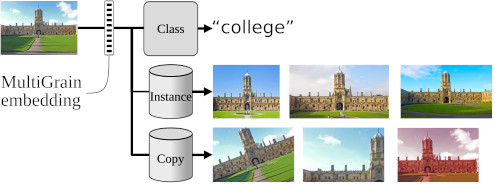
MultiGrain is a neural network architecture that solves both image classification and image retrieval tasks.
The method is described in "MultiGrain: a unified image embedding for classes and instances" (arXiv link).
BibTeX reference:
@ARTICLE{2019arXivMultiGrain,
author = {Berman, Maxim and J{\'e}gou, Herv{\'e} and Vedaldi Andrea and
Kokkinos, Iasonas and Douze, Matthijs},
title = "{{MultiGrain}: a unified image embedding for classes and instances}",
journal = {arXiv e-prints},
year = "2019",
month = "Feb",
}Please cite it if you use it.
The MultiGrain code requires
- Python 3.5 or higher
- PyTorch 1.0 or higher
and the requirements highlighted in requirements.txt
The requirements can be installed:
- Ether by setting up a dedicated conda environment:
conda env create -f environment.ymlfollowed bysource activate multigrain - Or with pip:
pip install -r requirements.txt
We provide pre-trained networks with ResNet-50 trunks for the following settings (top-1 accuracies given at scale 224):
| λ | p | augmentation | top-1 | weights |
|---|---|---|---|---|
| 1 | 1 | full | 76.8 | joint_1B_1.0.pth |
| 1 | 3 | full | 76.9 | joint_3B_1.0.pth |
| 0.5 | 1 | full | 77.0 | joint_1B_0.5.pth |
| 0.5 | 3 | full | 77.4 | joint_3B_0.5.pth |
| 0.5 | 3 | autoaugment | 78.2 | joint_3BAA_0.5.pth |
We provide fine-tuned networks for scales bigger than 224, as described in the Supplementary E. Only the pooling coefficient is fine-tuned:
| network | scale | p | top-1 | weights |
|---|---|---|---|---|
| NASNet-A-Mobile | 350 px | 1.7 | 75.1 | joint_1B_1.0.pth |
| SENet154 | 400 px | 1.6 | 83.0 | joint_3B_1.0.pth |
| PNASNet-5-Large | 500 px | 1.7 | 83.6 | joint_1B_0.5.pth |
To load a network, use the following PyTorch code:
import torch
from multigrain.lib import get_multigrain
net = get_multigrain('resnet50')
checkpoint = torch.load('base_1B_1.0.pth')
net.load_state_dict(checkpoint['model_state'])
The network takes images in any resolution.
A normalization pre-processing step is used, with mean [0.485, 0.456, 0.406].
and standard deviation [0.229, 0.224, 0.225].
The pretrained weights do not include whitening of the features (important for retrieval), which are specific to each evaluation scale; follow steps below to compute and apply a whitening.
scripts/evaluate.py evaluates the network on standard benchmarks.
Evaluate a network on ImageNet-val is straightforward using options from evaluate.py. For instance the following command:
IMAGENET_PATH= # the path that contains the /val and /train image directories
python scripts/evaluate.py --expdir experiments/joint_3B_0.5/eval_p4_500 \
--imagenet-path $IMAGENET_PATH --input-size 500 --dataset imagenet-val \
--pooling-exponent 4 --resume-from joint_3B_0.5.pth
using the joint_3B_0.5.pth pretrained weights, should reproduce the top-1/top5 results of 78.6%/94.4% given in the article in Table 2 for ResNet-50 MultiGrain p=3, λ=0.5 and p*=4 scale s*=500.
The implementation of the evaluation on the retrieval benchmarks in evaluate.py is in progress, but one may already use the dataloaders
implemented in datasets/retrieval.py for this purpose.
The training is performed in three steps. See help (-h flag) for detailed parameter list of each script.
Only the initial joint training script benefits from multi-gpu hardware, the remaining scripts are not parallelized.
scripts/train.py trains a MultiGrain architecture.
Important parameters:
--repeated-augmentations: number of repeated augmentations in the batches, N=3 was used in our joint trainings; N=1 is vanilla uniform sampling.--pooling-exponent: pooling exponent in GeM pooling, p=1: vanilla average pooling.--classif-weight: weighting factor between margin loss and classification loss (parameter λ in paper)
Other useful parameters:
--expdir: dedicated directory for the experiments--resume-from: takes either an expdir or a model checkpoint file to restore from--pretrained-backbone: initialized backbone weights from model zoo
scripts/finetune_p.py determines the optimal p* for a given input resolution by fine-tuning (see supplementary E. in paper for details). Alternatively one may use cross-validation to determine p*, as done in the main article.
scripts/whiten.py computes a PCA whitening and modifies the network accordingly,
integrating the reversed transformation in the fully-connected classification layer as described in the article.
The scripts takes a list and directory of whitening images; the list given in data/whiten.txt is relative to the multimedia commons file structure.
For example, the results with p=3 and λ=0.5 at scale s*=500 can be obtained with
# train network
python scripts/train.py --expdir experiments/joint_3B_0.5 --repeated-augmentations 3 \
--pooling-exponent 3 --classif-weight 0.5 --imagenet-path $IMAGENET_PATH
# fine-tune p*
python scripts/finetune_p.py --expdir experiments/joint_3B_0.5/finetune500 \
--resume-from experiments/joint_3B_0.5 --input-size 500 --imagenet-path $IMAGENET_PATH
# whitening
python scripts/whiten.py --expdir experiments/joint_3B_0.5/finetune500_whitened \
--resume-from experiments/joint_3B_0.5/finetune500 --input-size 500 --whiten-path $WHITEN_PATH
In appendix E. we report fine-tuning results on several pretrained networks.
This experience can be reproduced using the finetune_p.py script.
For example, in the case of SENet154 at scale s*=450, the following command should yield 83.1 top-1 accuracy with p*=1.6:
python scripts/finetune_p.py --expdir experiments/se154/finetune450 \
--pretrained-backbone --imagenet-path $IMAGENET_PATH --input-size 450 --backbone senet154 \
--no-validate-first
See the CONTRIBUTING file for how to help out.
MultiGrain is CC BY-NC 4.0 licensed, as found in the LICENSE file.
The AutoAugment implementation is based on https://github.com/DeepVoltaire/AutoAugment. The Distance Weighted Sampling and margin loss implementation is based on the authors implementation https://github.com/chaoyuaw/sampling_matters.