App stores crawler
Crawler for apple and google stores to get ranking of the best apps by category.
Features
- Concurrent: it uses python 3.5+ async.io lib to get results faster
- Distributed: you can run the crawler from as many machines you want using a centralized db
- Priority to download: as the stores have an infinity of apps, the most ranked apps are updated frequently. We don't need to download all the apps before start the updates.
- Configurable random range of time to wait between requests to not flood app stores
- Fault tolerant: what happens if the internet stop working for a minute? It handles the error and put the URL to be indexed again
How does it work?
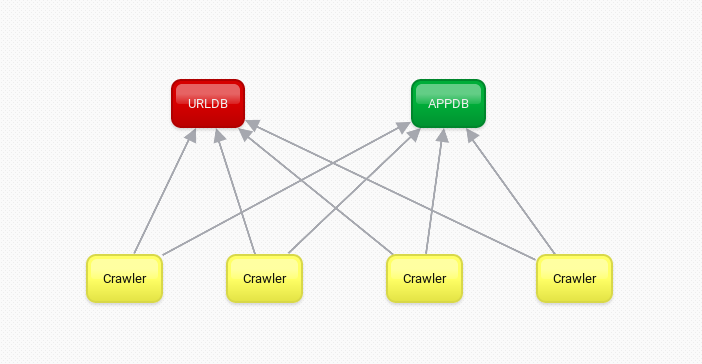
Microservices
There are 2 microservices:
- urldb: handles the queue of which urls must be downloaded, and saves new ones to the queue
- appsdb: handles the apps creation and queries
Crawler
