The model for training the bird classifier.
The complete list of JibJib repos is:
- jibjib: Our Android app. Records sounds and looks fantastic.
- deploy: Instructions to deploy the JibJib stack.
- jibjib-model: Code for training the machine learning model for bird classification
- jibjib-api: Main API to receive database requests & audio files.
- jibjib-data: A MongoDB instance holding information about detectable birds.
- jibjib-query: A thin Python Flask API that handles communication with the TensorFlow Serving instance.
- gopeana: A API client for Europeana, written in Go.
- voice-grabber: A collection of scripts to construct the dataset required for model training
In vggish_train.py we are training a convolutional classifier model for an arbitrary number of birds. We take a pretrained VGGish/ Audioset model by Google and finetune it by letting it iterate during training on more than 80,000 audio samples of 10 second length. Please read the following papers for more information:
- Hershey, S. et. al., CNN Architectures for Large-Scale Audio Classification, ICASSP 2017
- Gemmeke, J. et. al., AudioSet: An ontology and human-labelled dataset for audio events, ICASSP 2017
Before you can start, you first need to download a VGGish checkpoint file. You can either use a checkpoint provided by or

The original final layer is cut off and replaced with our own output nodes.
During the first training step a directory containing labeled bird songs is iterated over and each .wav file is converted into a spectrogram where the x-axis is the time and the y-axis symbolyzes the frequency. For instance, this is the spectrogram of a golden eagles call:

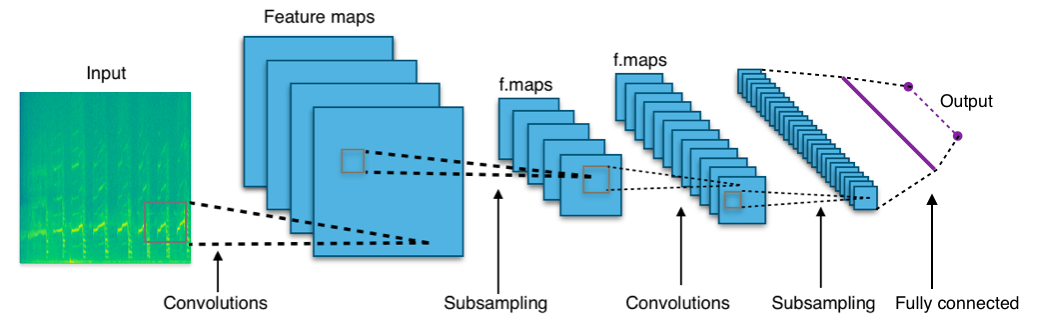
Furthermore, each bird class is one-hot-encoded and then in pairs of features and corresponding labels fed into the model. After, VGGish's convolutional filters run over each spectrogram and extract meaningful features. The following graphic gives a short overview about how after some convolutions and subpooling the extracted features are then fed into the fully connected layer just like in any other CNN:
After every epoch a snapshot of the models weights and biases is saved on disk. In the next step we can restore the model to either do a query or continue with training.
We are deploying the model by enabling TensorFlow Serving to reduce response time drastically. Check out to learn more about how we implemented TensorFlow Serving for our model.
In train_LSTM.py we provide a Convolutional LSTM for audio event recognition. Similar to vggish_train.py it performs classification tasks on mel spectrograms. In contrast to vggish_train.py, it does not perform a classification for each spectrogram but analyzes an array of matrices and then performs a single classification on the entire sequence. C-LSTMs may outperform traditional CNNs when data only contains sparse specific features or when audio scenes are event-rich with many overlapping signals. The script train_LSTM.py uses the same input function as in vggish_train.py converting .wav files into their audio footprint using mel-frequency cepstral coeeficients, separating each file into 1 second frame where each frame is made up of mel features. Simultaneously, the corresponding labels are extracted, one-hot-encoded and shown to our model further downstream at the fully connected layer. The script uses Keras as a TensorFlow wrapper to build the model and is compatible with Python3.6 or upwards.
Get the container:
# GPU, needs nvidia-docker installed
docker pull obitech/jibjib-model:latest-gpu
# CPU
docker pull obitech/jibjib-model:latest-cpu
Create folders, if necessary:
mkdir -p output/logs output/train output/model input/data
Get the audioset checkpoint:
curl -O input/vggish_model.ckpt https://storage.googleapis.com/audioset/vggish_model.ckpt
Copy all training folders / files into input/data/
Get the bird_id_map.pickle:
curl -O input/bird_id_map.pickle https://github.com/gojibjib/voice-grabber/raw/master/meta/bird_id_map.pickle
Run the container:
docker container run --rm -d \
--runtime=nvidia \
-v $(pwd)/input:/model/input \
-v $(pwd)/output:/model/output \
obitech/jibjib-model:latest-gpu
For quickly starting training run:
# GPU
./train_docker.sh
# CPU
./train_docker.sh
Clone the repo:
git clone https://github.com/gojibjib/jibjib-model
Install dependencies, use python3.6 or upwards:
# CPU training
pip install -r requirements.txt
# GPU training
pip install -r requirements-gpu.txt
Copy all training folders / files into input/data/
Get the audioset checkpoint:
curl -O input/vggish_model.ckpt https://storage.googleapis.com/audioset/vggish_model.ckpt
Get the bird_id_map.pickle:
curl -O input/bird_id_map.pickle https://github.com/gojibjib/voice-grabber/raw/master/meta/bird_id_map.pickle
Start training:
# Make sure to start the script from the code/ directory !
cd code
python ./vggish_train.py
You can then use modelbuilder.py to convert the model to protocol buffer.