This project was made as part of the Udacity Data Engineering Nanodegree.
Its goal is to apply concepts of relational data modeling with Postgres and build an ETL pipeline using Python.
To complete it, it was necessary to define fact and dimension tables for a star schema for a particular analytic focus, and write an ETL pipeline that transfers data from files in two local directories into these tables in Postgres using Python and SQL.
A startup called Sparkify wants to analyze the data they've been collecting on songs and user activity on their new music streaming app. The analytics team is particularly interested in understanding what songs users are listening to. Currently, they don't have an easy way to query their data, which resides in a directory of JSON logs on user activity on the app, as well as a directory with JSON metadata on the songs in their app.
They'd like a data engineer to create a Postgres database with tables designed to optimize queries on song play analysis. The data engineer role is to create a database schema and ETL pipeline for this analysis.
Two datasets were used for this, one for songs and one for log data. Both can be found inside the data folder.
The first dataset is a subset of real data from the Million Song Dataset. Each file is in JSON format and contains metadata about a song and the artist of that song. The files are partitioned by the first three letters of each song's track ID. For example, here are filepaths to two files in this dataset.
song_data/A/B/C/TRABCEI128F424C983.json
song_data/A/A/B/TRAABJL12903CDCF1A.json
And below is an example of what a single song file, TRAABJL12903CDCF1A.json, looks like.
{"num_songs": 1, "artist_id": "ARJIE2Y1187B994AB7", "artist_latitude": null, "artist_longitude": null, "artist_location": "", "artist_name": "Line Renaud", "song_id": "SOUPIRU12A6D4FA1E1", "title": "Der Kleine Dompfaff", "duration": 152.92036, "year": 0}
The second dataset consists of log files in JSON format generated by this event simulator based on the songs in the dataset above. These simulate activity logs from a music streaming app based on specified configurations.
The log files in the dataset are partitioned by year and month. For example, here are filepaths to two files in this dataset.
log_data/2018/11/2018-11-12-events.json
log_data/2018/11/2018-11-13-events.json
The database schema is contained within the file create_tables.py, and the the queries used during the ETL process are in sql_queries.py. The ER diagram below illustrates the database schema.
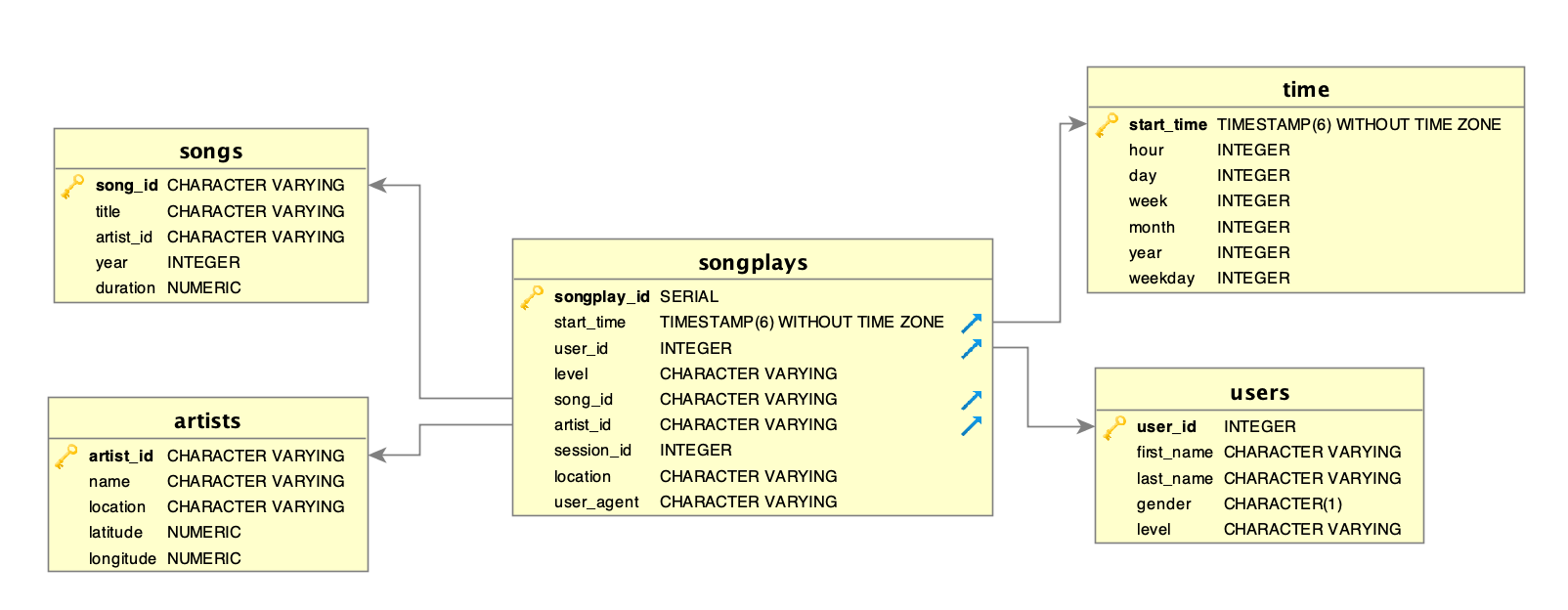
The ETL process is contained within etl.py. It extracts data from the song dataset to fill both songs and artists tables and extracts data from the log dataset and load it into the users and time tables. Finally, it combines data from both datasets to load the songplays table.
To be able to run the ETL pipeline, Python 3 and PostgreSQL 9.5.14 are required.
For more information about how to install Python, please visit https://www.python.org/about/gettingstarted/
If you need help installing PostgreSQL, please go to https://www.postgresql.org/download/\
Pandas and psycopg2 are also used. They can be installed using pip.
To populate the database, from the root directory execute
python create_tables.py
This will create the songs, artists, time, users and songplays tables defined in sql_queries.py.
This file also define some queries and insertions templates.
Once the database is created, the ETL pipeline can be run. To do so, execute from the root directory
python etl.py
This will navigate through all .json files inside the data folder, extract their data and load the database tables.
This project is licensed under the MIT License. For more information about it, please visit https://opensource.org/licenses/MIT