很多网站对爬虫都会有 IP 访问频率的限制。如果你的爬虫只用一个 IP 来爬取,那就只能设置爬取间隔,来避免被网站屏蔽。但是这样爬虫的效率会大大下降,这个时候就需要使用代理 IP 来爬取数据。一个 IP 被屏蔽了,换一个 IP 继续爬取。此项目就是提供给你免费代理的。
需要免费代理的可以试试,如果对您有帮助,希望给个 Star ⭐,谢谢!😁😘🎁🎉
Github 项目地址 gavin66 / proxy_list
-
爬取、验证、存储、Web API 多进程分工合作。
-
验证代理有效性时使用协程来减少网络 IO 的等待时间。
-
按照代理连接速度排序并持久化(目前使用 Redis)爬取下来的代理。
-
提供 Web API,随时提取与删除代理。
使用 Python3.6 开发的项目,没有对其他版本 Python 测试
代理的存储使用 Redis,所以你必须确保本机已安装它。
克隆源码
git clone git@github.com:gavin66/proxy_list.git安装依赖
推荐使用 virtualenv 来构建环境,防止冲突
pip install -r requirements.txt运行脚本
python run.py配置项都在 config 配置文件中,以下项可按你的需求修改
# 持久化
# 目前只支持 redis
# 这里只能修改你的 redis 连接字符串
PERSISTENCE = {
'type': 'redis',
'url': 'redis://127.0.0.1:6379/1'
}
# 协程并发数
# 爬取下来的代理测试可用性时使用,减少网络 io 的等待时间
COROUTINE_NUM = 50
# 保存多少条代理
# 默认200,如果存储了200条代理并不删除代理就不会再爬取新代理
PROXY_STORE_NUM = 300
# 如果保存的代理条数已到阀值,爬取进程睡眠秒数
# 默认60秒,存储满200条后爬虫进程睡眠60秒,醒来后如果还是满额继续睡眠
PROXY_FULL_SLEEP_SEC = 60
# 已保存的代理每隔多少秒检测一遍可用性
PROXY_STORE_CHECK_SEC = 1200
# web api
# 指定接口 IP 和端口
WEB_API_IP = '127.0.0.1'
WEB_API_PORT = '8111'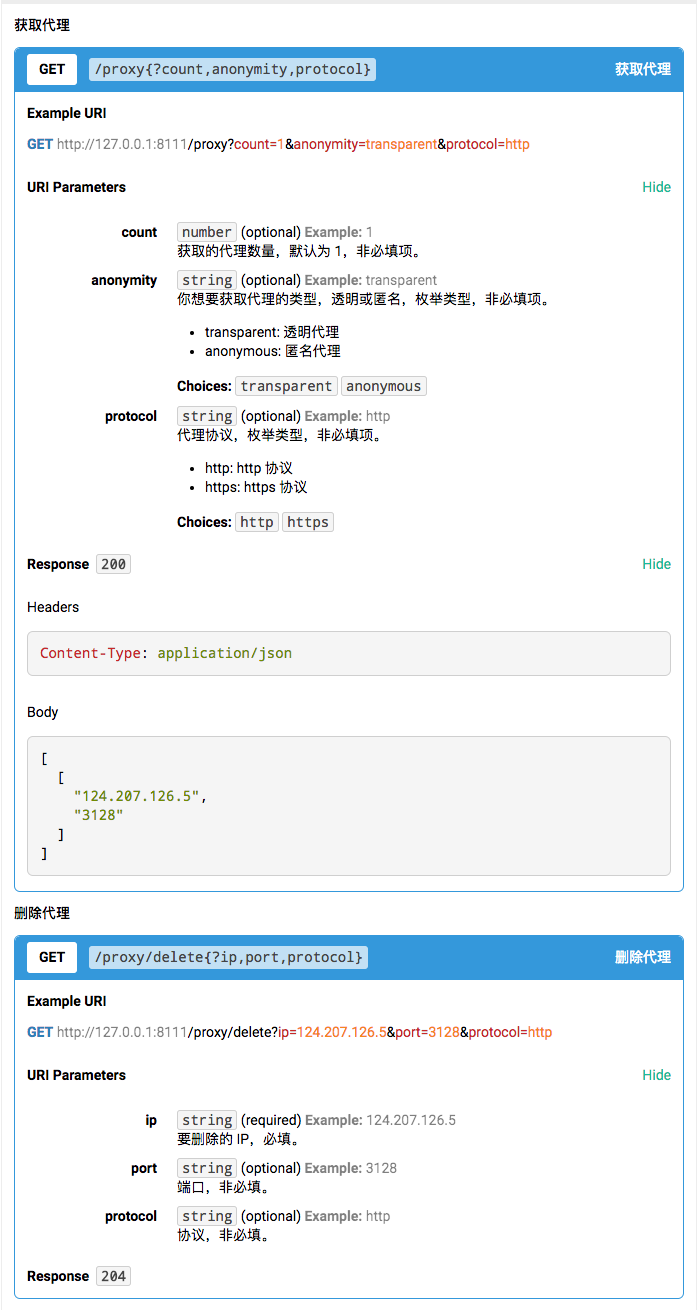
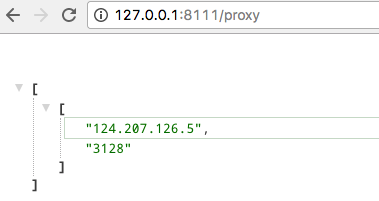
直接获取一个速度最快的代理
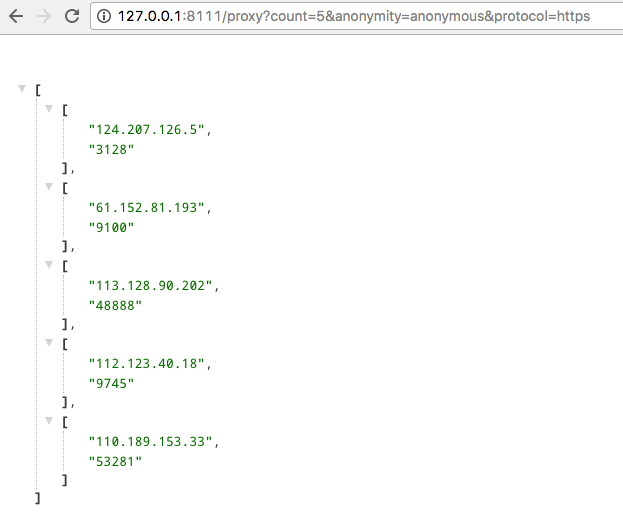
获取 https 的匿名代理,取前5个速度最快的