- Sign up for Vast.AI
- Add some funds (I typically add them in $10 increments)
- Navigate to the Client - Create page
- Select pytorch/pytorch as your docker image, and the buttons "Use Jupyter Lab Interface" and "Jupyter direct HTTPS"
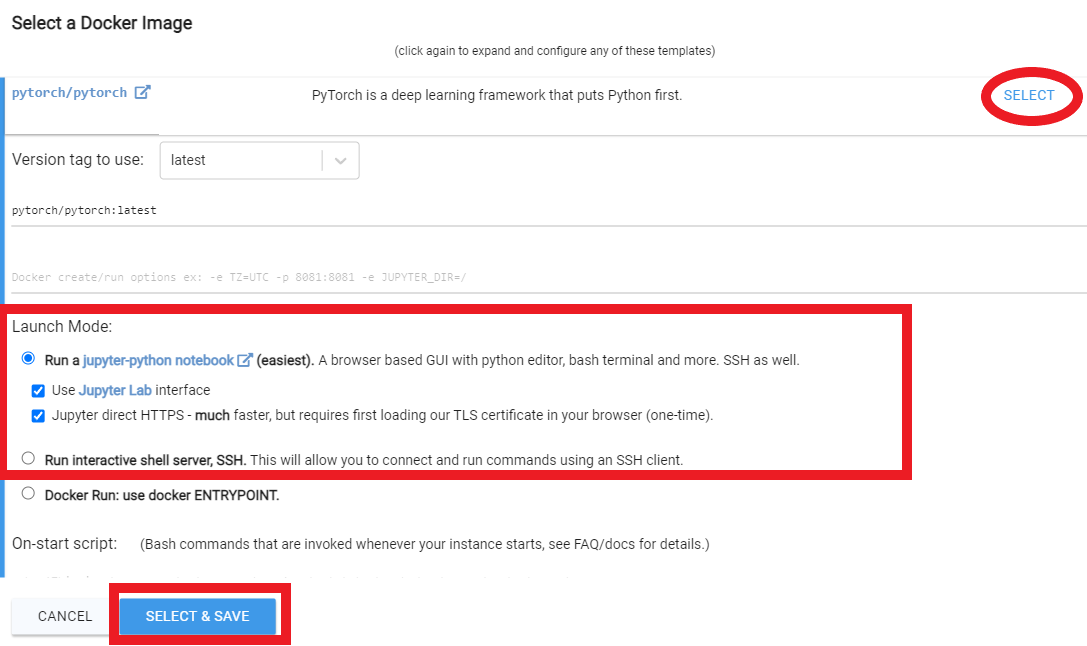
- You will want to increase your disk space, and filter on GPU RAM (12gb checkpoint files + 4gb model file + regularization images + other stuff adds up fast)
- I typically allocate 150GB
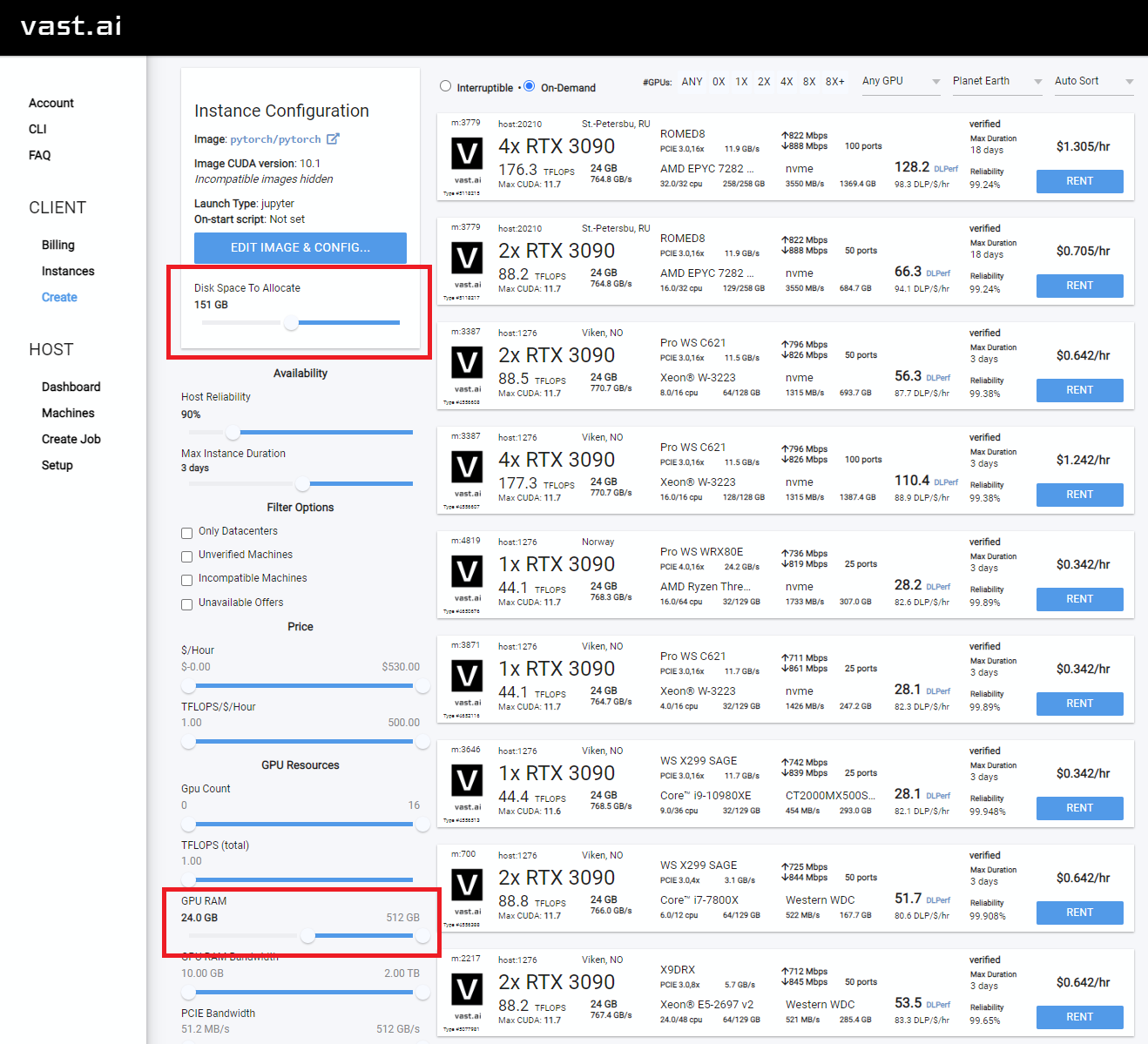
- Also good to check the Upload/Download speed for enough bandwidth so you don't spend all your money waiting for things to download.
