In this notebook we will create and train the classifier on the chest x-ray dataset to classify whether an image shows signs of pneumonia or not.
At first we download the data from kaggle (https://www.kaggle.com/c/rsna-pneumonia-detection-challenge/data)
Dataset: Wang X, Peng Y, Lu L, Lu Z, Bagheri M, Summers RM. ChestX-ray8: Hospital-scale Chest X-ray Database and Benchmarks on Weakly-Supervised Classification and Localization of Common Thorax Diseases. IEEE CVPR 2017, http://openaccess.thecvf.com/content_cvpr_2017/papers/Wang_ChestX-ray8_Hospital-Scale_Chest_CVPR_2017_paper.pdf
Some example images from dataset :

In order to efficiently handle our data in the Dataloader, we convert the X-Ray images stored in the DICOM format to numpy arrays. Afterwards we compute the overall mean and standard deviation of the pixels of the whole dataset, for the purpose of normalization. Then the created numpy images are stored in two separate folders according to their binary label:
- 0: All X-Rays which do not show signs of pneumonia
- 1: All X-Rays which show signs of pneumonia
We standardize all images by the maximum pixel value in the provided dataset, 255. All images are resized to 224x224.
To compute dataset mean and standard deviation, we compute the sum of the pixel values as well as the sum of the squared pixel values for each subject. This allows to compute the overall mean and standard deviation without keeping the whole dataset in memory.
We use a transformation sequence for Data Augmentation and Normalization:
- RandomResizedCrops which applies a random crop of the image and resizes it to the original image size (224x224)
- Random Rotations between -5 and 5 degrees
- Random Translation (max 5%)
- Random Scaling (0.9-1.1 of original image size)
Inspect some augmented train images:

There are 24000 train images and 2684 val images. So, The classes are imbalanced: There are more images without signs of pneumonia than with pneumonia. There are multiple ways to deal with imbalanced datasets:
- Weighted Loss
- Oversampling
- Doing nothing :)
In this example, we will simply do nothing as this often yields the best results.
Now it is time to create the model - We will use the ResNet18 network architecture.
As most of the torchvision models, the original ResNet expects a three channel input in conv1.
However, our X-Ray image data has only one channel.
Thus we need to change the in_channel parameter from 3 to 1.
Additionally, we will change the last fully connected layer to have only one output as we have a binary class label.
We use the Adam Optimizer with a learning rate of 0.0001 and the BinaryCrossEntropy Loss function.
(In fact we use BCEWithLogitsLoss which directly accepts the raw unprocessed predicted values and computes the sigmoid activation function before applying Cross Entropy).
Trainer documentation: https://pytorch-lightning.readthedocs.io/en/latest/common/trainer.html
Compute metrics:
We can see that the overall result is already decent with our simple model.
However, we suffer from a large amount of False Negatives due to the data imbalance.
This is of particular importance in to avoid in medical imaging as missing findings might be fatal.
Val Accuracy: 0.8457525968551636
Val Precision: 0.7002096176147461
Val Recall: 0.5520660877227783
Confusion Matrix:
tensor([[1936, 143],
[ 271, 334]])
Confusion Matrix 2:
tensor([[1725, 354],
[ 136, 469]])
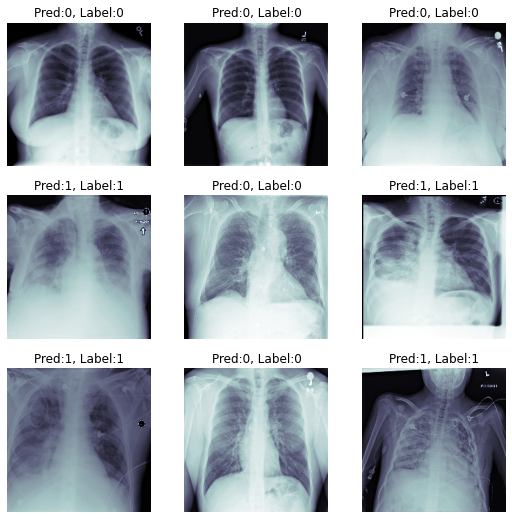
Final results of classification: