


Visualizes duration and CPU usage of blocks of code to let you see bottlenecks in your applications.
To use Waterfalls, you mark the blocks of code in your application that you want to time and then run the application as you normally do. Waterfalls runs in the background and collects the data. When your application exits, Waterfalls automatically generates and saves a report.
To see the report, you use the waterfalls command which shows the timings as a waterfall diagram.
It is much easier to understand the application flow when you see it, rather than trying to decipher timestamps printed to the console.
Waterfalls handles also applications that use threading and multiprocessing.
The tool is very lightweight and has a negligible impact on the main program. All slower tasks (e.g., saving reports to disk) are delayed until after the main program finishes.
import tarfile
import urllib.request
from waterfalls import Timer
URLS = [
"https://www.python.org/",
"https://pypi.org/",
"https://github.com/",
]
for i, url in enumerate(URLS):
with Timer("Download site"):
with urllib.request.urlopen(url) as conn:
html = conn.read()
with Timer("Save as HTML"):
with open(f"{i}.html", "wb") as file:
file.write(html)
with Timer("Save as TAR"):
with tarfile.open(f"{i}-xz.tar", "w:xz") as tar:
tar.add(f"{i}.html")The program downloads sites from a list of URLs, saves each to an HTML file, and finally compresses the HTML file into a TAR file.
We use waterfalls.Timer to define each of the 3 logical steps.
When we run the program, Waterfalls automatically saves a waterfalls.json file to the current working directory.
We can now type the waterfalls command which will display it as an interactive diagram.
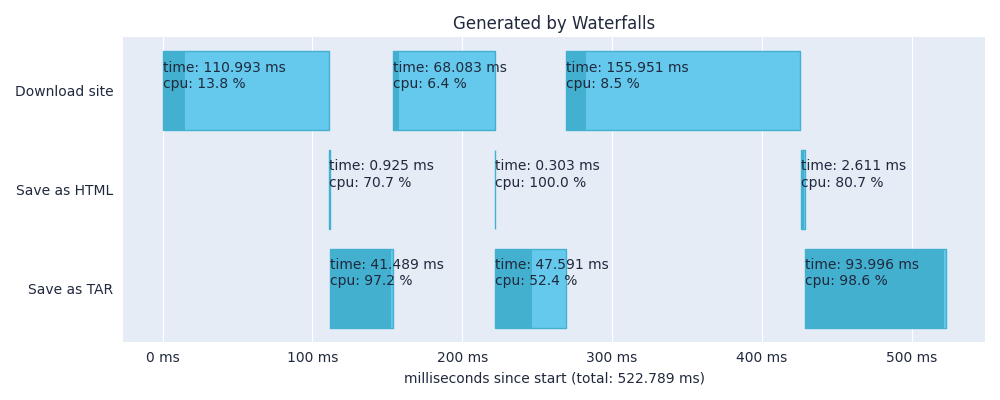
Looking at the diagram, we immediately see that the program spends a lot of time downloading each site. During these periods, nothing else is happening, the CPU usage is very low and the program is generally wasting time. We can certainly improve on that. In the section Advanced examples, we will refactor the program to take advantage of multiple threads and use Waterfalls to analyze the refactored program.
Waterfalls requires Python 3.8+ to run.
pip install waterfallsMark the sections of the code you want to measure.
First, create one or more timers. A timer typically represents one logical activity, for example, Download site.
The timer corresponds to one row in the diagram. It gives the row its name.
One timer can have one or more blocks, for example, one for each site that is being downloaded.
Each block must be started (start()) and stopped (stop()).
All blocks will be placed on the timer row from left to right, showing exactly when they were started and stopped.
from waterfalls import Timer
t = Timer("Download site")
t.start()
# Download site A
t.stop()
t.start()
# Download site B
t.stop()For convenience, Timer can also be used as a context manager or as a decorator.
with Timer("Download site"):
# Download site C@Timer("Download site")
def download_function():
# Download site DSometimes it can be useful to add custom text to the timing blocks, for example, to record the concrete value that is being processed. This text will then be displayed in the diagram on top of its corresponding block.
The text can be defined when calling the start() method.
t = Timer("Download site")
t.start(text="www.python.org")
# Download www.python.org
t.stop()
t.start(text="pypi.org")
# Download pypi.org
t.stop()It can also be defined when using Timer as a context manager or decorator.
with Timer("Download site", text="www.python.org"):
# Download www.python.org
with Timer("Download site", text="pypi.org"):
# Download pypi.org@Timer("Download site", text="www.python.org")
def download_function():
# Download www.python.org
@Timer("Download site", text="pypi.org")
def download_function():
# Download pypi.orgSometimes the text isn't known at the moment of the block's start. For example, it may be obtained during the block's execution.
In this case, you can define it in the stop() method.
t = Timer("Download site")
t.start()
# Download github.com
# Save response size to `bytes_len`
t.stop(text=bytes_len)When using Timer as a context manager, text can also be set after initiation - using an instance attribute.
with Timer("Download site") as t:
# Download github.com
# Save response size to `bytes_len`
t.text = bytes_lenNote that while
textcan be set at nearly every step of the block's lifecycle, only the last value will be saved in the report.
