The Emotions of the Crowd: Learning Image Sentiment from Tweets via Cross-modal Distillation
Introduction
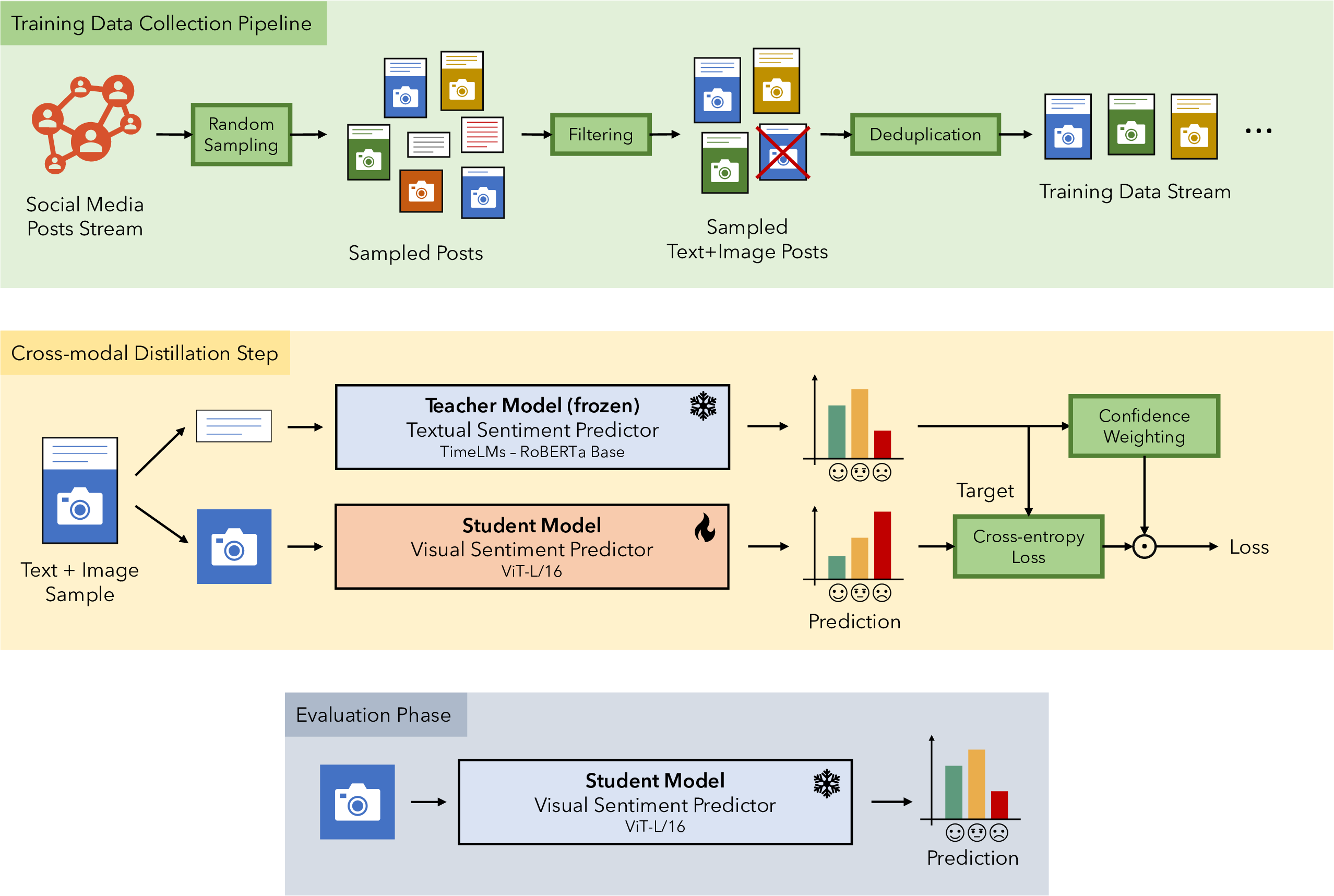
This work introduced a cross-modal learning method to train visual models for Sentiment Analysis in the Twitter domain.
It was used to fine-tune the Vision-Transformer (ViT) model pre-trained on Imagenet-21k, which was able to achieve incredible results on external benchmarks which were manually annotated, even beating the current State Of The Art!
We crawled ∼3.7 pictures from social media from 1 April to 30 June to use them in our cross-modal approach. In particular, a cross-modal teacher-student learning technique was used to avoid human annotators, thus minimizing the efforts required and allowing for the creation of vast training sets.
The latter can help future research to train robust visual models, as the number of parameters of current SOTA is exponentially growing along with their need of data to avoid overfitting problems.
Build Instructions
Clone codebase
$ git config --global http.postBuffer 1048576000
$ git clone --recursive https://github.com/fabiocarrara/cross-modal-visual-sentiment-analysis/tree/master
Install dependencies
$ chmod +x install_dependencies.sh
$ ./install_dependencies.sh
How to use the scripts for benchmark evaluation
Test a model with a benchmark, get the accuracy and save the prediction
$ python3 scripts/test_benchmark.py -m <model_name> -b <benchmark_name>
$ options for <model_name>: [boosted_model, ViT_L16, ViT_L32, ViT_B16, ViT_B32, merged_T4SA, bal_flat_T4SA2.0, bal_T4SA2.0, unb_T4SA2.0, B-T4SA_1.0_upd_filt, B-T4SA_1.0_upd, B-T4SA_1.0]
$ options for <benchmark_name>: [5agree, 4agree, 3agree, FI_complete, emotion_ROI_test, twitter_testing_2]
Execute a five fold cross validation on a benchmark, get the mean accuracy, the standard deviation and save the predictions (by default use the boosted_model)
$ python3 scripts/5_fold_cross.py -b <benchmark_name>
Fine tune FI on the five split, get the mean accuracy, the standard deviation and save the predictions (by default use the boosted_model)
$ python3 scripts/fine_tune_FI.py
Trained Models
| Confidence Filter Threshold | Accuracy on Twitter Dataset (TD) | |||||||
|---|---|---|---|---|---|---|---|---|
| Label | Dataset | Pos | Neu | Neg | Student Arch | 5 agree |
|
|
| Model 3.1 | A | - | - | - | B/32 | 82.2 | 78.0 | 75.5 |
| Model 3.2 | A | 0.70 | 0.70 | 0.70 | B/32 | 84.7 | 79.7 | 76.6 |
| Model 3.3 | B | 0.70 | 0.70 | 0.70 | B/32 | 82.3 | 78.7 | 75.3 |
| Model 3.4 | B | 0.90 | 0.90 | 0.70 | B/32 | 84.4 | 80.3 | 77.1 |
| Model 3.5 | A+B | 0.90 | 0.90 | 0.70 | B/32 | 86.5 | 82.6 | 78.9 |
| Model 3.6 | A+B | 0.90 | 0.90 | 0.70 | L/32 | 85.0 | 82.4 | 79.4 |
| Model 3.7 | A+B | 0.90 | 0.90 | 0.70 | B/16 | 87.0 | 83.1 | 79.4 |
| Model 3.8 | A+B | 0.90 | 0.90 | 0.70 | L/16 | 87.8 | 84.8 | 81.9 |
Data
COMING SOON
BibTeX
@article{serra2023emotions,
author = {Serra, Alessio and Carrara, Fabio and Tesconi, Maurizio and Falchi, Fabrizio},
title = {The Emotions of the Crowd: Learning Image Sentiment from Tweets via Cross-modal Distillation},
journal = {ECAI},
year = {2023},
}