
![]()

Slim is collection of surprisingly space efficient data types, with corresponding serialization APIs to persisting them on-disk or for transport.
- Why slim
- Memory overhead
- Performance
- False Positive Rate
- Status
- Roadmap
- Change-log
- Synopsis
- Getting started
- Who are using slim
- Feedback and contributions
- Authors
- License
As data on internet keeps increasing exponentially, the capacity gap between memory and disk becomes greater.
Most of the time, a data itself does not need to be loaded into expensive main memory. Only the much more important information, WHERE-A-DATA-IS, deserve a seat in main memory.
This is what slim does, keeps as little information as possible in main
memory, as a minimized index of huge amount external data.
-
SlimIndex: is a common index structure, building on top ofSlimTrie. -
SlimTrieis the underlying index data structure, evolved from trie.Features:
-
Minimized: 11 bits per key(far less than an 64-bits pointer!!).
-
Stable: memory consumption is stable in various scenarios. The Worst case converges to average consumption tightly. See benchmark.
-
Loooong keys: You can have VERY long keys(
16K bytes), without any waste of memory(and money). Do not waste your life writing another prefix compression:). (aws-s3 limits key length to 1024 bytes). Memory consumption only relates to key count, not to key length. -
Ordered: like btree, keys are stored. Range-scan will be ready in
0.6.0. -
Fast: ~150 ns per
Get(). Time complexity for a get isO(log(n) + k); n: key count; k: key length. -
Ready for transport: a single
proto.Marshal()is all it requires to serialize, transport or persisting on disk etc.
-


-
Random string, fixed length, default mode, no label is store if possible:
Bits/key: memory or disk-space in bits a key consumed in average. It does not change when key-length(
k) becomes larger!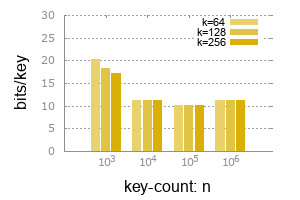
-
1 million var-length string, 10 to 20 byte in different mode SlimTrie:
- size gzip-size Original 15.0M 14.0M Complete 14.0M 10.0M InnerLabel 1.3M 0.9M NoLabel 1.3M 0.8M Raw string list and serialized slim is stored in: https://github.com/openacid/testkeys/tree/master/assets
-
Original: raw string lines in a text file.
-
Complete:
NewSlimTrie(..., Opt{Complete:Bool(true)}): lossless SlimTrie, stores complete info of every string. This mode provides accurate query. -
InnerLabel:
NewSlimTrie(..., Opt{InnerPrefix:Bool(true)})SlimTrie stores only label strings of inner nodes(but not label to a leaf). There is false positive in this mode. -
NoLabel: No label info is stored. False positive rate is higher.
-

Time(in nano second) spent on a Get() with golang-map, SlimTrie, array and btree by google.
- 3.3 times faster than the btree.
- 2.3 times faster than binary search.

Time(in nano second) spent on a Get() with different key count(n) and key length(k):


