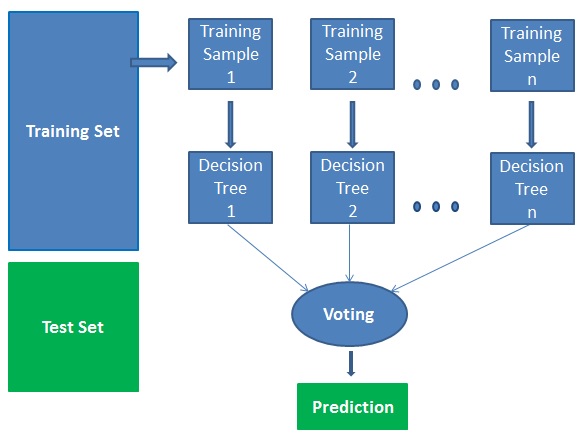
Random forests is a supervised learning algorithm. It can be used both for classification and regression. It is also the most flexible and easy to use algorithm. A forest is comprised of trees. It is said that the more trees it has, the more robust a forest is. Random forests creates decision trees on randomly selected data samples, gets prediction from each tree and selects the best solution by means of voting. It also provides a pretty good indicator of the feature importance.
It works in four steps:
- Select random samples from a given dataset.
- Construct a decision tree for each sample and get a prediction result from each decision tree.
- Perform a vote for each predicted result.
- Select the prediction result with the most votes as the final prediction.
https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.RandomForestClassifier.html
- min_samples_split (default value = 2) nodes cannot be further seperated below this value.
- criterion : optional (default=”gini”) It controls how a Decision Tree decides where to split the data. It is the measure of impurity in a bunch of examples. This parameter allows us to use the different-different attribute selection measure. Supported criteria are “gini” for the Gini index and “entropy” for the information gain.
- n_estimators(default value = 100 This parameter tells is the number of trees in the forest.
precision recall f1-score support
0 1.00 1.00 1.00 14
1 0.94 0.94 0.94 17
2 0.93 0.93 0.93 14
avg / total 0.96 0.96 0.96 45
precision recall f1-score support
0 1.00 1.00 1.00 14
1 1.00 0.94 0.97 17
2 0.93 1.00 0.97 14
avg / total 0.98 0.98 0.98 45
Finding important features or selecting features in the IRIS dataset.
