


数组(Array)是一种线性表数据结构。它用一组连续的内存空间,来存储一组具有相同类型的数据。

寻址公式:
a[i]_address = base_address + i * data_type_size特性:
- 下标随机访问
$O(1)$ - 插入删除
$O(n)$
链表(Linked List)用指针将离散的内存空间串联起来




与数组比较:



查找、插入、索引动态更新:

特性:
- 插入、删除、查找时间复杂度
$O(\log{n})$ - 空间复杂度
$O(n)$



空队列阻塞出队,满队列阻塞入队


| 排序 | 最好 | 最坏 | 平均 | 空间 | 稳定 |
|---|---|---|---|---|---|
| 冒泡 | ✅ | ||||
| 插入 | ✅ | ||||
| 选择 | ❌ | ||||
| 归并 | ✅ | ||||
| 快排 | ❌ | ||||
| 桶 | - | ✅ | |||
| 计数 | ✅ | ||||
| 基数 | - | ✅ |






优化:
- 三数取中
- 随机





时间复杂度:$O(\log{n})$
特点:
- 数据有序
- 数据太小太大都不适合

- 非负
- 尽可能为单射
- 尽可能简单
例如:MD5, SHA, CRC
由于很难在简单函数、大定义域下做到散列函数为单射,所以我们要考虑散列冲突问题,一般有以下解决方案:

特点:
- 探测方式:线性探测、二次探测、双重散列
- 数据全部存在数组里,方便序列化
- �删除数据不能直接删除,那样会导致查找失效,只能先将数据标为deleted
- 插入越多时,散列冲突可能性越大,空闲位置会越少,探测的时间就会越久。

链表也可替换为跳表、红黑树等
装载因子大于阈值时申请更大的空间,重新计算哈希值,插入之前的对象。但是可能会导致某次插入操作耗时过长,为了避免,可以在申请空间后每次插入的时候多搬运一个旧对象
.svg.png)
not tree:




height, depth, level:


