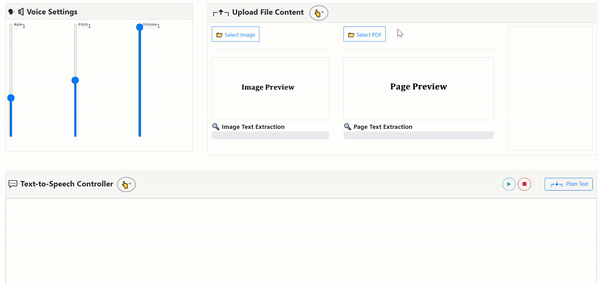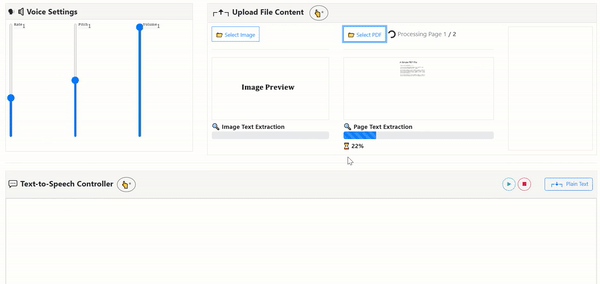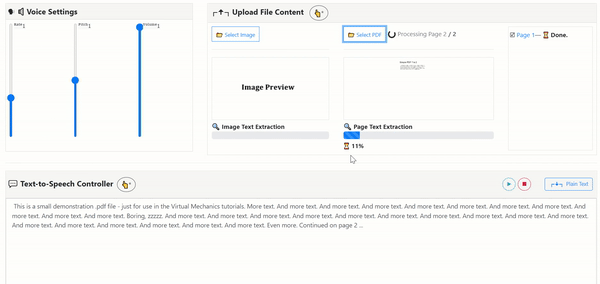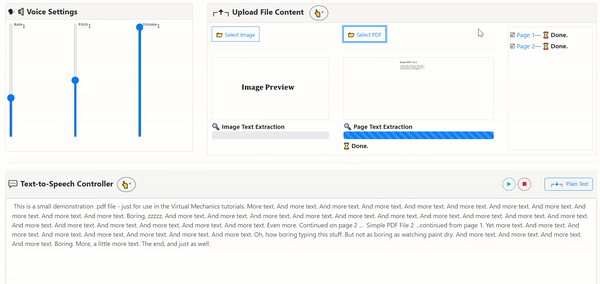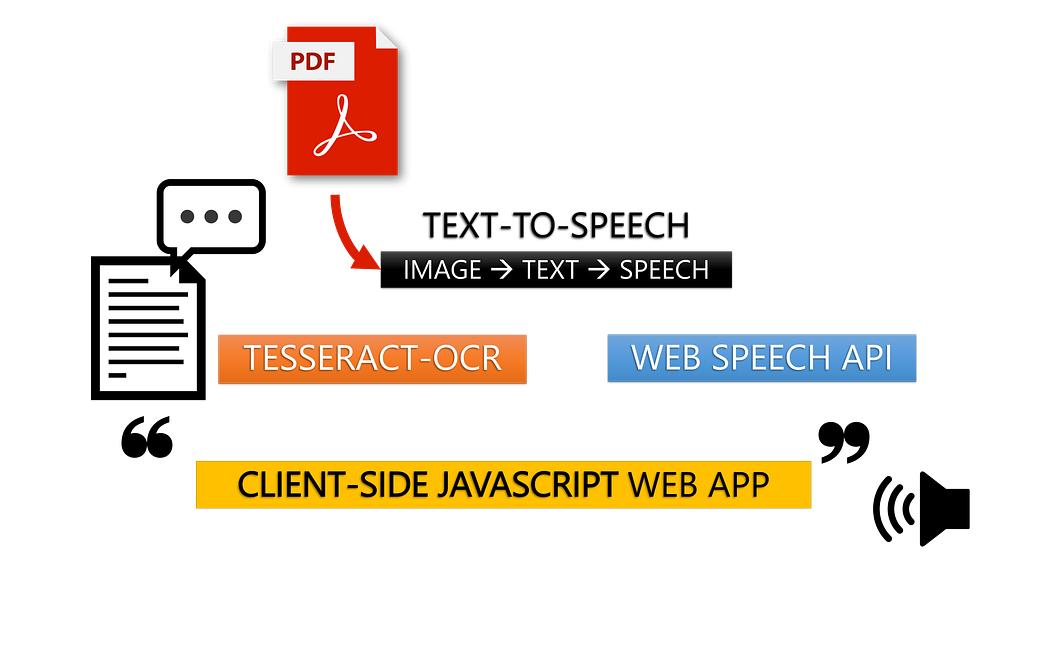
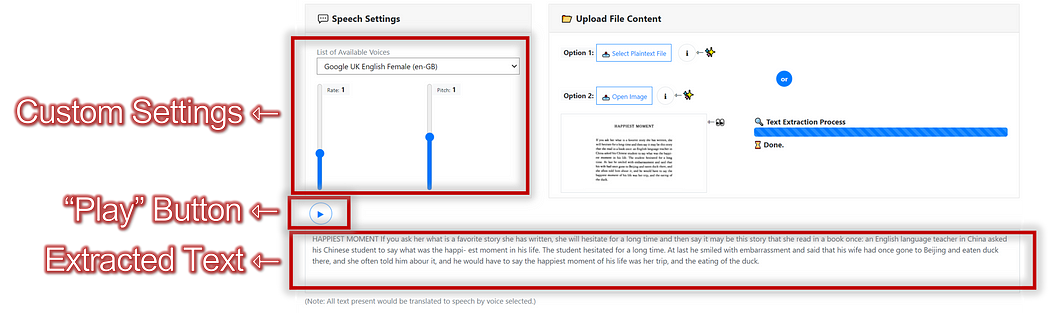
Uses the open-sourced OCR Engine: Tesseract.js v2
- Image-to-Text: Input image file for Text Extraction with Tesseract-OCR
