

![]()
Credential Digger
Credential Digger is a GitHub scanning tool that identifies hardcoded credentials (Passwords, API Keys, Secret Keys, Tokens, personal information, etc), filtering the false positive data through machine learning models.
- Why
- Requirements
- How to run
- Docker container
- Advanced install
- Python library usage
- CLI - Command Line Interface
- Wiki
- Contributing
- News
Why
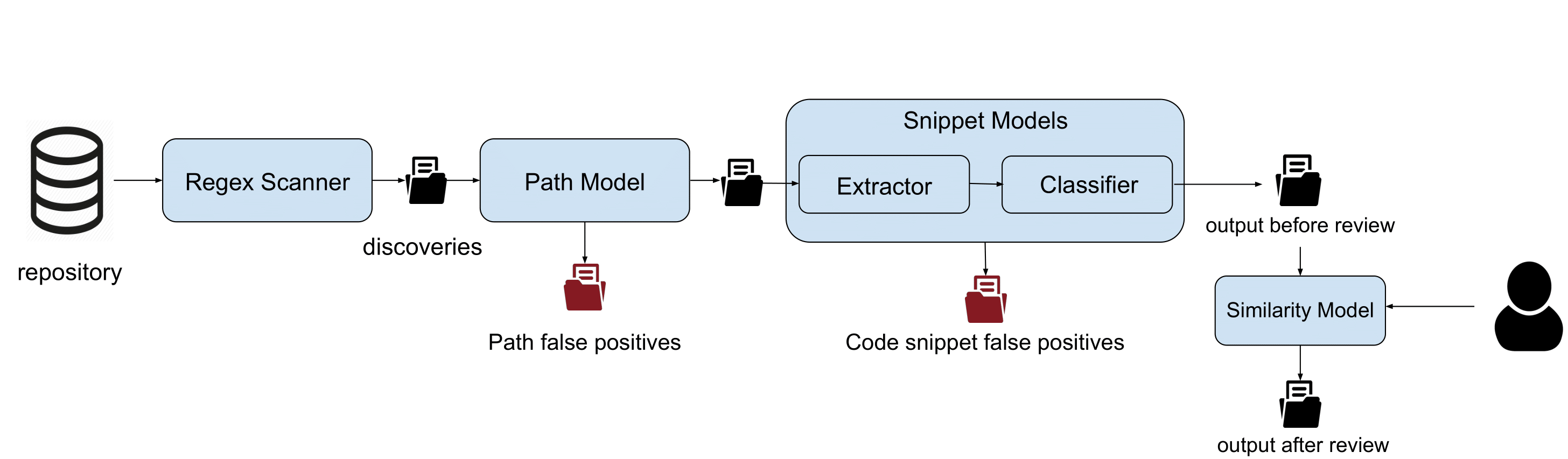
In data protection, one of the most critical threats is represented by hardcoded (or plaintext) credentials in open-source projects. Several tools are already available to detect leaks in open-source platforms, but the diversity of credentials (depending on multiple factors such as the programming language, code development conventions, or developers' personal habits) is a bottleneck for the effectiveness of these tools. Their lack of precision leads to a very high number of pieces of code incorrectly detected as leaked secrets. Data wrongly detected as a leak is called false positive data, and compose the huge majority of the data detected by currently available tools.
The goal of Credential Digger is to reduce the amount of false positive data on the output of the scanning phase by leveraging machine learning models.
Requirements
Credential Digger supports Python >= 3.6 and < 3.9, and works only with LINUX systems (currently, it has been tested on Ubuntu). In case you don't meet these requirements, you may consider running a Docker container (that also includes a user interface).
How to run
Install dependencies
First, you need to install the regular expression matching library Hyperscan. Be sure to have build-essential and python3-dev too.
sudo apt install -y libhyperscan-dev build-essential python3-devThen, you can install Credential Digger module using pip.
pip install credentialdiggerAdd rules
One of the core components of Credential Digger is the regular expression scanner. You can choose the regular expressions rules you want (just follow the template here). We provide a list of patterns in the rules.yml file, that are included in the UI.
Before the very first scan, you need to add the rules that will be used by the scanner. This step is only needed once.
python -m credentialdigger add_rules --sqlite /path/to/data.db /path/to/rules.yamlInstall machine learning models
Credential Digger leverages machine learning models to filter false positives, especially in the identification of passwords:
-
Path Model: A lot of fake credentials reside in example files such as documentation, examples or test files, since it is very common for developers to provide test code for their projects. The Path Model analyzes the path of each discovery and classifies it as false positive when needed.
