Use machine learning to take 'better' samples!
You want to find 'interesting' things in a large population and:
- It is a very large population of 'stuff'
- A small number of things that are interesting
- The error bars associated with our sample are large relative to the interesting volume
- We have few sampled interesting examples
- It is hard to know if something is interesting - might have to use a human to evaluate it
- The population changes over time (possibly through our intervention)
Sometimes we have extra information about the population we would like to measure. In these cases, we can use this information to take a more accurate sample. A typical example of this is probability proportionate to size (PPS) sampling. Here we have information about the relative weight of each potential sample and can use that to our advantage.
What if we were determined to find the amount of 'interesting' individuals in a population? - If we had a model that produces scores that correlate with P(interesting) - we should also be able to also use this information!
We can use this information to over-sample interesting things - and then - to weight those things less for the purposes of the prevalence calculation. Record 1 - (2x oversample, 1/2 weight), Record 2 - (3x oversample, 1/3 weight) .... Record N - (1/5x oversample, 5x weight)
In many situations - this can reduce the error (bars) associated with taking the sample while providing and unbiased estimate of the prevalence of 'interesting' things.
When fighting spam, one question that is useful to answer is 'What is the overall prevalence of spam within the ecosystem?'. As we drive the overall prevalence of spam to zero we encounter some interesting measurement challenges:
- We review these items manually and thus we spend most of our time looking at good things (wasted effort).
- We may rely on the spam samples to make decisions about how to best prioritize. More spam examples helps us be more effective. A low overall prevalence means we have few examples (false negatives) to inspect.
- The error bars associated with the sampling method are large relative to the estimated percent. E.g. 1% (+/- 0.5%) vs 20% +/- 0.5%). Reducing the error bars associated with the sample helps us to be more confident in the decisions we make. This is especially important when there are large class imbalances.
- Can significantly reduce the sample variance and increase the number of 'interesting' items sampled.
- Produces unbiased estimates for the sampled population.
- Implemented leveraging existing python libraries (scipy & numpy).
We demonstrate three different methods for taking samples. In this scenario we are interested in understanding the percent of 'positive' examples in the broader population. Each method has distinct properties that we will study. We use a model that classifies 'positive' instances with some known ROC AUC performance (higher ROC AUC indicates a better model). We will demonstrate how each method behaves as model performance is changed. See the comparison of various bias methods for more details on this scenario.
We consider the following sampling methods:
- PPS Sample - Typical Probability Proportionate to Size sampling. It does not benefit from improvements in model performance. This is used as a comparison point for the other two methods. Ideally we should match or beat the PPS method in terms of percent of positive elements sampled and with the error bars around the prevalence estimate.
- Score Values - Sample proportionate to model score. If score[1] == 1.0 and score[2] == 0.5, we should expect record[1] to be sampled 2x more than record[2] - but - record[1] will be weighted 1/2 as much as record[2].
- Score Frequency - Attempts to take roughly uniform samples across model scores - this is typically a safe middle ground between the two above methods.
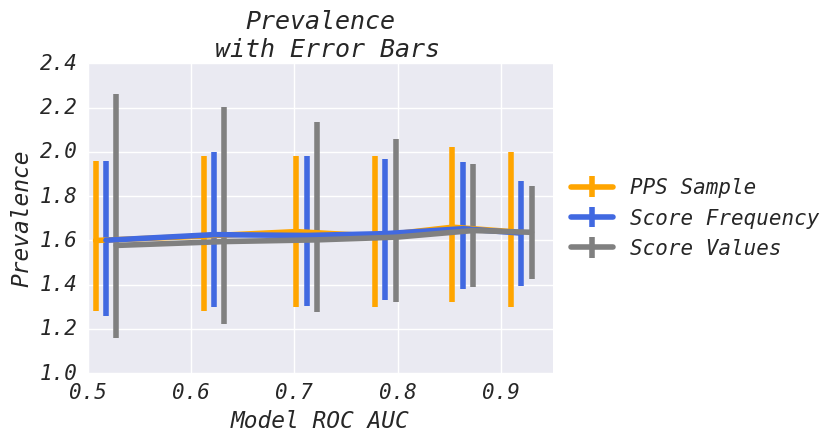 Analysis: 'Score Values' has higher variance when model performance degrades and the narrowest error bars at higher ROC AUC points. For this dataset, 'Score Frequency' produces the best trade off across model performance.
Analysis: 'Score Values' has higher variance when model performance degrades and the narrowest error bars at higher ROC AUC points. For this dataset, 'Score Frequency' produces the best trade off across model performance.
 Analysis: 'Score Values' gives the best increase in percent positive examples sampled. 'Score Frequency' beats PPS but generally samples less positive elements than 'Score Values'.
Analysis: 'Score Values' gives the best increase in percent positive examples sampled. 'Score Frequency' beats PPS but generally samples less positive elements than 'Score Values'.


import ml_sampler
import numpy as np
population_size = 1000000
# assign different weights to each record
impression_weights = np.random.exponential(scale=10, size=population_size)
# some score that we magically assign
scores = np.random.normal(scale=10, size=population_size)
scores = [max(0.001, x) for x in scores] # scores need to be positive
# in real life we would have to evaluate each sample manually or use an oracle
# in this example we are just going to make is_positve correlate with scores
is_positive = (scores * np.random.normal(scale=10, size=population_size) ) > 100
sample_index, p_sample = ml_sampler.biased_sample(
biases=scores,
weights=impression_weights,
num_samples=3000
)
# in real life we would have to evaluate each sample manually or with an oracle
sample_is_positive = is_positive[sample_index]
sample_impression_weights = impression_weights[sample_index]
est_positive_volume = ml_sampler.estimator(sample_impression_weights,
p_sample,
sample_is_positive)Comparison of various bias methods
ml_sampler requires numpy and scipy. Tested with numpy 1.11.2 and scipy 0.18.1.
# clone ml_sampler
cd ml_sampler
pip install -r requirements.txt
python setup.py installSuppose we have a classifier that can estimate the probability that a record will be 'interesting'. We can use this information to over-sample interesting things but to weight those things less for the purposes of the prevalence calculation.
In many situations - this can reduce the error (bars) associated with taking the sample while providing and unbiased estimate of the prevalence of 'interesting' things.
Please see our paper or the notebooks in the examples/ directory.
This repository is joint work by Spencer Beecher and Emanuel Strauss. Special thanks to Daniel Olmedilla.
See the CONTRIBUTING file for how to help out.
ml_sampler is BSD-licensed. We also provide an additional patent grant.