Download U.S. census data and reformat it for humans.
All of the data files processed by this repository are published in the data/processed/ folder. They can be called in to applications via their raw URLs, like https://raw.githubusercontent.com/datadesk/census-data-downloader/master/data/processed/acs5_2017_population_counties.csv
The library can be installed as a command-line interface that lets you download files on demand.
$ pipenv install census-data-downloaderThere's now a tool named censusdatadownloader ready for you.
Usage: censusdatadownloader [OPTIONS] TABLE COMMAND [ARGS]...
Download Census data and reformat it for humans
Options:
--data-dir TEXT The folder where you want to download the data
--year [2009-2018] The years of data to download. By default it gets only the
latest year. Not all data are available for every year. Submit 'all' to get every year.
--force Force the downloading of the data
--help Show this message and exit.
Commands:
aiannhhomelands Download American Indian, Alaska Native and...
cnectas Download combined New England city and town...
congressionaldistricts Download Congressional districts
counties Download counties in all states
csas Download combined statistical areas
divisions Download divisions
elementaryschooldistricts Download elementary school districts
everything Download everything from everywhere
msas Download metropolitian statistical areas
nationwide Download nationwide data
nectas Download New England city and town areas
places Download Census-designated places
pumas Download public use microdata areas
regions Download regions
secondaryschooldistricts Download secondary school districts
statelegislativedistricts Download statehouse districts
states Download states
tracts Download Census tracts
unifiedschooldistricts Download unified school districts
urbanareas Download urban areas
zctas Download ZIP Code tabulation areasBefore you can use it you will need to add your CENSUS_API_KEY to your environment. If you don't have an API key, you can go here. One quick way to add your key:
$ export CENSUS_API_KEY='<your API key>'Using it is as simple as providing one our processed table names to one of the download subcommands.
Here's an example of downloading all state-level data from the medianage dataset.
$ censusdatadownloader medianage statesYou can specify the download directory with --data-dir.
$ censusdatadownloader --data-dir ./my-special-folder/ medianage statesAnd you can change the year you download with --year.
$ censusdatadownloader --year 2010 medianage statesThat's it. Mix and match tables and subcommands to get whatever you need.
You can also download tables from Python scripts. Import the class of the processed table you wish to retrieve and pass in your API key. Then call one of the download methods.
This example brings in all state-level data from the medianhouseholdincomeblack dataset.
>>> from census_data_downloader.tables import MedianHouseholdIncomeBlackDownloader
>>> downloader = MedianHouseholdIncomeBlackDownloader('<YOUR KEY>')
>>> downloader.download_states()You can specify the data directory and the years by passing in the data_dir and years keyword arguments.
>>> downloader = MedianHouseholdIncomeBlackDownloader('<YOUR KEY>', data_dir='./', years=2016)
>>> downloader.download_states()A gallery of graphics powered by our data is available on Observable.
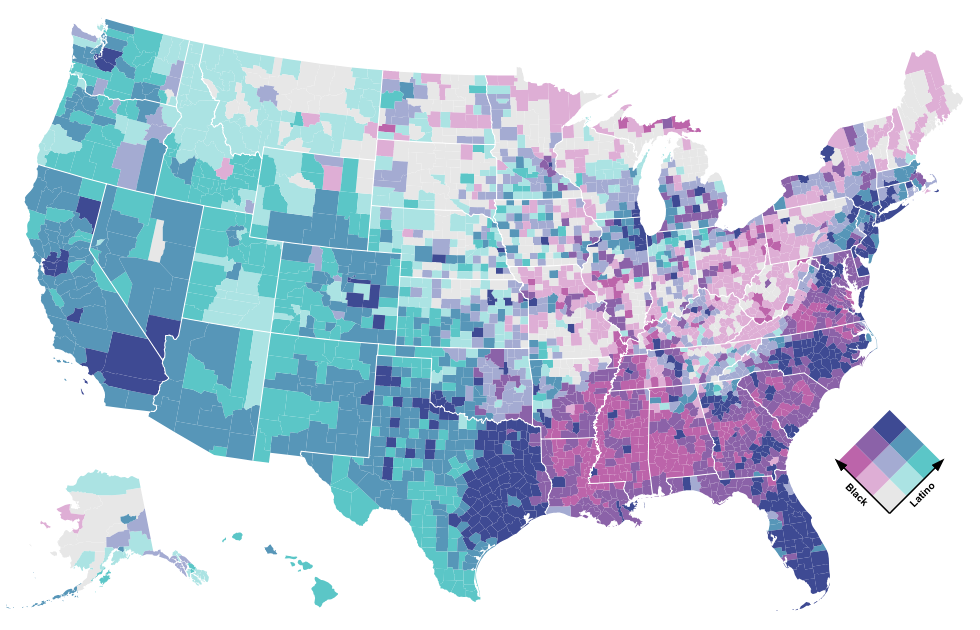
The Los Angeles Times used this library for an analysis of Census undercounts on Native American reservations. The code that powers it is available as an open-source computational notebook.

Subclass our downloader and provided it with its required inputs.
import collections
from census_data_downloader.core.tables import BaseTableConfig
from census_data_downloader.core.decorators import register
@register
class MedianHouseholdIncomeDownloader(BaseTableConfig):
PROCESSED_TABLE_NAME = "medianhouseholdincome" # Your humanized table name
UNIVERSE = "households" # The universe value for this table
RAW_TABLE_NAME = 'B19013' # The id of the source table
RAW_FIELD_CROSSWALK = collections.OrderedDict({
# A crosswalk between the raw field name and our humanized field name.
"001": "median"
})Add it to the imports in the __init__.py file and it's good to go.
The command-line interface is implemented using Click and setuptools. To install it locally for development inside your virtual environment, run the following installation command, as prescribed by the Click documentation.
$ pip install --editable .That's it. If you make some good ones, please consider submitting them as pull requests so everyone can benefit.