This repository contains a PyTorch implementation of the albert model from the paper
A Lite Bert For Self-Supervised Learning Language Representations
by Zhenzhong Lan. Mingda Chen....
arxiv: https://arxiv.org/pdf/1909.11942.pdf
说明:
- 本代码在huggingface代码基础上适配brightmart提供的中文模型权重,当然也可以基于此代码进行训练albert.
- 如果只想加载和转换预训练模型,可以参考chineseGLUE,该版本比较简洁。
- pytorch版本为1.1.0 ,cuda版本为9.0
-
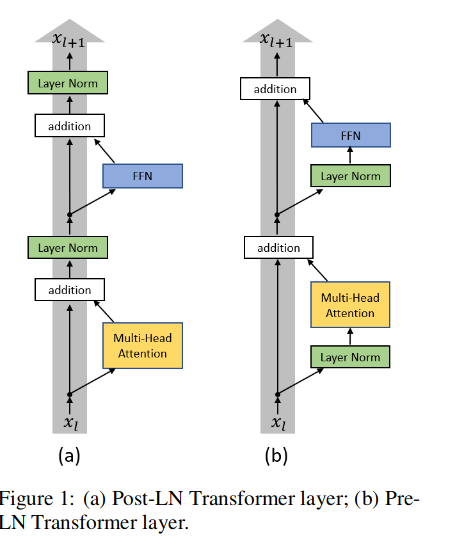
Post-LN: . 在原始的Transformer中,Layer Norm在跟在Residual之后的,我们把这个称为
Post-LN Transformer -
Pre-LN: 把Layer Norm换个位置,比如放在Residual的过程之中(称为
Pre-LN Transformer)
使用方式
按照brightmart大佬提供的模型权重文件,需要在配置文件中添加ln_type参数,如下:
{
"attention_probs_dropout_prob": 0.0,
"directionality": "bidi",
"hidden_act": "gelu",
"hidden_dropout_prob": 0.0,
"hidden_size": 768,
"embedding_size": 128,
"initializer_range": 0.02,
"intermediate_size": 3072 ,
"max_position_embeddings": 512,
"num_attention_heads": 12,
"num_hidden_layers": 12,
"pooler_fc_size": 768,
"pooler_num_attention_heads": 12,
"pooler_num_fc_layers": 3,
"pooler_size_per_head": 128,
"pooler_type": "first_token_transform",
"type_vocab_size": 2,
"vocab_size": 21128,
"ln_type":"postln" /**postln or preln**/
}Cross-Layer Parameter Sharing: ALBERT use cross-layer parameter sharing in Attention and FFN(FeedForward Network) to reduce number of parameter.
modify the share_type parameter:
- all: attention和FFN层参数都共享
- ffn: 只共享FFN层参数
- attention: 只共享attention层参数
- None: 无参数共享
使用方式
在加载config时,指定share_type参数,如下:
config = BertConfig.from_pretrained(bert_config_file,share_type=share_type)如果你是加载预训练模型权重,share_type=all.
感谢brightmart大佬提供中文模型权重:下载地址
n-gram: 原始论文中按照以下分布随机生成n-gram,默认max_n为3

2. 运行以下命令:
python prepare_lm_data_ngram.py \
--data_dir=dataset/ \
--vocab_path=vocab.txt \
--data_name=albert \
--max_ngram=3 \
--do_data产生n-gram masking数据集,具体可根据对应数据进行修改代码
3.运行以下命令:
python run_pretraining.py \
--data_dir=dataset/ \
--vocab_path=configs/vocab.txt \
--data_name=albert \
--config_path=configs/albert_config_base.json \
--output_dir=outputs/ \
--data_name=albert \
--share_type=all进行模型训练,具体可根据对应数据进行修改代码
模型大小
以下是对albert-base进行实验的结果
| embedding_size | share_type | model_size |
|---|---|---|
| 768 | None | 476.5M |
| 768 | attention | 372.4M |
| 768 | ffn | 268.6M |
| 768 | all | 164.6M |
| 128 | None | 369.1M |
| 128 | attention | 265.1M |
| 128 | ffn | 161.2M |
| 128 | all | 57.2M |
1.下载tf版本预训练的albert模型
2.运行以下命令:
python convert_albert_tf_checkpoint_to_pytorch.py \
--tf_checkpoint_path=./prev_trained_model/albert_tiny_tf \ #tf模型目录
--bert_config_file=./prev_trained_model/albert_tiny_tf/albert_config_tiny.json \ # 配置文件路径
--pytorch_dump_path=./prev_trained_model/albert_tiny/pytorch_model.bin # 转换模型保存路径将TF模型权重转化为pytorch模型权重(默认情况下shar_type=all)。
注意,如果需要运行该classifier.py脚本,需要将配置文件和vocab.txt文件同时放入上面转换模型的目录中,比如:
├── prev_trained_model
| └── albert_base
| | └── pytorch_model.bin
| | └── config.json
| | └── vocab.txt
3.下载对应的数据集,比如LCQMC数据集,包含训练、验证和测试集,训练集包含24万口语化描述的中文句子对,标签为1或0。1为句子语义相似,0为语义不相似。
4.运行sh run_classifier_lcqmc.sh进行Fine-tuning训练
问题匹配语任务:LCQMC(Sentence Pair Matching)
| 模型 | 开发集(Dev) | 测试集(Test) |
|---|---|---|
| albert_base(tf) | 86.4 | 86.3 |
| albert_base(pytorch) | 87.4 | 86.4 |
| albert_tiny | 85.1 | 85.3 |