- PDF-to-Image-to-Text: Input PDF File to render each page image for Text Extraction with PDF.js
- Text-to-Speech: Voice generation with Web API SpeechSynthesis
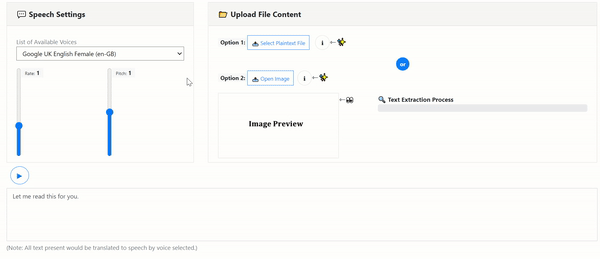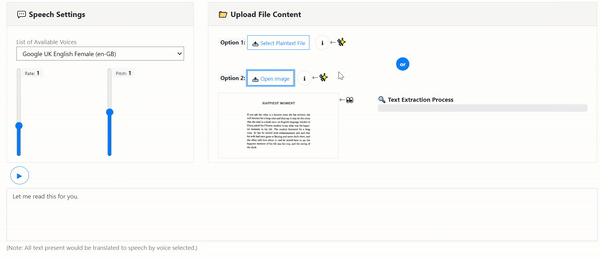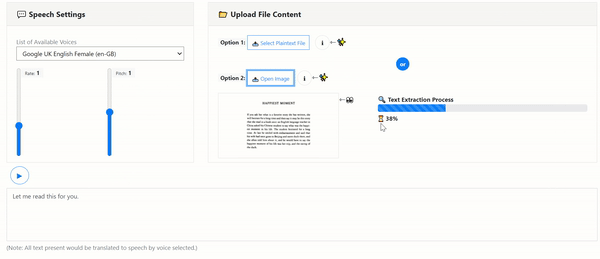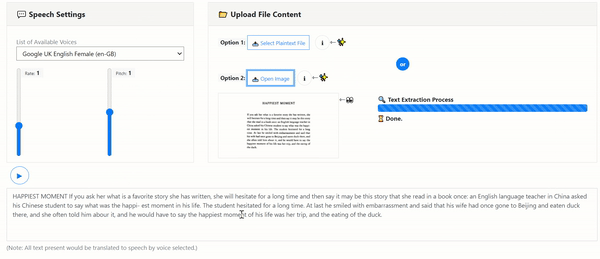
- Article (2): Build An Image & PDF Text Extraction Tool with Tesseract OCR Using Client-side JavaScript