Crawls the categories of the app stores, and than ask for urldb which URLs are next in queue to be crawled. It also send new apps URLs to the urldb to be handled
How to run it?
First of all, create a virtualenv for python 3.6
virtualenv --python=python3.6 env
source env/bin/activate
pip install -r requirements.txt
Run appdb.py
source env/bin/activate
python appdb.py
Run urldb.py
source env/bin/activate
python urldb.py
Run as many crawlers.py as you want, but be carefull to not flood app stores and be blocked.
source env/bin/activate
python crawler.py
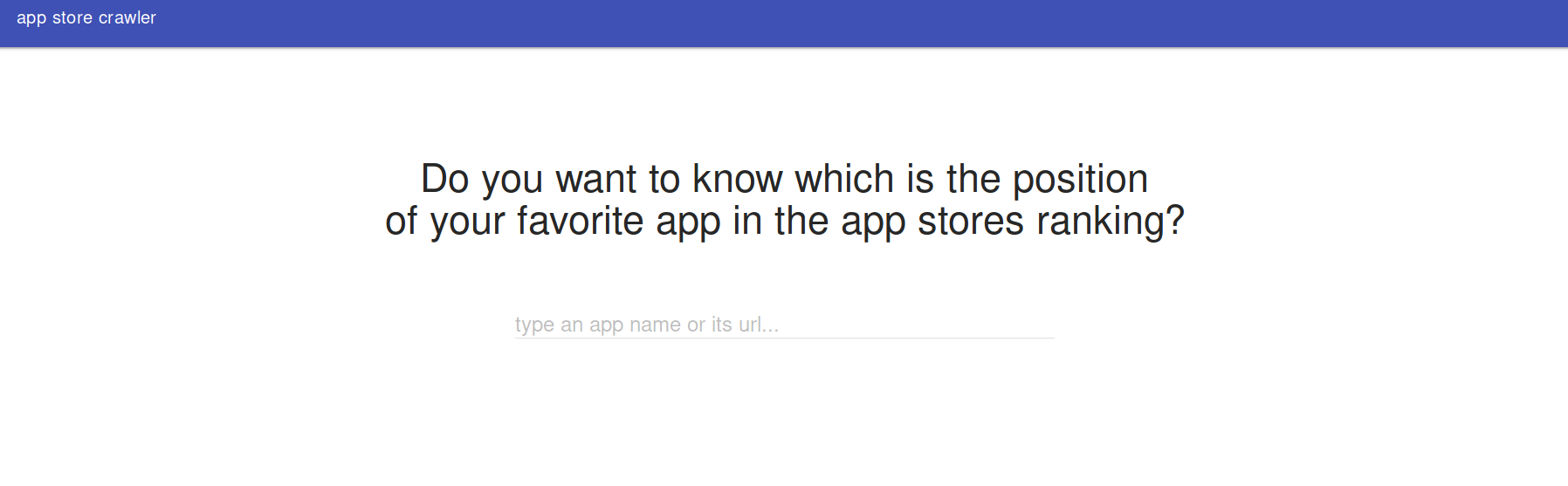
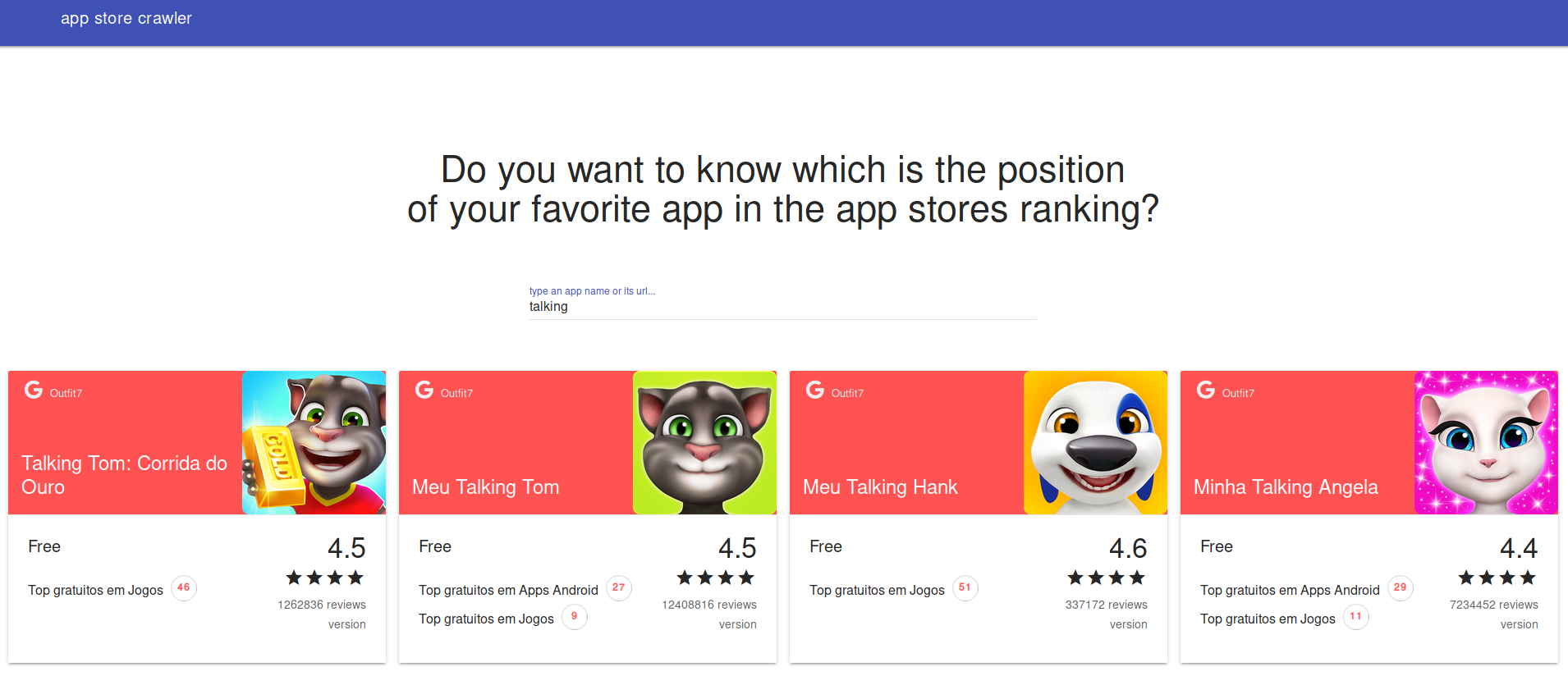
The UI
There is a simple UI using material design to query the results. Run a sample python server inside ui directory to make it run
python -m http.server
Open http://localhost:8000/ and there it is:
Tests
To run the tests, project root directory must be in PYTHONPATH:
PYTHONPATH=$PWD py.test