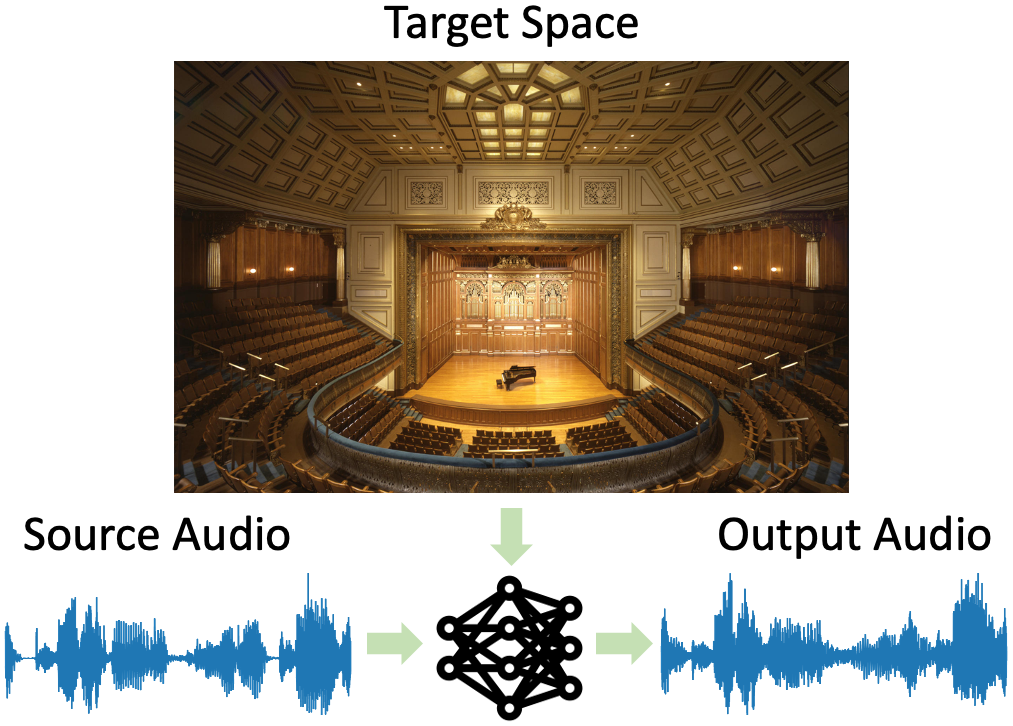
We introduce the visual acoustic matching task, in which an audio clip is transformed to sound like it was recorded in a target environment. Given an image of the target environment and a waveform for the source audio, the goal is to re-synthesize the audio to match the target room acoustics as suggested by its visible geometry and materials. To address this novel task, we propose a cross-modal transformer model that uses audio-visual attention to inject visual properties into the audio and generate realistic audio output. In addition, we devise a self-supervised training objective that can learn acoustic matching from in-the-wild Web videos, despite their lack of acoustically mismatched audio. We demonstrate that our approach successfully translates human speech to a variety of real-world environments depicted in images, outperforming both traditional acoustic matching and more heavily supervised baselines.
- Install the speechmetrics library
- Install this repo into pip by running the following command:
pip install -e .
This repo supports benchmarking multiple visual acoustic research tasks (visual acoustic matching, audio-visual dereverberation and IR synthesis from images). We provide multiple baselines for comparison.
Below we provide instructions for evaluating the pretrained AViTAR models on SoundSpaces-Speech and AVSpeech.
To train the models from scratch, simply remove the --test --eval-best flags.
- Visual acoustic matching on SoundSpaces-Speech
python vam/trainer.py --model-dir data/pretrained-models/am --version avitar --model generative_avitar --batch-size 16 --num-encoder-layers 4 --n-gpus 8 --num-node 4 --use-rgb --use-depth --gpu-mem32 --acoustic-matching --use-cnn --pretrained-cnn --dropout 0 --log10 --remove-oov --decode-wav --hop-length 128 --auto-resume --slurm --encode-wav --use-visual-pe --encoder-residual-layers 0 --decoder-residual-layers 0 --generator-lr 0.0005 --test --eval-best
- Visual acoustic matching on Acoustic AVSpeech
py vam/trainer.py --model-dir data/pretrained-models/avspeech --version avitar --model generative_avitar --batch-size 16 --num-encoder-layers 4 --n-gpus 8 --num-node 4 --use-rgb --gpu-mem32 --acoustic-matching --use-cnn --pretrained-cnn --dropout 0 --log10 --decode-wav --hop-length 128 --auto-resume --slurm --encode-wav --use-visual-pe --encoder-residual-layers 0 --decoder-residual-layers 0 --generator-lr 0.0005 --use-avspeech --num-worker 3 --dereverb-avspeech --convolve-random-rir --use-da --use-vida --use-audio-da --read-mp4 --adaptive-pool --test --eval-best
- Inference
python vam/inference.py --model-dir data/pretrained-models/avspeech --version avitar --model generative_avitar --batch-size 16 --num-encoder-layers 4 --n-gpus 8 --num-node 4 --use-rgb --gpu-mem32 --acoustic-matching --use-cnn --pretrained-cnn --dropout 0 --log10 --decode-wav --hop-length 128 --auto-resume --slurm --encode-wav --use-visual-pe --encoder-residual-layers 0 --decoder-residual-layers 0 --generator-lr 0.0005 --use-avspeech --num-worker 3 --dereverb-avspeech --use-da --use-vida --use-audio-da --read-mp4 --adaptive-pool --test --eval-best
A couple useful flags (mostly work on SoundSpaces-Speech):
--dereverbflag switches the model from acoustic matching to perform dereverberation--visualizeflag outputs qualitative examples
Download the data from the links below and unzip them under data/soundspaces_speech directory
wget http://dl.fbaipublicfiles.com/SoundSpaces/av_dereverb/metadata.zip
wget http://dl.fbaipublicfiles.com/SoundSpaces/av_dereverb/train.tar.xz
wget http://dl.fbaipublicfiles.com/SoundSpaces/av_dereverb/val-mini.tar.xz
wget http://dl.fbaipublicfiles.com/SoundSpaces/av_dereverb/test-seen.zip
wget http://dl.fbaipublicfiles.com/SoundSpaces/av_dereverb/test-unseen.tar.xz
Please download AVSpeech dataset and follow our instructions in the paper to process data (remove non-English videos, estimating RT60 for video clips and filter out non-reverberant ones). You can obtain our processed subset of AVSpeech (referred to as Acoustic AVSpeech in the paper) by running the command below:
wget http://dl.fbaipublicfiles.com/vam/acoustic_avspeech.zip
Note that even after filtering, the web videos in AVSpeech are still very noisy. In the extracted data, we also provide the ID of each file to the origin video, as used in here.
Run the command below to download pretrained weights. The dereverberator and RT60 estimator were trained on SoundSpaces-Speech.
wget http://dl.fbaipublicfiles.com/vam/pretrained-models.zip
See the CONTRIBUTING file for how to help out.
If you find the code, data, or models useful for your research, please consider citing the following two papers:
@inproceedings{chen22vam,
title = {Visual Acoustic Matching,
author = {Changan Chen and Ruohan Gao and Paul Calamia and Kristen Grauman},
booktitle = {CVPR},
year = {2022}
}
@inproceedings{chen22dereverb,
title = {Learning Audio-Visual Dereverberation,
author = {Changan Chen and Wei Sun and David Harwath and Kristen Grauman},
booktitle = {arxiv},
year = {2022}
}
This repo is CC-BY-NC licensed, as found in the LICENSE file.