StreamX
let't flink|spark easy
The flink & spark development scaffolding, encapsulates a series of out-of-the-box source and sink, and standardizes flink & spark development,testing,deployment and monitoring
StreamX consists of two parts, streamx-core and streamx-console, Streamx-core (Streamx-flink-core|Streamx-spark-core) is a framework for development. Drawing on the idea of springBoot, the convention is better than the configuration. It provides developers with a list of sources and sinks out of the box,Every API is carefully polished,and expands related methods (only scala is effective), which greatly simplifies The development of flink greatly improves development efficiency and development experience
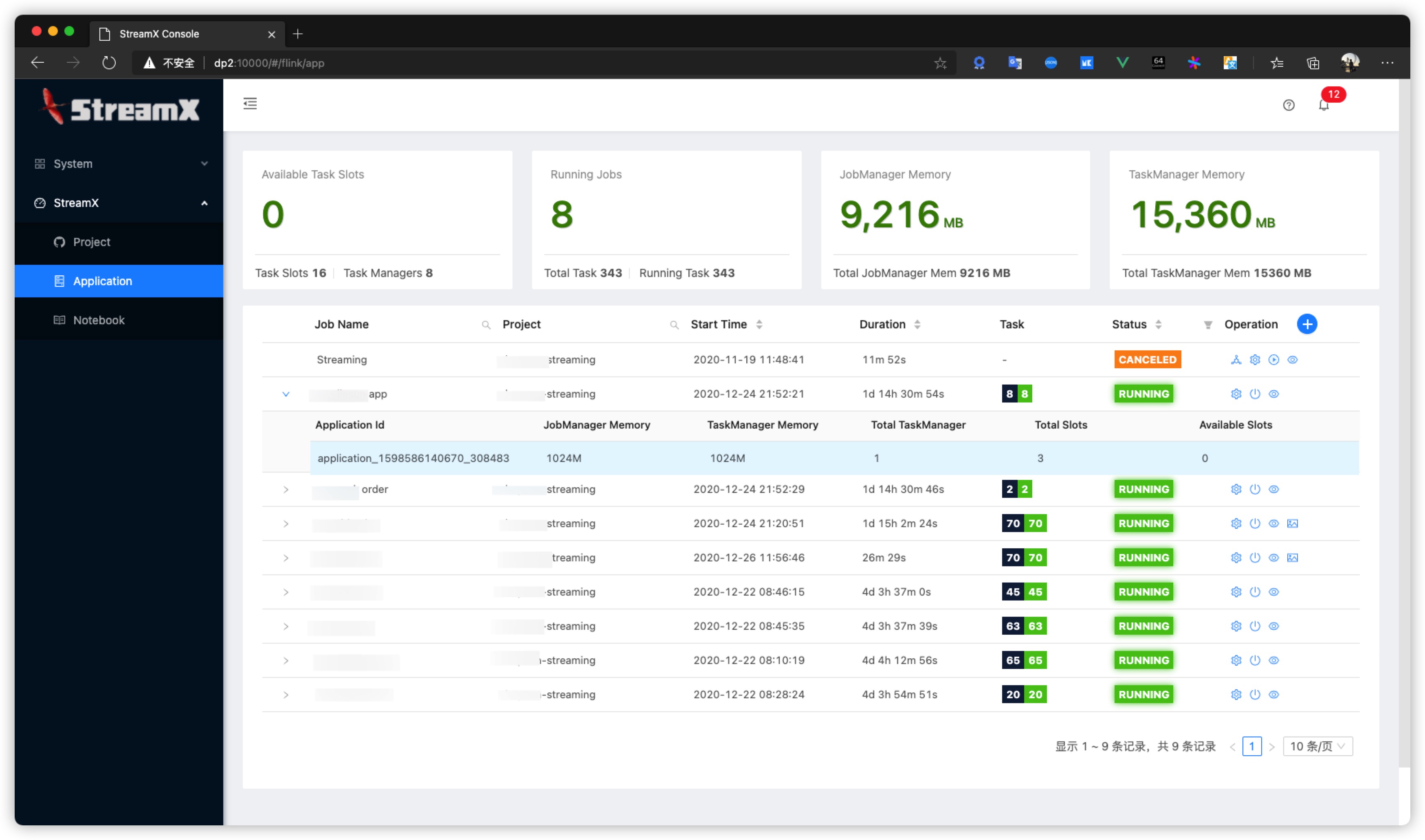
Streamx-console is an independent platform that complements streamx-core. It better manages flink tasks, integrates project compilation, release, startup, savepoint, monitoring, operation and maintenance, etc., which greatly simplifies the operation and maintenance of flink tasks. A development base of the flink platform, it is easy to do secondary development based on it
How to Build
- Make sure JDK 8+ and maven is installed on your machine.
