This service provides the proxy to Wikidata KG (Lookup API + Sparql Endpoint) to generate a domain-specific Semantic Table Annotation (STA) benchmarks. The following are the artifact of this generator code.
- tFood
& tFoodL
- Both datasets have been generated by this generator code for Food domain with a configuration of 2, and 10 levels, respectively.
- tFood is made public for the first time during SemTab 2023 - Round 1
- tBiodiv
& tBiodivL
- Both datasets are generated for the Biodiversity domain with 2, and 10 levels of the internal tree, respectively.
- tBiomed
& tBiomedL
- Both datasets are generated for the Biomedical domain using a configuration of 2, and 5 levels, respectively.
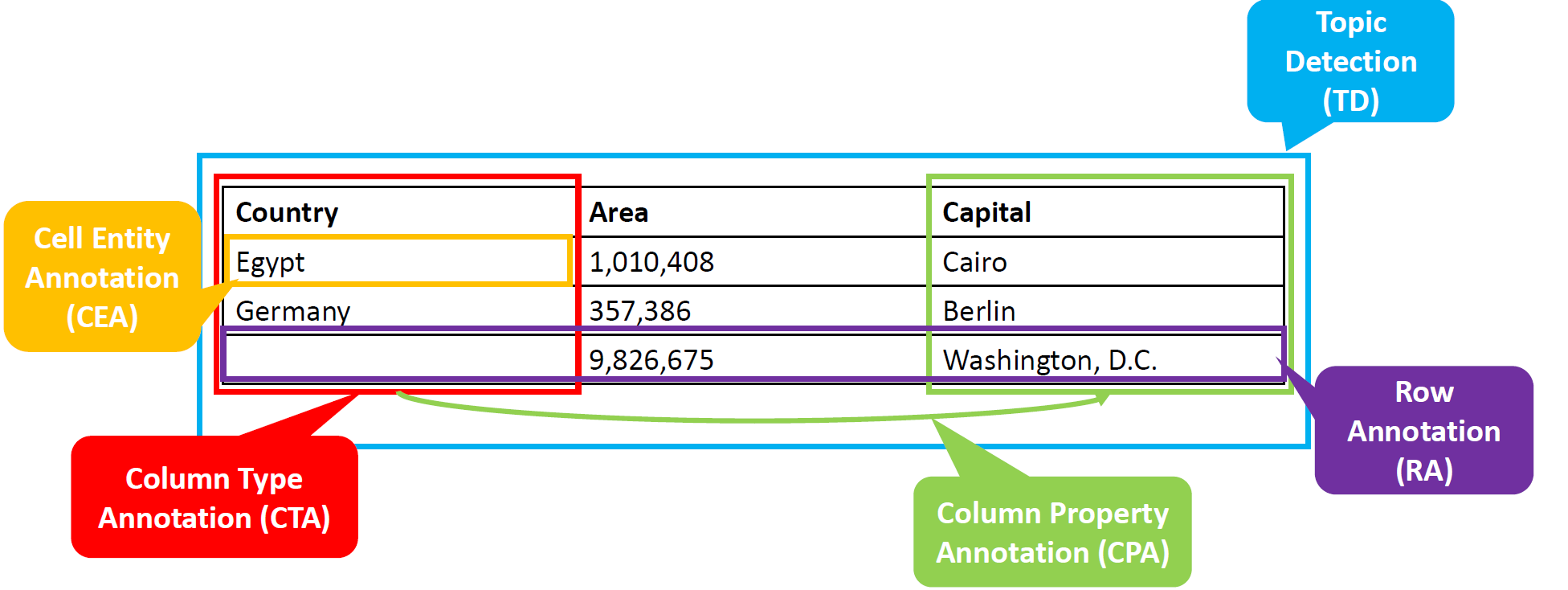
- STI or STA is the task of annotating tabular data semantically using Knowledge Graphs (KGs)
