每名朋友