


Demo | Multi-Modal Arena | Otter-9B Checkpoints | MIMIC-IT Dataset(coming soon) | Youtube Video | Bilibili Video | Paper
-
[2023-05-14]
- Otter battles with Owl? the Pokémon Arena is here! Our model is selected into Multi-Modal Arena. This is an interesting Multi-Modal Foundation Models competition arena that let you see different models reaction to the same question.
-
[2023-05-08]
- Check our Arxiv release paper at Otter: A Multi-Modal Model with In-Context Instruction Tuning !
- We support
xformersfor memory efficient attention.

Large Language Models (LLMs) have exhibited exceptional universal aptitude as few/zero-shot learners for numerous tasks, thanks to their pre-training on large-scale text data. GPT-3 is a prominent LLM that has showcased significant capabilities in this regard. Furthermore, variants of GPT-3, namely InstrctGPT and ChatGPT, equipped with instruction tuning, have proven effective in interpreting natural language instructions to perform complex real-world tasks. In this paper, we propose to introduce instruction tuning into multi-modal models, motivated by the Flamingo model's upstream interleaved format pretraining dataset. We adopt a similar approach to construct our MI-Modal In-Context Instruction Tuning (MIMIC-IT) dataset. We then introduce 🦦 Otter, a multi-modal model based on OpenFlamingo (open-sourced version of DeepMind's Flamingo), trained on MIMIC-IT and showcasing improved instruction-following ability and in-context learning. We also optimize OpenFlamingo's implementation for researchers, democratizing the required training resources from 1x A100 GPU to 4x RTX-3090 GPUs, and integrate both OpenFlamingo and Otter into Hugging Face Transformers for more researchers to incorporate the models into their customized training and inference pipelines.



You may install via conda env create -f environment.yml. Especially to make sure the transformers>=4.28.0, accelerate>=0.18.0.
You can use the 🦩 Flamingo model / 🦦 Otter model as a 🤗 Hugging Face model with only a few lines! One-click and then model configs/weights are downloaded automatically.
from flamingo import FlamingoModel
flamingo_model = FlamingoModel.from_pretrained("luodian/openflamingo-9b-hf", device_map=auto)
from otter import OtterModel
otter_model = OtterModel.from_pretrained("luodian/otter-9b-hf", device_map=auto)Previous OpenFlamingo was developed with DistributedDataParallel (DDP) on A100 cluster. Loading OpenFlamingo-9B to GPU requires at least 33G GPU memory, which is only available on A100 GPUs.
In order to allow more researchers without access to A100 machines to try training OpenFlamingo, we wrap the OpenFlamingo model into a 🤗 hugging Face model (Jinghao has submitted a PR to the /huggingface/transformers!). Via device_map=auto, the large model is sharded across multiple GPUs when loading and training. This can help researchers who do not have access to A100-80G GPUs to achieve similar throughput in training, testing on 4x RTX-3090-24G GPUs, and model deployment on 2x RTX-3090-24G GPUs. Specific details are below (may vary depending on the CPU and disk performance, as we conducted training on different machines).
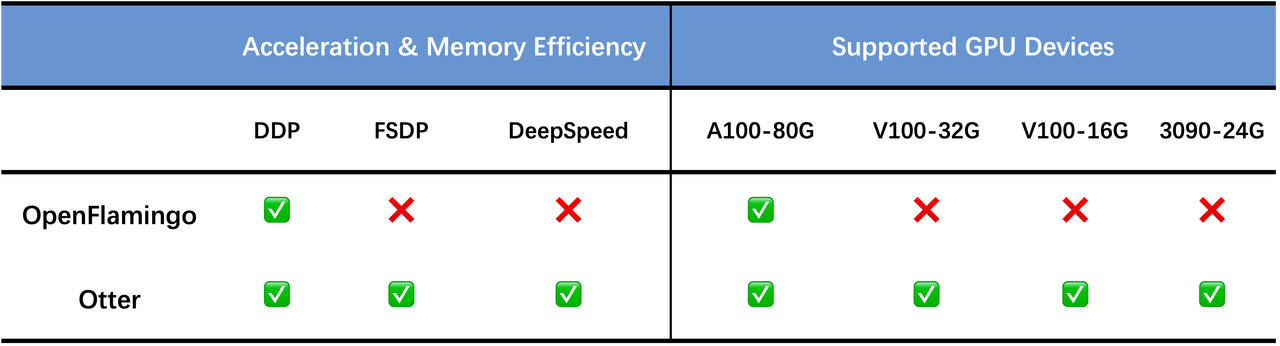
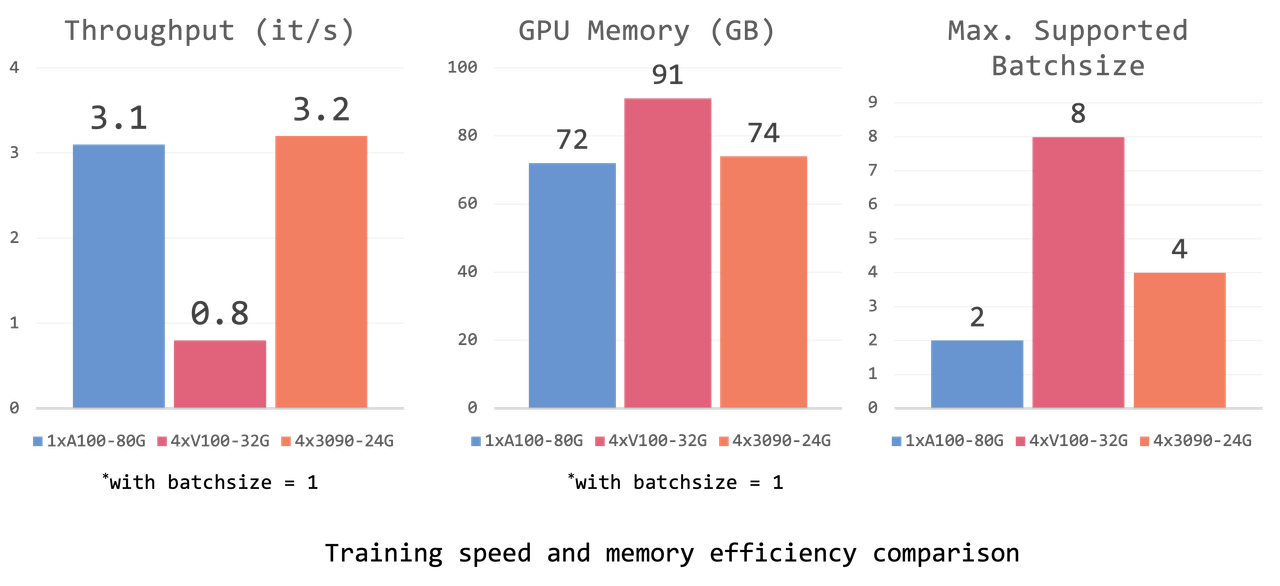
Our Otter model is also developed in this way and it's deployed on the 🤗 Hugging Face model hub. Our model can be hosted on two RTX-3090-24G GPUs and achieve a similar speed to one A100-80G machine.
The OpenFlamingo framework leverages the interleaved multi-modal MMC4 dataset to emerge in its few-shot, in-context learning capabilities. The MMC4 dataset is composed of image-text pairs derived from individual HTML files, with significant contextual relationships between different pairs, as depicted in below Figure (a). An MMC4 training data sample contains (i) a queried image-text pair, where the text typically describes the image, and (ii) context, which includes the remaining image-text pairs from the same HTML file. The primary training objective of OpenFlamingo is to generate text for the queried image-text pair, and the paradigm of generating query text conditioned on in-context examples ensures OpenFlamingo's in-context learning capacity during the inference phase.
Our Multi-Modal In-Context Instruction Tuning (MIMIC-IT) dataset aims to augment OpenFlamingo's instruction comprehension capabilities while preserving its in-context learning capacity. To unleash OpenFlamingo's instruction-following potential, we compile data from visual-language tasks into image-instruction-answer triplets. Concurrently, to maintain OpenFlamingo's in-context learning capacity, we retrieve in-context examples for each triplet, which often lack correlated context, such as a visual question-answer data sample in VQAv2. Specifically, each MIMIC-IT data sample consists of (i) a queried image-instruction-answer triplet, with the instruction-answer tailored to the image, and (ii) context. The context contains a series of image-instruction-answer triplets that contextually correlate with the queried triplet, emulating the relationship between the context and the queried image-text pair found in the MMC4 dataset. The training objective for MIMIC-IT is to generate the answer within the queried image-instruction-answer triplet. The image-instruction-answer triplets are derived from (i) visual question-answer datasets, namely, VQAv2 and GQA, (ii) visual instruction datasets, such as LLaVA, (iii) an in-progress, high-quality panoptic video scene graph dataset from the PVSG repository. For each video, we select 4-8 frames for instruction-following annotation, using the LLaVA dataset as a reference. We have developed three heuristics to construct the context for each image-instruction-answer triplet, as illustrated in Figure (b).