- The following image represent the summary of the 5 state-of-the-art tasks for STI
- CEA - Cell Entity Annotation: Assigns table cells to entities from KGs
- CTA - Colum Type Annotation: Maps table columns to semantic types or classes from KGs
- CPA - Colum-column Property Annotation: Links table columns (subject-object) with properties or predicates from KGs
- RA - Row Annotation: Links rows from table to an entities from KGs
- Could be seen as a special version of CEA but the major difference is the absence of the subject cell (usually the first cell of the row)
- TD - Topic Detection: Annotates the entire tables with entities or classes from KGs

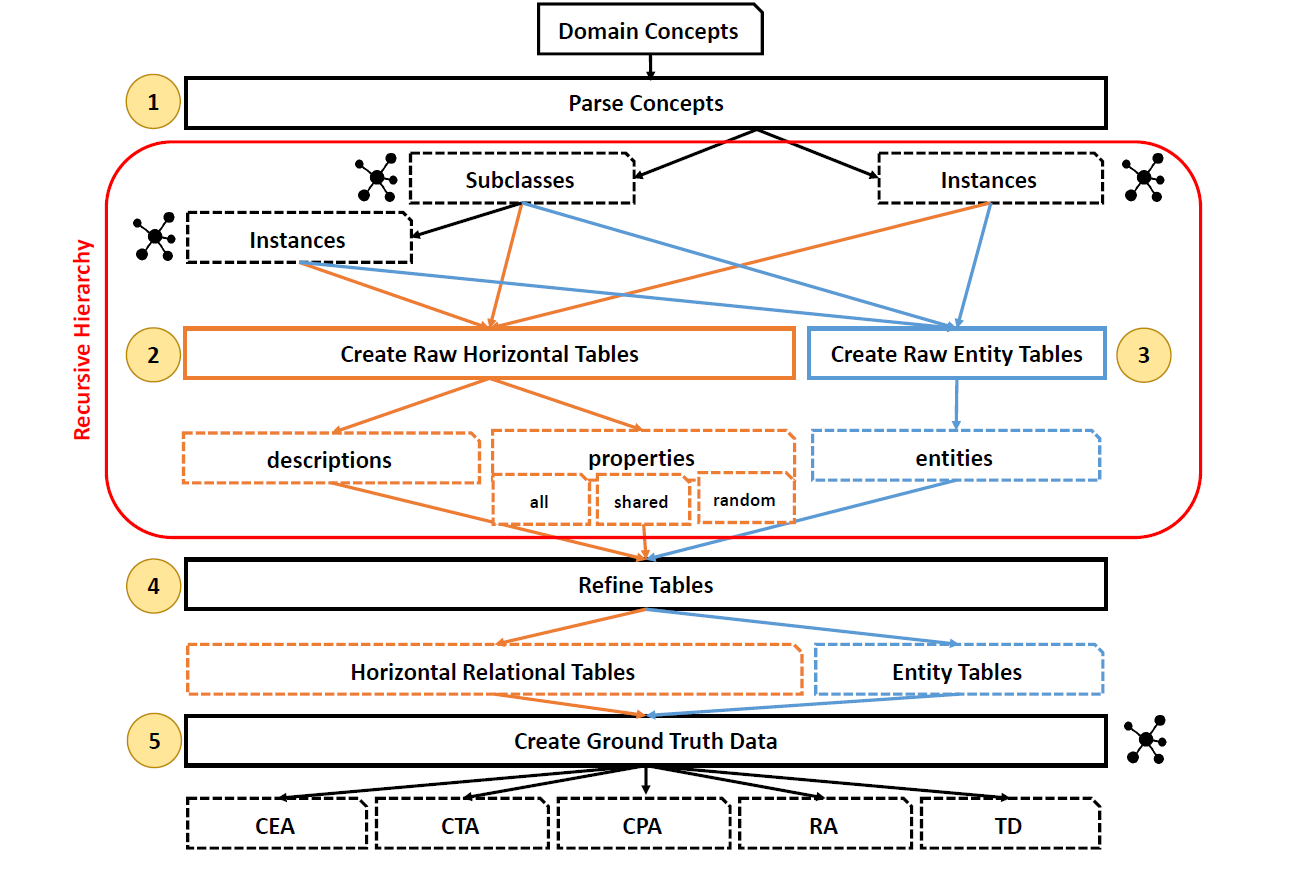
- The following image represents the generation method adopted in the Generator Code in this repo.
