This repository contains the code for TACL2021 paper: SummaC: Re-Visiting NLI-based Models for Inconsistency Detection in Summarization
We release: (1) the trained SummaC models, (2) the SummaC Benchmark and data loaders, (3) training and evaluation scripts.
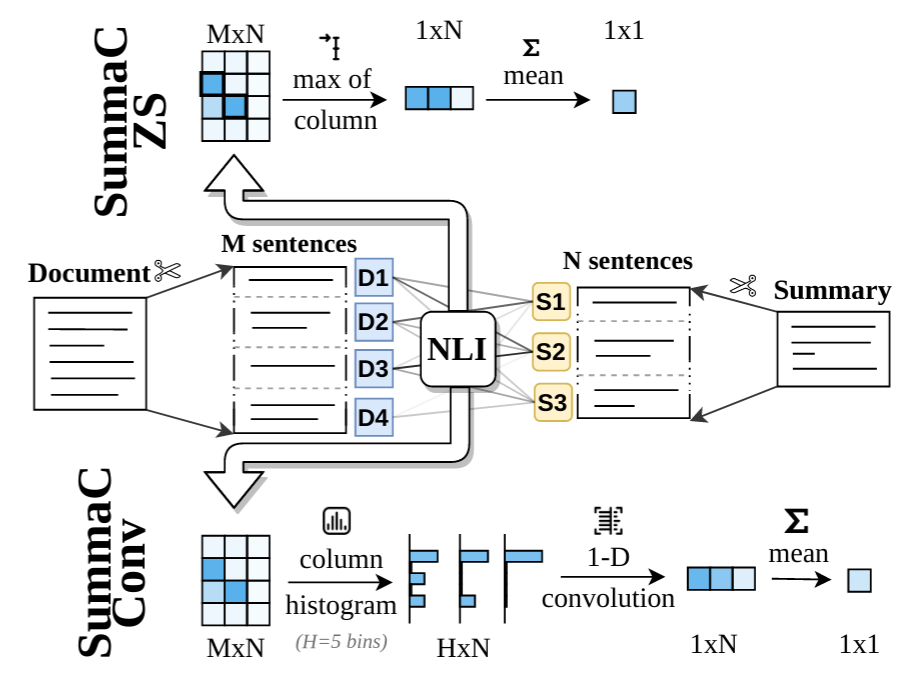
The two trained models SummaC-ZS and SummaC-Conv are implemented in model_summac.py (link):
- SummaC-ZS does not require a model file (as the model is zero-shot and not trained): it can be used as seen at the bottom of the
model_summac.py. - SummaC-Conv requires a
start_filewhich contains the trained weight for the convolution layer. The defaultstart_fileused to compute results is available in this repository (summac_conv_vitc_sent_perc_e.bindownload link).
from model_summac import SummaCZS
model = SummaCZS(granularity="sentence", model_name="vitc")
document = """Scientists are studying Mars to learn about the Red Planet and find landing sites for future missions.
One possible site, known as Arcadia Planitia, is covered instrange sinuous features.
The shapes could be signs that the area is actually made of glaciers, which are large masses of slow-moving ice.
Arcadia Planitia is in Mars' northern lowlands."""
summary1 = "There are strange shape patterns on Arcadia Planitia. The shapes could indicate the area might be made of glaciers. This makes Arcadia Planitia ideal for future missions."
summary2 = "There are strange shape patterns on Arcadia Planitia. The shapes could indicate the area might be made of glaciers."
score1 = model.score([document], [summary1])
print("Summary Score 1 consistency: %.3f" % (score1["scores"][0])) # Prints: 0.587
score2 = model.score([document], [summary2])
print("Summary Score 2 consistency: %.3f" % (score2["scores"][0])) # Prints: 0.877
To load all the necessary files: (1) clone this repository, (2) add the reposity to Python path: export PYTHONPATH="${PYTHONPATH}:/path/to/summac/"
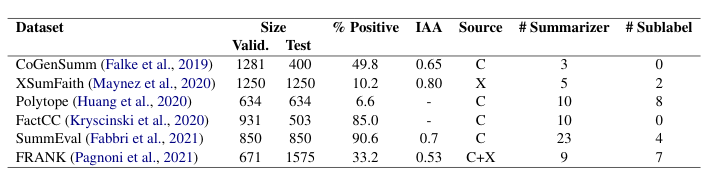
The SummaC Benchmark consists of 6 summary consistency datasets that have been standardized to a binary classification task. The datasets included are:
% Positive is the percentage of positive (consistent) summaries. IAA is the inter-annotator agreement (Fleiss Kappa). Source is the dataset used for the source documents (CNN/DM or XSum). # Summarizers is the number of summarizers (extractive and abstractive) included in the dataset. # Sublabel is the number of labels in the typology used to label summary errors.
The data-loaders for the benchmark are included in utils_summac_benchmark.py (link). Because the dataset relies on previously published work, the dataset requires the manual download of several datasets. For each of the 6 tasks, the link and instruction to download are present as a comment in the file. Once all the files have been compiled, the benchmark can be loaded and standardized by running:
from utils_summac_benchmark import SummaCBenchmark
benchmark_validation = SummaCBenchmark(benchmark_folder="/path/to/summac_benchmark/", cut="val")
Note: we have a plan to streamline the process by further improving to automatically download necessary files if not present, if you would like to participate please let us know. If encoutering an issue in the manual download process, please contact us.
If you make use of the code, models, or algorithm, please cite our paper. Bibtex to come.
If you'd like to contribute, or have questions or suggestions, you can contact us at phillab@berkeley.edu. All contributions welcome, for example helping make the benchmark more easily downloadable, or improving model performance on the benchmark.