This tool serves those who have, or work for someone who owns, a facebook page, and essentially want to know what the people are talking about in their post.
A simple front-end which can be used to run a basic, yet simple, keywords extraction on facebook posts. In addition, it employs spaCy default models to extract named-entities from comments. Visit spaCy page to know more about named entities. This tool is pretty much a word counter that employs standard NLP pre-processing, plus the NER part performed by spaCy.
It brings up a webapp supported by a python back-end which is a taylored version of whats-the-topic. It requires an access token to get people's comments on a selected post. Additional info on how to get a token can be found at this link. In short, once a facebook developers account has been created, the access token can be generated through the Facebook GraphAPI.
The tool performs text preprocessing (tokenization, stopwords filtering, stemming)
to make plots of the keyword-count plus a word cloud image - using the awesome
word_Cloud library.
This tool has been developed on Ubuntu 18.04 and macOS High Sierra, but
has never been seriously tested.
It requires Python3+ and all the packages listed in requirements.txt.
Here there are two images of the keyword-count bar plot, and the wordcloud, that are produced by running the tool on this post:
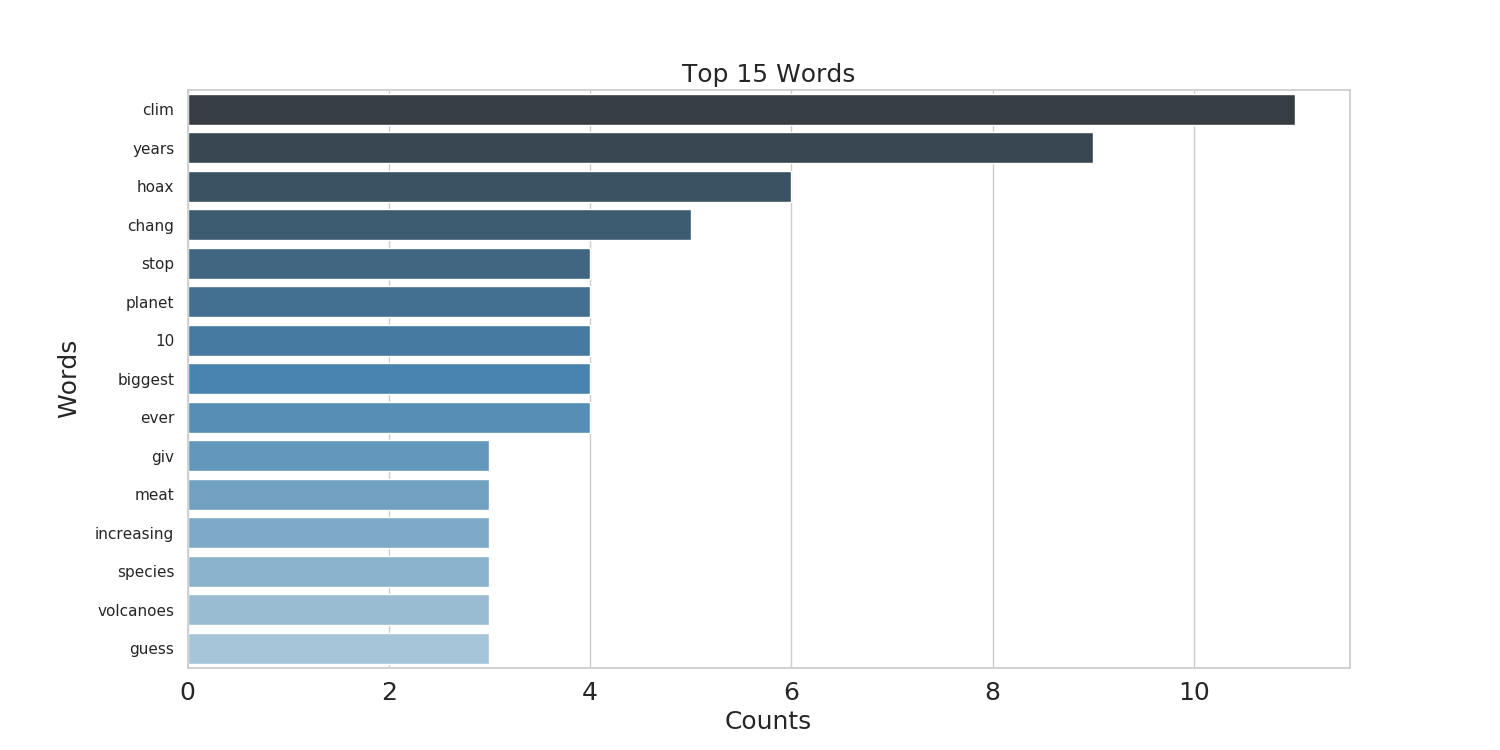
The data
| word | count |
|---|---|
| clim | 11 |
| years | 9 |
| hoax | 6 |
| chang | 5 |
| stop | 4 |
| planet | 4 |
| 10 | 4 |
| biggest | 4 |
| ever | 4 |
| giv | 3 |
| meat | 3 |
| increasing | 3 |
| species | 3 |
| volcanoes | 3 |
| guess | 3 |
This is a bar plot of the top N entities extracted from this post
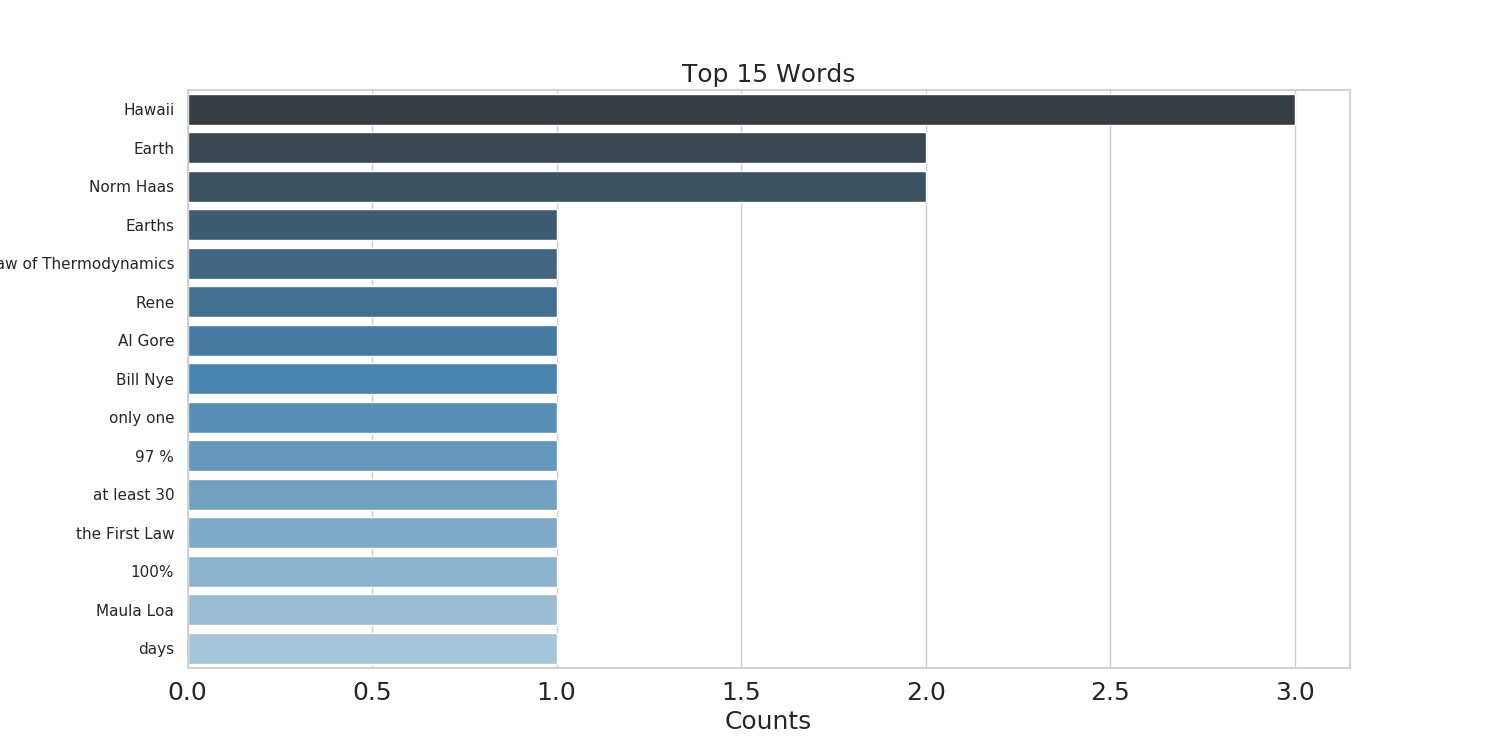
The data
| entities | count |
|---|---|
| Hawaii | 3 |
| Earth | 2 |
| Norm Haas | 2 |
| Earths | 1 |
| the First Law of Thermodynamics | 1 |
| Rene | 1 |
| Al Gore | 1 |
| Bill Nye | 1 |
| only one | 1 |
| 97 % | 1 |
| at least 30 | 1 |
| the First Law | 1 |
| 100% | 1 |
| Maula Loa | 1 |
| days | 1 |
| Time | 1 |
Thanks to the people at spaCy for the NE part,to the people who produced facebook-sdk for the ease of access to the data, and finally to the guys who made word_cloud for the awesome word-cloud images that can be produced.