Este proyecto es un web crawler diseñado para recopilar información de páginas web. Puedes utilizar una o varias URLs como punto de partida para iniciar la búsqueda. Además, puedes definir una lista de palabras clave para buscar en el contenido de la página. Si se encuentran coincidencias de palabras clave en la página, se guarda su contenido en un archivo JSON. El proyecto también te permite establecer un límite de profundidad de búsqueda y un tiempo de espera máximo para cada descarga.
Este proyecto requiere Python 3.5 o superior.
- Descarga o clona el repositorio.
$ git clone https://github.com/Xukay101/topic-web-crawler.git
- Instala los requisitos del proyecto con el siguiente comando:
$ pip install -r requirements.txt
El archivo de configuración config.py contiene los siguientes parámetros:
DEPTH_LIMIT: profundidad máxima a la que el web crawler debe explorar los enlaces del sitio web. El valor por defecto es2, lo que significa que solo se descargará el contenido del sitio web original.WAIT_TIME: tiempo de espera en segundos entre cada solicitud. El valor por defecto es0.KEYWORDS: lista de palabras clave a buscar en el contenido del sitio web. Si esta lista está vacía, el web crawler no buscará palabras clave. El valor por defecto es una lista vacía.MIN_KEYWORD_OCCURRENCES: número mínimo de veces que una palabra clave debe aparecer en el contenido de un sitio web para que se guarde en el archivo JSON. El valor por defecto es1.MAX_DOWNLOAD_TIME: tiempo máximo en segundos permitido para descargar el contenido de un sitio web. Si el tiempo de descarga supera este límite, el web crawler lo considerará como un fallo de descarga. El valor por defecto es5.
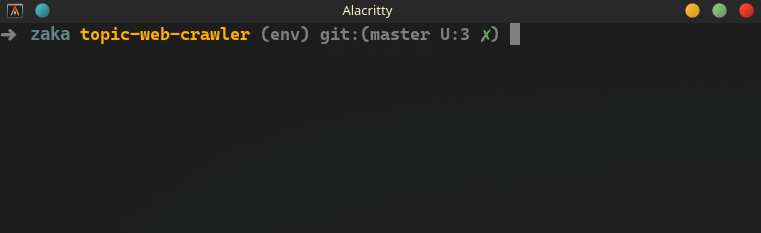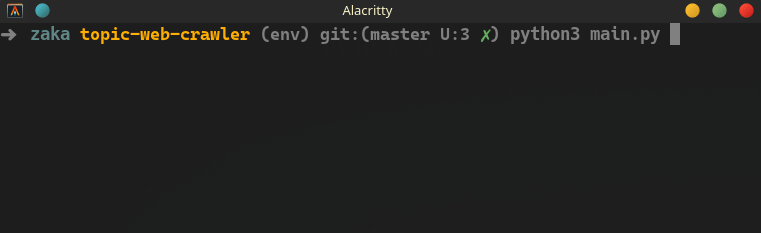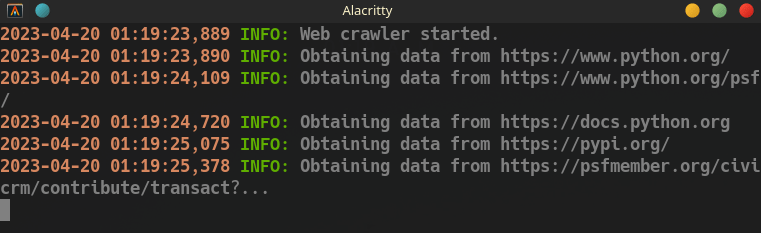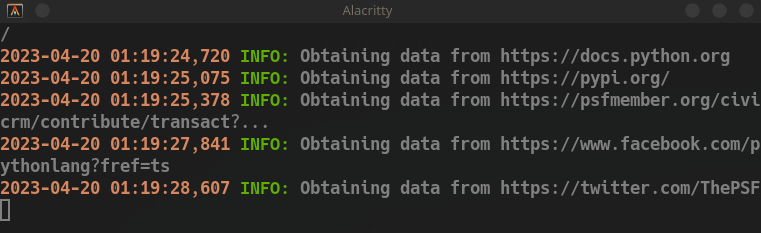
Para ejecutar el web crawler, simplemente ejecute el archivo main.py seguido de uno o varios URLs. Por ejemplo:
$ python main.py url1 [url2 url3 ...]
La información recopilada se guardará en dos archivos: data.json y urls.txt, ubicados en la carpeta data. El archivo data.json contendrá la información sobre los sitios web encontrados, mientras que urls.txt contendrá una lista de los URLs visitadas.
Si desea utilizar palabras clave para buscar información en el contenido del sitio web, simplemente agregue una o varias palabras clave a la lista KEYWORDS en el archivo de configuración config.py. El web crawler buscará estas palabras clave en el contenido de cada sitio web descargado y guardará la información en el archivo data.json si se cumplen las condiciones especificadas.
- Jose Zacarías Flores - Xukay101