By default, the report file will be saved to the current working directory.
To choose a different directory, you can set Timer.directory anywhere in the code.
Timer.directory = "/path/to/reports/"You can also use the WATERFALLS_DIRECTORY environment variable.
export WATERFALLS_DIRECTORY=/path/to/reports/To see the diagram, use the waterfalls command. By default, it will look for report files in the current working directory.
If you want to search in another location, you can specify the directory.
waterfalls "/path/to/reports/"The command supports the following arguments.
Positional arguments:
directory: Directory containing report file(s) generated by waterfalls.Timer. By default, the current working directory is used.
Optional arguments:
-u,--unit{nsec,usec,msec,sec,min,hour}: Specifies time unit. By default, the time unit is determined automatically.-t,--thread_id: Shows thread ID next to each timer. By default, thread ID is hidden and only shown to distinguish overlapping blocks belonging to the same timer.-l,--lines: Shows horizontal lines in the graph.-i,--image: Saves diagram as an image (waterfalls.svg) to the reports directory instead of launching interactive window.
When we timed the program in the section Basic example, we noticed that it spends a lot of time downloading the websites and the CPU usage is very low.
This type of program should benefit from using multiple threads so we will refactor it and use ThreadPoolExecutor.
We will instruct Waterfalls to save the report file to the ./thread_pool_records/ directory.
We will also pass the Download site timer a text containing the domain that is being downloaded so the diagram becomes even clearer.
import concurrent.futures
import tarfile
from urllib.parse import urlparse
import urllib.request
from waterfalls import Timer
URLS = [
"https://www.python.org/",
"https://pypi.org/",
"https://github.com/",
]
Timer.directory = "./thread_pool_records/"
def save_site(i, url):
netloc = urlparse(url).netloc
with Timer("Download site", text=netloc):
with urllib.request.urlopen(url) as conn:
html = conn.read()
with Timer("Save as HTML"):
with open(f"{i}.html", "wb") as file:
file.write(html)
with Timer("Save as TAR"):
with tarfile.open(f"{i}-xz.tar", "w:xz") as tar:
tar.add(f"{i}.html")
with concurrent.futures.ThreadPoolExecutor(max_workers=len(URLS)) as executor:
executor.map(save_site, range(len(URLS)), URLS)After we run the program, there will be a new directory (thread_pool_records) in our current working directory.
We can now launch the Waterfalls viewer. We will also use the --thread_id flag to tell Waterfalls to show the thread ID belonging to each timer.
waterfalls "./thread_pool_records/" --thread_id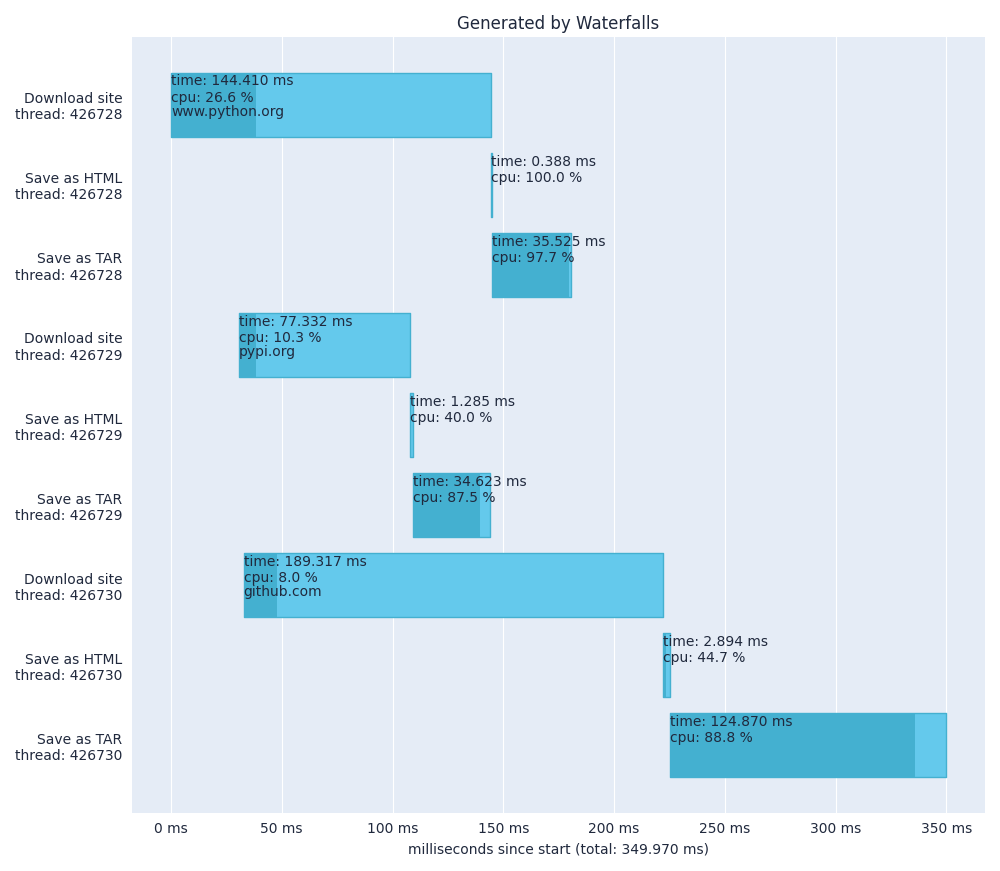
Main observations:
- We can see that all sites are being downloaded concurrently, reducing the total time needed to run the program.