- Run:
mvn clean install -DskipTests
git clone https://github.com/streamxhub/streamx.git
cd streamx
mvn clean install -DskipTestsAfter the build is completed, the project will be installed in the local maven warehouse and added to the pom.xml file of your own project when using it
<dependency>
<groupId>com.streamxhub.streamx</groupId>
<artifactId>streamx-flink-core</artifactId>
<version>1.0.0</version>
</dependency>Quick Start
1. Flink Example with StreamX
- Make sure flink 1.12.0 +
package com.your.flink.streamx
import com.streamxhub.streamx.flink.core.scala.sink.KafkaSink
import com.streamxhub.streamx.flink.core.scala.source.KafkaSource
import com.streamxhub.streamx.flink.core.scala.{FlinkStreaming, StreamingContext}
import org.apache.flink.api.scala._
object HelloStreamXApp extends FlinkStreaming {
override def handle(context: StreamingContext): Unit = {
//1) source
val source = KafkaSource(context).getDataStream[String](topic = "hello")
.uid("kfk_source")
.name("kfk_source")
.map(_.value)
//2) println
source.print()
//3) sink
KafkaSink(context).sink(source,topic = "kfk_sink")
}
}
2. Define application.yml
Define a series of startup information and source and sink information in the configuration file application.yml. The specific format is as follows:
flink:
deployment: #注意这里的参数一定能要flink启动支持的参数(因为在启动参数解析时使用了严格模式,一个不识别会停止解析),详情和查看flink官网,否则会造成整个参数解析失败,最明显的问题的找不到jar文件
option:
target: yarn-per-job # --target <arg> (local|remote|yarn-per-job|yarn-session|run-application)
detached: # -d (If present, runs the job in detached mode)
shutdownOnAttachedExit: # -sae (If the job is submitted in attached mode, perform a best-effort cluster shutdown when the CLI is terminated abruptly, e.g., in response to a user interrupt, such as typing Ctrl + C.)
zookeeperNamespace: # -z Namespace to create the Zookeeper sub-paths for high availability mode
jobmanager: # -m Address of the JobManager to which to connect. Use this flag to connect to a different JobManager than the one specified in the configuration. Attention: This option is respected only if the high-availability configuration is NONE
property: # see: https://ci.apache.org/projects/flink/flink-docs-release-1.12/deployment/config.html
$internal.application.main: com.your.flink.streamx.HelloStreamXApp # main class
yarn.application.name: FlinkHelloWorldApp
yarn.application.node-label: StreamX
taskmanager.numberOfTaskSlots: 1
parallelism.default: 2
jobmanager.memory:
flink.size:
heap.size:
jvm-metaspace.size:
jvm-overhead.max:
off-heap.size:
process.size:
taskmanager.memory:
flink.size:
framework.heap.size:
framework.off-heap.size:
managed.size:
process.size:
task.heap.size:
task.off-heap.size:
jvm-metaspace.size:
jvm-overhead.max:
jvm-overhead.min:
managed.fraction: 0.4
watermark:
time.characteristic: EventTime
interval: 10000
checkpoints:
unaligned: true
enable: true
interval: 5000
mode: EXACTLY_ONCE
table:
planner: blink # (blink|old|any)
mode: streaming #(batch|streaming)
# restart-strategy
restart-strategy: failure-rate #(fixed-delay|failure-rate|none共3个可配置的策略)
# Up to 10 mission failures are allowed within 5 minutes, and restart every 5 seconds after each failure. If the failure rate exceeds this failure rate, the program will exit
restart-strategy.failure-rate:
max-failures-per-interval: 10
failure-rate-interval: 5min
delay: 5000
#failure-rate:
# max-failures-per-interval:
# failure-rate-interval:
# delay:
#none:
#state.backend
state.backend: rocksdb #保存类型(jobmanager,filesystem,rocksdb)
state.backend.memory: 5242880 #针对jobmanager有效,最大内存
state.backend.async: false # 针对(jobmanager,filesystem)有效,是否开启异步
state.backend.incremental: true #针对rocksdb有效,是否开启增量
#rocksdb config: https://ci.apache.org/projects/flink/flink-docs-release-1.9/ops/config.html#rocksdb-configurable-options
#state.backend.rocksdb.block.blocksize:
#....
# source config....
kafka.source:
bootstrap.servers: kafka1:9092,kafka2:9092,kafka3:9092
topic: topic1,topic2,topic3
group.id: hello
auto.offset.reset: earliest
#enable.auto.commit: true
#start.from:
#timestamp: 1591286400000 #指定timestamp,针对所有的topic生效
#offset: # 给每个topic的partition指定offset
#topic: topic1,topic2,topic3
#topic1: 0:182,1:183,2:182 #分区0从182开始消费,分区1从183...
#topic2: 0:182,1:183,2:182
#topic3: 0:192,1:196,2:196
kafka.sink:
bootstrap.servers: kafka1:9092,kafka2:9092,kafka3:9092
topic: kfk_sink
transaction.timeout.ms: 1000
semantic: AT_LEAST_ONCE # EXACTLY_ONCE|AT_LEAST_ONCE|NONE
batch.size: 1
3. Run Application
Start main and with argument " --flink.conf $path/application.yml"