Exasol recommends using PyEXASOL unless you need functionality specifically available in this package

Please note that this is an open source project which is officially supported by EXASOL. For any question, you can contact our support team.
The EXASolution Python Package offers functionality to interact with the EXASolution database out of Python scripts. It is developed as a wrapper around PyODBC and extends PyODBC in two main aspects:
-
It offers fast data transfer between EXASolution and Python, multiple times faster than PyODBC. This is achieved by using a proprietary transfer channel which is optimized for batch loading. Please read the Python help of exasol.readData() and exasol.writeData() for more details and read the documentation below.
-
It makes it convenient to run parts of your Python code in parallel on the EXASolution database, using EXASolution Python UDF scripts behind the scenes. For example you can define an Python function and execute it in parallel on different groups of data in an EXASolution table. Please read the Python help of exasol.createScript() function for more details and read the documentation below.
-
Make sure you have unixODBC installed. You can download it here
-
Install EXASolution ODBC and configure it on your system. We recommand you to create a DSN pointing to your database instance. EXASolution ODBC can be downloaded here. instance. Read the README.txt of the EXASolution ODBC driver package for details.
-
Install a recent version of the PyODBC package.
pip install pyodbc
- Install a recent version of the Pandas package.
pip install pandas
- Install the EXASolution Python package Clone or download the EXASolution Python package repository. Then execute the following command:
python setup.py install --prefix=<path_to_python_package_installation_location>
- Set environment variable and start python
export LD_LIBRARY_PATH=<path_to_unix_odbc_installation>/lib
export ODBCINI=<path_to_the_directory_with_odbc_ini>/odbc.ini
export ODBCSYSINI=<path_to_the_directory_with_odbc_ini>
- Start python by using the EXASolution Python package which you installed in step 5
PYTHONPATH=<path_to_python_package_installation_location>/lib/python2.7/site-packages python
-
Make sure you have the Exasol ODBC driver installed. You can download it on the Exasol website. On the webpage, select a main version on the left side, e.g. 6.0. Scroll down to the section
Download ODBC Driverand download the corresponding msi, eihter x86 or x86_64. Install it on your system. Press the windows-key and type inODBC. Then select ODBC-Datasources (64 Bit) or ODBC-Datasources (32 Bit), depending on the driver you just installed. Click on
Click on Addand select EXASolution Driver. Fill out the given form (see picture). Remember the name you give to your datasource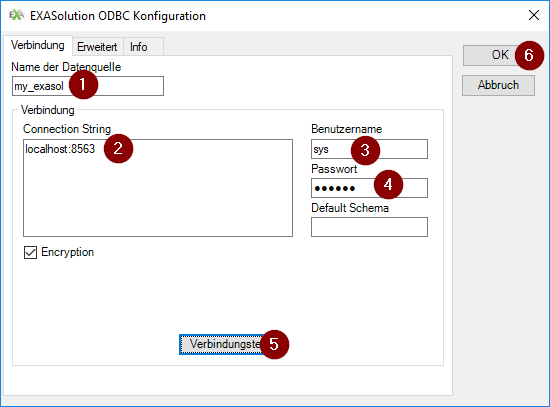
-
Install a recent version of the PyODBC package.


pip install pyodbc
- Install a recent version of the Pandas package.
pip install pandas
- Install the EXASolution Python package Clone or download the EXASolution Python package repository. Navigate to the folder in your command line. Then execute the following command:
python setup.py install --prefix=<path_to_python_package_installation_location>
- Start your python and test the connection:
import exasol as E
C = E.connect(dsn='my_exasol')
R = C.readData("SELECT 'connection works' FROM dual")
print(R)
If you get an error like this while testing, you should try the 32 Bit version of the ODBC driver instead
pyodbc.Error: ('IM014', u'[IM014] [Microsoft][ODBC Driver Manager]
To use the package import it with a handy name:
import exasol as E
You can than read the documentation of this package with:
help(E)
The E.connect function has the same arguments, like
pyodbc.connect, with some additions. Please refer the PyODBC
documentation for connection parameters. To use it with EXASolution,
following arguments are possible:
Assuming you have a DSN pointing to your database instance you can connect like this:
C = E.connect(dsn='YourDSN')
Alternatively if you don't have a DSN you can also specify the required information in the connection string:
C = E.connect(Driver = 'libexaodbc-uo2214.so',
... EXAHOST = 'exahost:8563',
... EXAUID = 'sys',
... EXAPWD = 'exasol')
The resulting object supports with statement, so the C.close function is called automatically on leaving the scope.
The connection object has along with all PyODBC methods also a
readData method, which executes the query through PyODBC but
receive the resulting data faster and in different formats. Currently
supported are Pandas and CSV, but it is possible to define arbitrary
reader functions. This function will be called inside of readData
with a file descriptor as argument, where the result need to be read
as CSV.
To use this function call it with the SQL:
R = C.readData("SELECT * FROM MYTABLE")
print(R)
The result type is a Pandas data frame per default. You can use a different callback function using the argument readCallback, for example you can use the predefined csvReadCallback to receive the results formatted as CSV:
R = C.readData("SELECT * FROM MYTABLE", readCallback = E.csvReadCallback)
print(R)
We also offer an explicit function to read as CSV:
R = C.readCSV("SELECT * FROM MYTABLE")
print(R)
You can also change the default return type to CSV for the whole connection using the following argument:
C = E.connect(dsn="YourDSN", useCSV=True)
With the function "C.writeData" python data can be transferred to EXASolution database. R stores the content of MYTABLE and is then transferred to a pandas dataframe. By calling the function "C.writeData" the content of MYTABLE will saved in R in form of pandas dataframe.
import pandas as pd
R = C.readData("SELECT * FROM MYTABLE")
df = pd.DataFrame(R)
C.writeData(R, table = 'mytable')
print(R)
The data will be simply appended to the given table. Similar to readData, the default format is a pandas data frame, which can be changed using the writeCallback parameter or the explicit version:
C.writeCSV(R, table = 'mytable')
With the function decorator createScript it is possible, to
declare python functions as EXASolution UDF scripts:
@C.createScript(inArgs = [('a', E.INT)],
... outArgs = [('b', E.INT), ('c', E.INT)])
... def testScript(data):
... print "process data", repr(ftplib)
... while True:
... data.emit(data.a, data.a + 3)
... if not data.next(): break
... print "all data processed"
This script will be immediatly created on the EXASolution database as
a UDF script and the local testScript function will be
replaced with a C.readData call, so that to execute the computation
on EXASolution you call this function simply as follows:
testScript('columnA', table = 'testTable', groupBy = 'columnB')
This call executes a SELECT SQL query using the C.readData function
and returns the result. The query will group by columnB and aggregate on
the columnA column using the testScript function.
Per default, functions are created as SET EMITS UDFs. We recommend to read the EXASolution manual about UDF scripts for a better understanding.
Internally the decorated function will be compiled and serialized with
the marshall Python module locally and created on the EXASolution
side, so that this function has no access to the local environment
anymore. To initialize the environment, it is possible to pass the
initFunction argument of the decorator, which initializes the
environment on the EXASolution side. It happens every time the module
is loaded, so that this function is recreated in the database on
module loading.