A joint multi-modal space for images and words with semantic structure has been learnt from Social Media data in a self-supervised way. This demo lets explore that space, using words and images as queries, and allowing to perform arithmetics between them.
Find the running demo here!
This demo shows the work in the following publications. Read them to understand what is it showing.
Learning to Learn from Web Data through Deep Semantic Embeddings
ECCV MULA workshop, 2018.
Self-Supervised Learning from Web Data for Multimodal Retrieval
Book Chapter submitted to Multi-Modal Scene Understanding.
The work is also explained in a more informal way in this blog posts:
Learning Image Topics from Instagram to Build an Image Retrieval System
What Do People Think about Barcelona?
Learning to Learn from Web Data
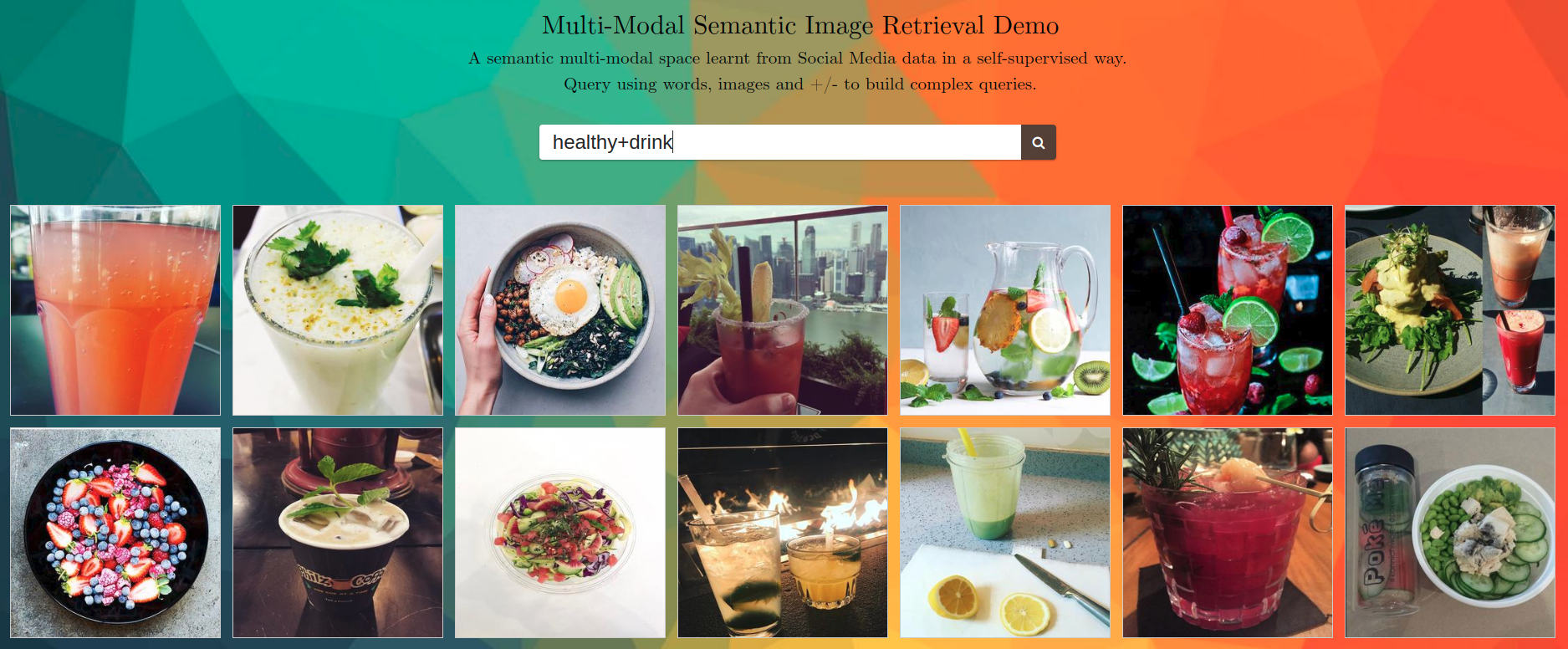
We downloaded 1M of Instagram images with their associated captions. We trained a word embedding model using those captions. This model learns nearby representations of words that are semantically similar, and the resulting word embedding space has a semantic structure. Several works have shown that we can navigate though word representations in that space doing arithmetics between words representations (ex.: king + woman = queen). Then, we trained a CNN to embed images in that space, in the same point as their associated caption. The result is that we are able to generate multi-modal embeddings (for images and text) in an space with semantic structure. At the end, we have a system that can compute semantic similarities between words and images. This demo shows an straight forward application of it: Multi-Modal Semantic Image Retrieval.
This Demo uses GloVe word embeddings. The CNN to generate the image embeddings in the GloVe space has been trained with a contrastive loss, using soft negative captions as negative samples. This differs with the loss used in the papers, which was a Cross-Entropy Loss to directly regress text embeddings. Contrastive loss has lead to significantly better results in later, not published yet, experiments.
The GloVe model and CNN used in this demo have been trained with the InstaCities1M dataset, so expect a superior performance for queries related to Instagram typical posts and to cities featured in the dataset. Go explore!
america
england
sydney
flag
healthy
happyness
music
eye
hairstyle
watch
work
people+park
bike+park
bike-park
beach+sunrise
beach-sunrise
car+yellow
car-yellow
cold
cold-snow
train
train-car
paint
travel+paint
fish
fish+food
Retrieved images can be used as queries. Click an image to use it as a query. Several images and words can be combined in a single query.
[IMG_1]+park
[IMG_3]-dog
[IMG_1]+[IMG_10]
Sometimes, to get the desired output you might want to give more weight to a term in the query:
[IMG_1]+park+park+park
This demo is based on the YOLO-PHOC_WebDemo by Lluis Gómez https://github.com/lluisgomez/YOLO-PHOC_WebDemo
This demo depends on pywebsocket. Clone it with:
git clone https://github.com/google/pywebsocket.git
and follow the instructions in README.
It also uses a C program to build PHOC descriptors of the query strings. The cphoc library must be compiled as follows:
cd MMSemanticRetrievalDemo/pywebsocket/cphoc/
gcc -c -fPIC `python-config --cflags` cphoc.c
gcc -shared -o cphoc.so cphoc.o `python-config --ldflags`
Run the WebSocket standalone server:
cd MMSemanticRetrievalDemo/pywebsocket/
sudo python standalone.py -p 9998 -w ./
the server takes some time to initialize (loading the models and the image embeddings).
Open the index.html web interface in a HTML5 capable browser. E.g.:
cd MMSemanticRetrievalDemo/
google-chrome index.html