Methods for storing binary trees:
-
Nodes and references
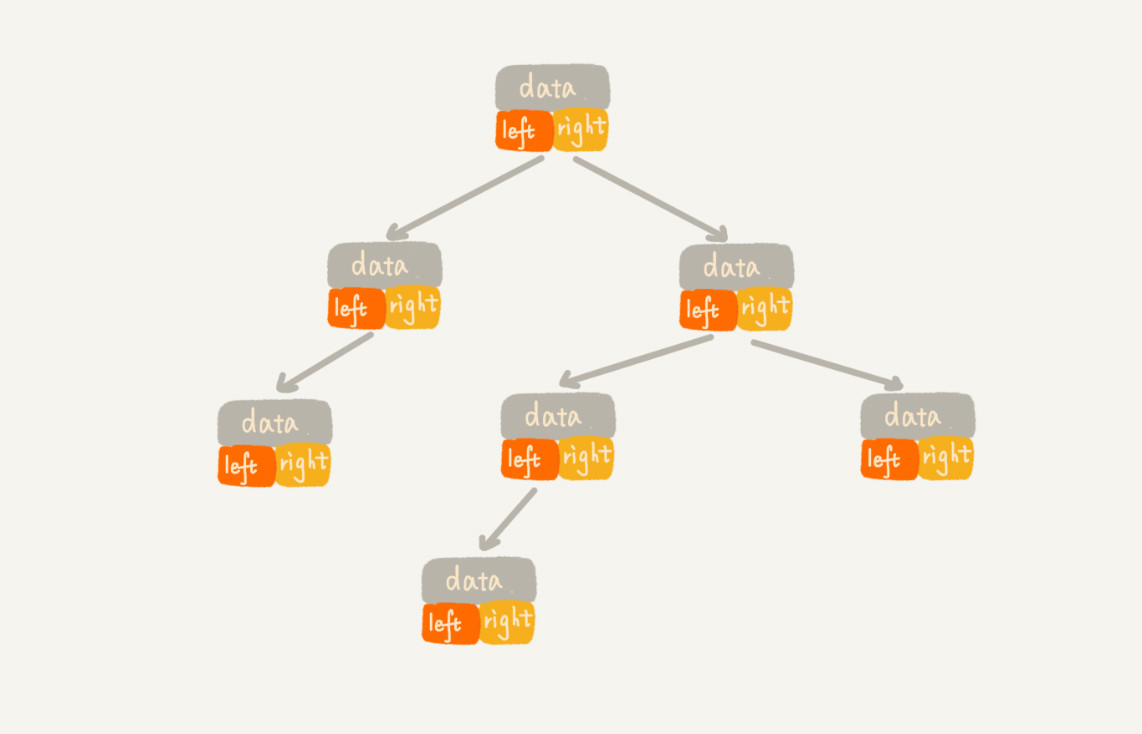
-
Arrays
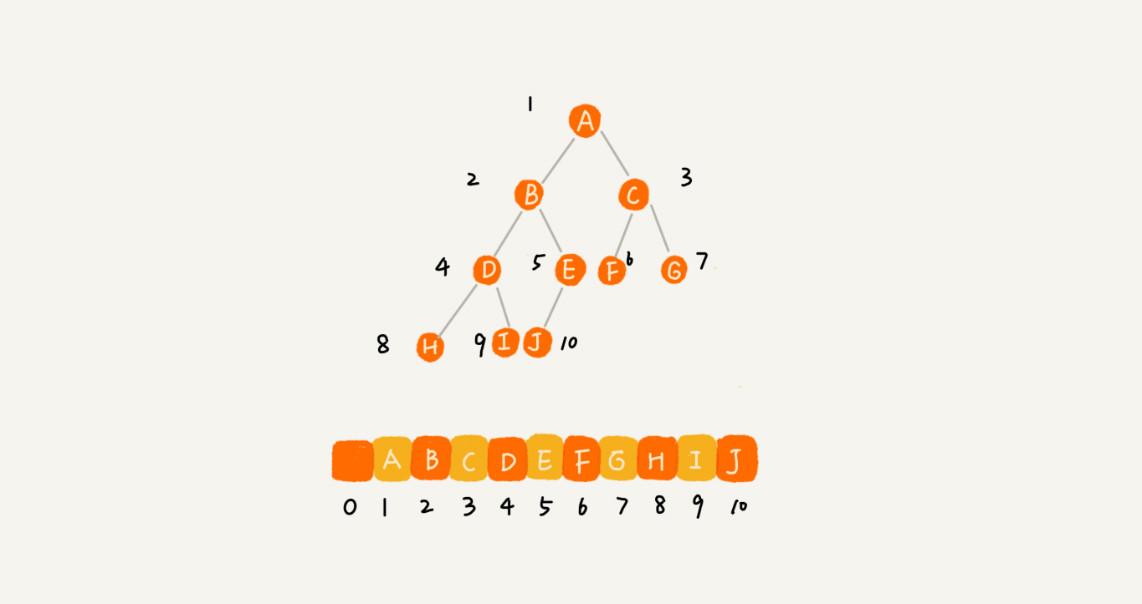
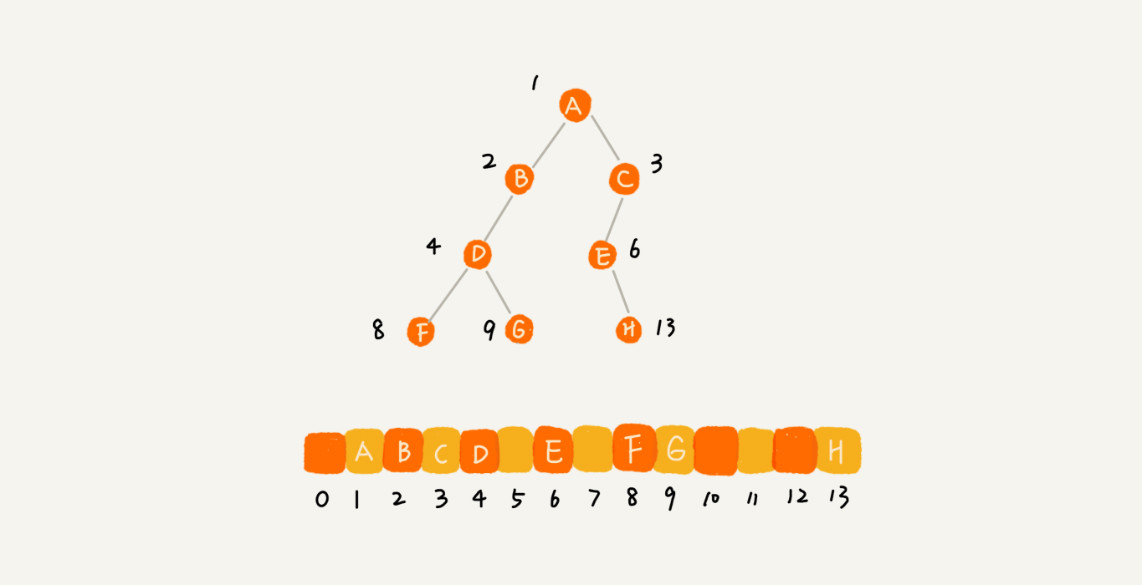




Traversal:

Depth-first traversal of an example tree:
- pre-order (red): F, B, A, D, C, E, G, I, H;
- in-order (yellow): A, B, C, D, E, F, G, H, I;
- post-order (green): A, C, E, D, B, H, I, G, F.