- It takes around 350 ms to download, save and compress all 3 sites. (It was over 520 ms for the single-threaded version.)
pypi.orgis the quickest site to be downloaded,github.comis the slowest.- Creating the TAR files is very CPU-intensive. However, multiprocessing would not help here since the TARs are created at different times and do not compete for the CPU.
We have a program that determines if a number from a list is prime or not. We will add waterfalls.Timer called Determine prime to time the program.
import math
from waterfalls import Timer
NUMBERS = [112272535095293, 112582705942171, 115280095190773, 115797848077099, 1099726899285419]
Timer.directory = "./prime_records/"
for number in NUMBERS:
with Timer("Determine prime") as t:
not_prime = False
if number > 1:
for i in range(2, math.floor(math.sqrt(number) + 1)):
if (number % i) == 0:
not_prime = True
break
t.text = f"{number}\nnot prime" if not_prime else f"{number}\nis prime"After the program finishes, we will launch the viewer.
waterfalls "./prime_records/"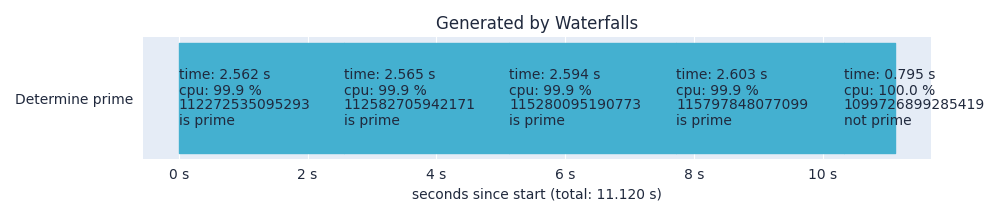
We can immediately see that determining whether a number is prime or not uses almost 100% CPU.
But the computer has multiple CPU cores so we can take advantage of multiprocessing to speed up the program.
We will use the ProcessPoolExecutor.
We will also change the reports directory to ./prime_multiprocessing_records/.
import concurrent.futures
import math
from waterfalls import Timer
NUMBERS = [112272535095293, 112582705942171, 115280095190773, 115797848077099, 1099726899285419]
Timer.directory = "./prime_multiprocessing_records/"
def determine_prime(number):
with Timer("Determine prime") as t:
not_prime = False
if number > 1:
for i in range(2, math.floor(math.sqrt(number) + 1)):
if (number % i) == 0:
not_prime = True
break
t.text = f"{number}\nnot prime" if not_prime else f"{number}\nis prime"
if __name__ == "__main__":
with concurrent.futures.ProcessPoolExecutor(max_workers=2) as executor:
executor.map(determine_prime, NUMBERS)After the program finishes, we can open the ./prime_multiprocessing_records/ directory where we will find 2 report files - one for each process.
They are differentiated by their process ID: waterfalls.<process_id>.json.
We use the viewer the same way we did before - the viewer automatically combines all record files in the directory into a unified view.
waterfalls "./prime_multiprocessing_records/"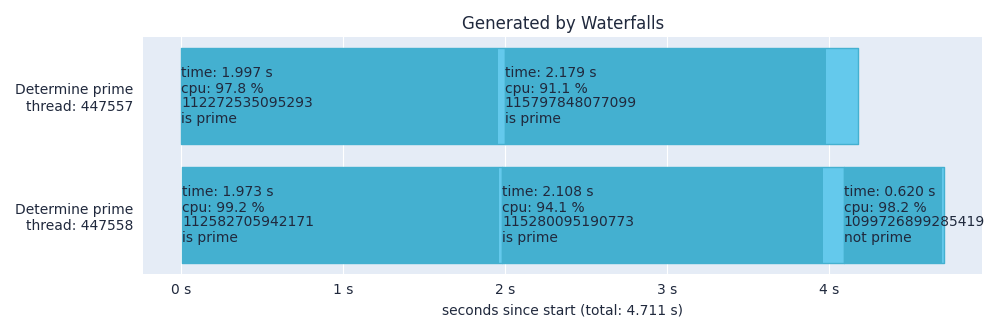
Main observations:
- We can see that the refactored program can analyze 2 numbers in parallel.
- It takes around 4.7 s to finish the analysis. (It was over 11 s for the version using a single process.)