Bloom filter requires about 9 bits/key to archieve less than 1% FPR.
See: trie/report/
-
SlimTrieAPIs are stable, and has been used in a production env.Meanwhile we focus on optimizing memory usage and query performance.
-
Internal data structure are promised to be backward compatible for ever. No data migration issue!
- 2021-01-15 v0.5.11 Query by range
- 2019-09-18 v0.5.10 Reduce false positive rate to less than 0.05%
- 2019-06-03 v0.5.9 Large key set benchmark
- 2019-05-29 v0.5.6 Support up to 2 billion keys
- 2019-05-18 v0.5.4 Reduce memory usage from 40 to 14 bits/key
- 2019-04-20 v0.4.3 Range index: many keys share one index item
- 2019-04-18 v0.4.1 Marshaling support
- 2019-03-08 v0.1.0 SlimIndex SlimTrie
package index_test
import (
"fmt"
"strings"
"github.com/openacid/slim/index"
)
type Data string
func (d Data) Read(offset int64, key string) (string, bool) {
kv := strings.Split(string(d)[offset:], ",")[0:2]
if kv[0] == key {
return kv[1], true
}
return "", false
}
func Example() {
// Accelerate external data accessing (in memory or on disk) by indexing
// them with a SlimTrie:
// `data` is a sample of some unindexed data. In our example it is a comma
// separated key value series.
//
// In order to let SlimTrie be able to read data, `data` should have
// a `Read` method:
// Read(offset int64, key string) (string, bool)
data := Data("Aaron,1,Agatha,1,Al,2,Albert,3,Alexander,5,Alison,8")
// keyOffsets is a prebuilt index that stores key and its offset in data accordingly.
keyOffsets := []index.OffsetIndexItem{
{Key: "Aaron", Offset: 0},
{Key: "Agatha", Offset: 8},
{Key: "Al", Offset: 17},
{Key: "Albert", Offset: 22},
{Key: "Alexander", Offset: 31},
{Key: "Alison", Offset: 43},
}
// `SlimIndex` is simply a container of SlimTrie and its data.
st, err := index.NewSlimIndex(keyOffsets, data)
if err != nil {
fmt.Println(err)
}
// Lookup
v, found := st.Get("Alison")
fmt.Printf("key: %q\n found: %t\n value: %q\n", "Alison", found, v)
v, found = st.Get("foo")
fmt.Printf("key: %q\n found: %t\n value: %q\n", "foo", found, v)
// Output:
// key: "Alison"
// found: true
// value: "8"
// key: "foo"
// found: false
// value: ""
}Create an index item for every 4(or more as you wish) keys.
Let several adjacent keys share one index item reduces a lot memory cost if there are huge amount keys in external data. Such as to index billions of 4KB objects on a 4TB disk(because one disk IO costs 20ms for either reading 4KB or reading 1MB).
package index_test
import (
"fmt"
"strings"
"github.com/openacid/slim/index"
)
type RangeData string
func (d RangeData) Read(offset int64, key string) (string, bool) {
for i := 0; i < 4; i++ {
if int(offset) >= len(d) {
break
}
kv := strings.Split(string(d)[offset:], ",")[0:2]
if kv[0] == key {
return kv[1], true
}
offset += int64(len(kv[0]) + len(kv[1]) + 2)
}
return "", false
}
func Example_indexRanges() {
// Index ranges instead of keys:
// In this example at most 4 keys shares one index item.
data := RangeData("Aaron,1,Agatha,1,Al,2,Albert,3,Alexander,5,Alison,8")
// keyOffsets is a prebuilt index that stores range start, range end and its offset.
keyOffsets := []index.OffsetIndexItem{
// Aaron +--> 0
// Agatha |
// Al |
// Albert |
// Alexander +--> 31
// Alison |
{Key: "Aaron", Offset: 0},
{Key: "Agatha", Offset: 0},
{Key: "Al", Offset: 0},
{Key: "Albert", Offset: 0},
{Key: "Alexander", Offset: 31},
{Key: "Alison", Offset: 31},
}
st, err := index.NewSlimIndex(keyOffsets, data)
if err != nil {
panic(err)
}
v, found := st.RangeGet("Aaron")
fmt.Printf("key: %q\n found: %t\n value: %q\n", "Aaron", found, v)
v, found = st.RangeGet("Al")
fmt.Printf("key: %q\n found: %t\n value: %q\n", "Al", found, v)
v, found = st.RangeGet("foo")
fmt.Printf("key: %q\n found: %t\n value: %q\n", "foo", found, v)
// Output:
// key: "Aaron"
// found: true
// value: "1"
// key: "Al"
// found: true
// value: "2"
// key: "foo"
// found: false
// value: ""
}package trie
import (
"fmt"
"github.com/openacid/slim/encode"
)
func ExampleSlimTrie_ScanFrom() {
var keys = []string{
"",
"`",
"a",
"ab",
"abc",
"abca",
"abcd",
"abcd1",
"abce",
"be",
"c",
"cde0",
"d",
}
values := makeI32s(len(keys))
codec := encode.I32{}
st, _ := NewSlimTrie(codec, keys, values, Opt{
Complete: Bool(true),
})
// untilD stops when encountering "d".
untilD := func(k, v []byte) bool {
if string(k) == "d" {
return false
}
_, i32 := codec.Decode(v)
fmt.Println(string(k), i32)
return true
}
fmt.Println("scan (ab, +∞):")
st.ScanFrom("ab", false, true, untilD)
fmt.Println()
fmt.Println("scan [be, +∞):")
st.ScanFrom("be", true, true, untilD)
fmt.Println()
fmt.Println("scan (ab, be):")
st.ScanFromTo(
"ab", false,
"be", false,
true, untilD)
// Output:
//
// scan (ab, +∞):
// abc 4
// abca 5
// abcd 6
// abcd1 7
// abce 8
// be 9
// c 10
// cde0 11
//
// scan [be, +∞):
// be 9
// c 10
// cde0 11
//
// scan (ab, be):
// abc 4
// abca 5
// abcd 6
// abcd1 7
// abce 8
}Install
go get github.com/openacid/slim/trieFeedback and Contributions are greatly appreciated.
At this stage, the maintainers are most interested in feedback centered on:
- Do you have a real life scenario that
slimsupports well, or doesn't support at all? - Do any of the APIs fulfill your needs well?
Let us know by filing an issue, describing what you did or wanted to do, what you expected to happen, and what actually happened:
Or other type of issue.





See also the list of contributors who participated in this project.
This project is licensed under the MIT License - see the LICENSE file for details.