- To generate a large scale dataset that is derived from the
Fooddomain, we followed the next steps:- We determined the relevant
Keywords, e.g., sandwich, meal, breakfast, pizza, ...etc. that are commonly used in normal menus - We looked up these keywords in Wikidata and created
data\input\categories.csv, this step yieldDomain Concepts(entities + classes) - We parse the given categories via their instances and subclasses their next level in the hierarchy (recursive manner)
- We constructed Horizontal and Entity tables for the retrieved instances and subclasses
- The creation method is done based (descriptions (long text in Wikidata), properties, or the entities themselves) or the combination among all of them
- The following step included tables refinement, it cleans the tables entries that are impossible to annotate
- e.g., remove a row that is annotated as sandwich given only a country name (Italy might contain 1000 sandwich, so, it is impossible for a system, even a human, determine that the correct class of Italy is Sandwich)
- This step also contains the table header and names anonymization using random characters and numbers
- The last step is the creation of the ground truth format that splits the actual tables to be annotated from the STI answers
- We determined the relevant

- Python virtual environments (venvs) are recommended to run this project - python 3.11 - make sure you are pointing to the main dir of the project
pip install -r requirements.txt- Make sure that the desired categories are under
data\input\categories.csvsee examples here - Tune your configuration file (benchmark name, maximum depth (default =10)
hypercorn main:app -c python:asgi_config.py- In your web browser or Postman, you can hit
generate_benchmark_at_onceGET API that generates your benchmarks
| Name | Type | Description |
|---|---|---|
generate_benchmark_at_once |
GET | On hot button for creating a domain-specific benchmark based on the given input/categories.csv |
generate_tables |
GET | Generates both Entity and Horizontal tables for the corresponding categories.csv |
anonymize_tables |
GET | Rename tables' names using follow a certain sequence e.g., Q50 --> UUT10 |
count |
GET | Provides tables' count for each entity and horizontal tables |
val_test_split |
GET | generates val and test folds of the current benchmarks for evaluating and testing STI systems |
{
"message": "Success or error message of creating benchmark",
"counts": {
"Entity Tables": "Number of created entity tables",
"Horizontal Tables": "Number of created horizontal tables",
"Total": "Number of created entity + horizontal tables"
}
}{
"message": "Success or error message of creating benchmark"
}{
"message": "Success or error message of creating benchmark"
}{
"Entity Tables": "Number of created entity tables",
"Horizontal Tables": "Number of created horizontal tables",
"Total": "Number of created entity + horizontal tables"
}{
"message": "success, validation and test splits are created."
}Environment variables for configuration (can also be set via docker-compose.yml):
| Name | Default | Description |
|---|---|---|
| BENCHMARK_NAME | None | Name of the benchmark we would like to create. |
| CATEGORIES_FILE_NAME | None | Input domain related concepts from the target KG. |
| MAX_DEPTH | 10 | Maximum level of recursive function to build the hierarchy of the domain concepts. |
| MAX_NO_INSTANCES | 100 | Tree pruning threshold that set the maximum number of instances/subclasses to be retrieve per domain concept. |
| MAX_PARALLEL_REQUESTS | 5 | maximum number of parallel requests. Used to prevent IP-bans from Wikidata. |
| DEFAULT_DELAY | 10 | default delay upon HTTP error (429, 500, ...); in seconds. |
| MAX_RETRIES | 5 | maximum number of retries upon HTTP errors. |
| wikidata_SPARQL_ENDPOINT | 'https://query.wikidata.org/sparql' | Wikidata endpoint that hits to construct the benchmark. |
@dataset{tfood_zenodo_oct23,
author = {Nora Abdelmageed and
Ernesto Jimènez-Ruiz and
Oktie Hassanzadeh and
Birgitta König-Ries},
title = {{tFood: Semantic Table Annotations Benchmark for
Food Domain}},
year = 2023,
doi = {10.5281/zenodo.10048187},
url = {https://doi.org/10.5281/zenodo.10048187}
}