-
Snippet Model: Identify the portion of code used to authenticate with passwords, and distinguish between real and dummy passwords. This model is composed of a pre-processing step (Extractor) and a classification step (Classifier).
To install the models, you first need to export them as environment variables, and them download them:
export path_model=https://github.com/SAP/credential-digger/releases/download/PM-v1.0.1/path_model-1.0.1.tar.gz
export snippet_model=https://github.com/SAP/credential-digger/releases/download/SM-v1.0.0/snippet_model-1.0.0.tar.gz
python -m credentialdigger download path_model
python -m credentialdigger download snippet_modelWARNING: Don't run the download command from the installation folder of credentialdigger in order to avoid errors in linking.
WARNING: We provide the pre-trained models, but we do not guarantee the efficiency of these models. If you want more accurate machine learning models, you can train your own models (just replace the binaries with your own models) or use the fine-tuning option.
Scan a repository
After adding the rules, you can scan a repository:
python -m credentialdigger scan https://github.com/user/repo --sqlite /path/to/data.dbMachine learning models are not mandatory, but highly recommended in order to reduce the manual effort of reviewing the result of a scan:
python -m credentialdigger scan https://github.com/user/repo --sqlite /path/to/data.db --models PathModel SnippetModelDocker container
To have a ready-to-use instance of Credential Digger, with a user interface, you can build the docker container. This option requires the installation of Docker and Docker Compose.
git clone https://github.com/SAP/credential-digger.git
cd credential-digger
cp .env.sample .env
sudo docker-compose up --buildThe UI is available at http://localhost:5000/
Advanced Install
Credential Digger is modular, and offers a wide choice of components and adaptations.
Build from source
After installing the dependencies listed above, you can install Credential Digger as follows.
Configure a virtual environment for Python 3 (optional) and clone the main branch of the project:
virtualenv --system-site-packages -p python3 ./venv
source ./venv/bin/activate
git clone https://github.com/SAP/credential-digger.git
cd credential-diggerInstall the requirements from requirements.txt file and install the library:
pip install -r requirements.txt
python setup.py installThen, you can add the rules, install the machine learning libraries, and scan a repository as described above.
External postgres database
Another ready-to-use instance of Credential Digger with the UI, but using a dockerized postgres database instead of a local sqlite one:
git clone https://github.com/SAP/credential-digger.git
cd credential-digger
cp .env.sample .env
vim .env # set credentials for postgres
sudo docker-compose -f docker-compose.postgres.yml up --buildWARNING: Differently from the sqlite version, here we need to configure the
.envfile with the credentials for postgres (by modifyingPOSTGRES_USER,POSTGRES_PASSWORDandPOSTGRES_DB).
Most advanced users may also wish to use an external postgres database instead of the dockerized one we provide in our docker-compose.postgres.yml.
Python library usage
When installing credentialdigger from pip (or from source), you can instantiate the client and scan a repository.
Instantiate the client proper for the chosen database:
# Using a Sqlite database
from credentialdigger import SqliteClient
c = SqliteClient(path='/path/to/data.db')
# Using a postgres database
from credentialdigger import PgClient
c = PgClient(dbname='my_db_name',
dbuser='my_user',
dbpassword='my_password',
dbhost='localhost_or_ip',
dbport=5432)Add rules
Add rules before launching your first scan.
c.add_rules_from_file('/path/to/rules.yml')Scan a repository
new_discoveries = c.scan(repo_url='https://github.com/user/repo',
models=['PathModel', 'SnippetModel'],
debug=True)WARNING: Make sure you add the rules before your first scan.
WARNING: Make sure you download the models before using them in a scan.
Please refer to the Wiki for further information on the arguments.
Fine-tuning
Credential Digger offers the possibility to fine-tune the snippet model, by retraining a model on each repository scanned.
If you want to activate this option, set generate_snippet_extractor=True and enable the SnippetModel when you scan a repository. You need to install the snippet model before using the fine-tuning option.
new_discoveries = c.scan(repo_url='https://github.com/user/repo',
models=['PathModel', 'SnippetModel'],
generate_snippet_extractor=True,
debug=True)CLI - Command Line Interface
Credential Digger also offers a simple CLI to scan a repository. The CLI supports both sqlite and postgres databases. In case of postgres, you need either to export the credentials needed to connect to the database as environment variables or to setup a .env file. In case of sqlite, the path of the db must be passed as argument.
Refer to the Wiki for all the supported commands and their usage.
Wiki
For further information, please refer to the Wiki
Contributing
We invite your participation to the project through issues and pull requests. Please refer to the Contributing guidelines for how to contribute.