本项目用于英语文本多标签分类模型,使用框架为PyTorch。
数据集位于src/data目录, 数据来源网址为:https://datahack.analyticsvidhya.com/contest/janatahack-independence-day-2020-ml-hackathon.
该数据集是英语多标签分类数据集,每个数据样本由title, abstract及标签组成,共六个标签,分别为: Computer Science, Physics, Mathematics, Statistics, Quantitative Biology, Quantitative Finance.
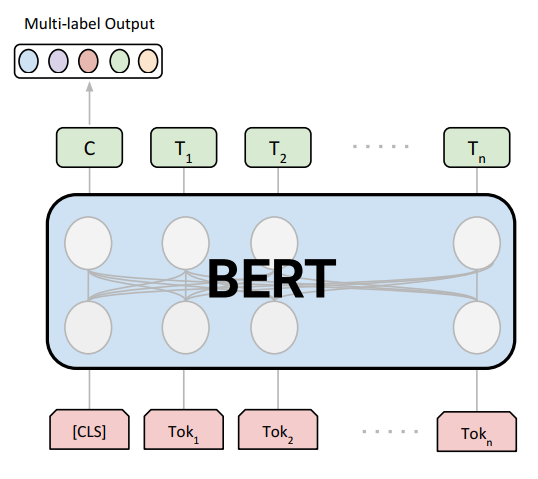
| 模型 | max length | batch size | private score | rank |
|---|---|---|---|---|
| bert-base-uncased | 128 | 32 | 0.8320 | 107 |
| bert-large-uncased | 128 | 16 | 0.8355 | 79 |
- https://jovian.ai/kyawkhaung/1-titles-only-for-medium
- https://datahack.analyticsvidhya.com/contest/janatahack-independence-day-2020-ml-hackathon
- Fine-tuned BERT Model for Multi-Label Tweets Classification: https://trec.nist.gov/pubs/trec28/papers/DICE_UPB.IS.pdf