- Select the instance you want, and click
Rent, then head over to your Instances page and clickOpen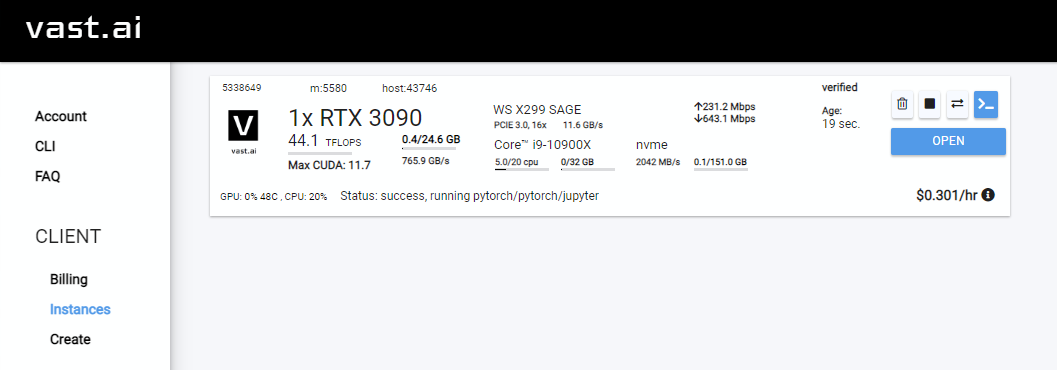
- You will get an unsafe certificate warning. Click past the warning or install the Vast cert.
- Click
Notebook -> Python 3(You can do this next step a number of ways, but I typically do this) - Clone Joe's repo with this command
!git clone https://github.com/JoePenna/Dreambooth-Stable-Diffusion.git- Click
run 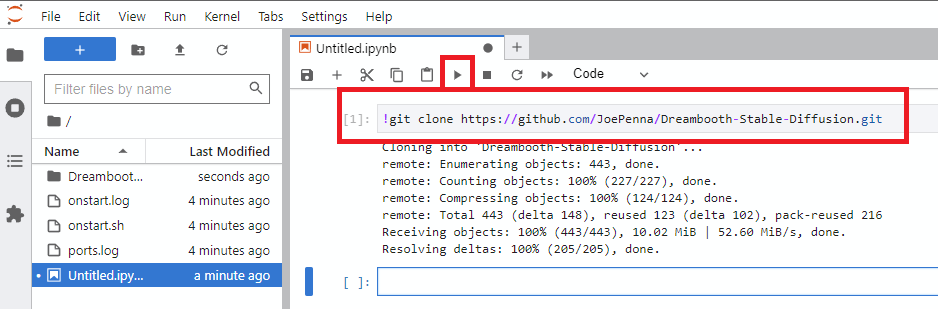
- Navigate into the new
Dreambooth-Stable-Diffusiondirectory on the left and open thedreambooth_runpod_joepenna.ipynbfile - Follow the instructions in the workbook and start training






The majority of the code in this repo was written by Rinon Gal et. al, the authors of the Textual Inversion research paper. Though a few ideas about regularization images and prior loss preservation (ideas from "Dreambooth") were added in, out of respect to both the MIT team and the Google researchers, I'm renaming this fork to: "The Repo Formerly Known As "Dreambooth"".
For an alternate implementation , please see "Alternate Option" below.
The ground truth (real picture, caution: very beautiful woman)

Same prompt for all of these images below:
sks person |
woman person |
Natalie Portman person |
Kate Mara person |
|---|---|---|---|
 |
 |
 |
 |
Prompting with just your token. ie "joepenna" instead of "joepenna person"
If you trained with joepenna under the class person, the model should only know your face as:
joepenna person
Example Prompts:
🚫 Incorrect (missing person following joepenna)
portrait photograph of joepenna 35mm film vintage glass
✅ This is right (person is included after joepenna)
portrait photograph of joepenna person 35mm film vintage glass
You might sometimes get someone who kinda looks like you with joepenna (especially if you trained for too many steps), but that's only because this current iteration of Dreambooth overtrains that token so much that it bleeds into that token.