We unify different instructing data into a single dataset class. The full dataset is coming soon!
Train on MIMIC-IT datasets, using the following commands:
First, run, and answer the questions asked. This will generate a config file and save it to the cache folder. The config will be used automatically to properly set the default options when doing accelerate launch.
accelerate configThen run the training script.
accelerate launch pipeline/train/instruction_following.py \
--pretrained_model_name_or_path=luodian/openflamingo-9b-hf \
--dataset_resampled \
--multi_instruct_path=./in_context_instruct.tsv \
--run_name=otter-9b \
--batch_size=1 \
--num_epochs=6 \
--report_to_wandb \
--cross_attn_every_n_layers=4 \
--lr_scheduler=cosine \
--delete_previous_checkpoint \
--learning_rate=1e-5 \For details, you may refer to the model card.
We host our Otter-9B Demo via dual RTX-3090-24G GPUs. Launch your own demo by following the demo instructions.
We are working towards offering these features to our users. However, we have encountered some issues in the process. If you have the solutions to these issues, we would be grateful if you could submit a pull request with your code. Your contribution would be highly appreciated.
-
xformerssupport: for saving GPU memory and training speedup. issue #35 -
load_in_8bitsupport: for saving GPU memory and training speedup. [issue]
We are working on the following models with much stronger performance.
- Otter-9B for Videos
- Otter-15B
If you found this repository useful, please consider citing:
@software{li_bo_2023_7879884,
author = {Li, Bo and Zhang, Yuanhan and Chen, Liangyu and Wang, Jinghao and Yang, Jingkang and Liu, Ziwei},
title = {{Otter: Multi-Modal In-Context Learning Model with Instruction Tuning}},
month = apr,
year = 2023,
publisher = {Zenodo},
version = {0.1},
doi = {10.5281/zenodo.7879884},
url = {https://doi.org/10.5281/zenodo.7879884}
}
We thank Chunyuan Li and Jack Hessel for their advise and support, as well as the OpenFlamingo team for their great contribution to the open source community.