| description |
|---|
Apache Pinot, a real-time distributed OLAP datastore, purpose-built for low-latency high throughput analytics, perfect for user-facing analytical workloads. |
Join us in our Slack channel for questions, troubleshooting, and feedback. You can request an invite from - https://communityinviter.com/apps/apache-pinot/apache-pinot.
{% hint style="info" %} We'd love to hear from you! {% endhint %}
Pinot is a real-time distributed OLAP datastore, purpose-built to provide ultra low-latency analytics, even at extremely high throughput. It can ingest directly from streaming data sources - such as Apache Kafka and Amazon Kinesis - and make the events available for querying instantly. It can also ingest from batch data sources such as Hadoop HDFS, Amazon S3, Azure ADLS, and Google Cloud Storage.
At the heart of the system is a columnar store, with several smart indexing and pre-aggregation techniques for low latency. This makes Pinot the most perfect fit for user-facing realtime analytics. At the same time, Pinot is also a great choice for other analytical use-cases, such as internal dashboards, anomaly detection, and ad-hoc data exploration.
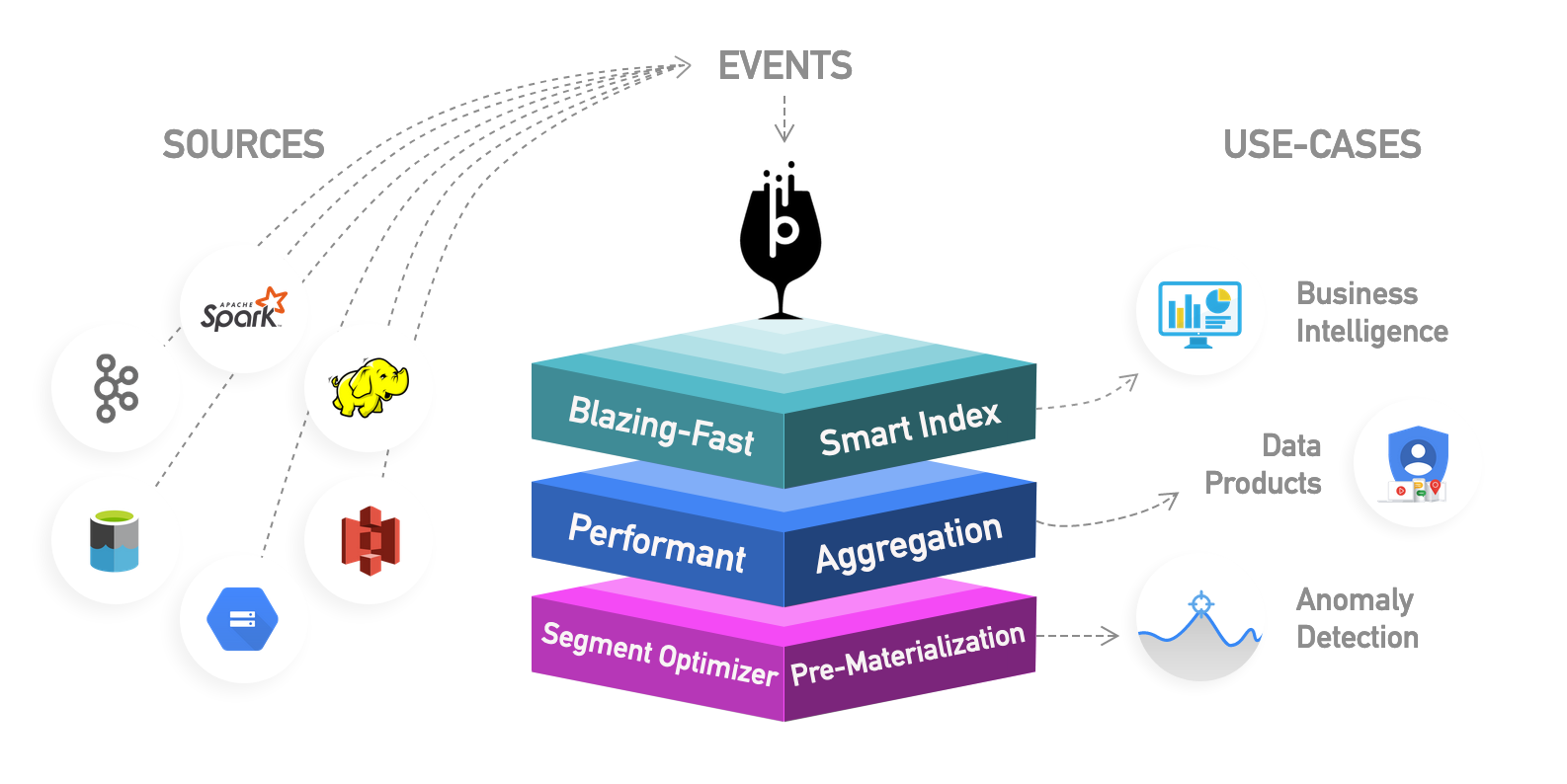
Pinot was built by engineers at LinkedIn and Uber and is designed to scale up and out with no upper bound. Performance always remains constant based on the size of your cluster and an expected query per second (QPS) threshold.
{% embed url="https://youtu.be/_lqdfq2c9cQ" %} What is Apache Pinot? (and User-Facing Analytics) by Tim Berglund {% endembed %}
User-facing analytics, or site-facing analytics, is the analytical tools and applications that you would expose directly to the end-users of your product. In a user-facing analytics application, think of the user-base as ALL end users of an App. This App could be a social networking app, or a food delivery app - anything at all. It’s not just a few analysts doing offline analysis, or a handful of data scientists in a company running ad-hoc queries. This is ALL end-users, receiving personalized analytics on their personal devices (think 100s of 1000s of queries per second). These queries are triggered by apps, and not written by people, and so the scale will be as much as the active users on that App (think millions of events/sec)
And, this is for all the freshest possible data, which touches on the other aspect here - realtime analytics. "Yesterday" might be a long time ago for some businesses and they cannot wait for ETLs and batch jobs. The data needs to be used for analytics, as soon as it is generated (think latencies < 1s).
Wanting such a user-facing analytics application, using realtime events, sounds great. But what does it mean for the underlying infrastructure, to support such an analytical workload?

- Such applications require the freshest possible data, and so the system needs to be able to ingest data in real time and make it available for querying, also in real time.
- Data for such apps tend to be event data, for a wide range of actions, coming from multiple sources, and so the data comes in at a very high velocity and tends to be highly dimensional.
- Queries are triggered by end-users interacting with apps - with queries per second in hundreds of thousands, with arbitrary query patterns, and latencies are expected to be in milliseconds for good user-experience.
- And further do all of the above, while being scalable, reliable, highly available, and having a low cost to serve.
This video talks more about user-facing real-time analytics, and how Pinot is used to achieve that.
{% embed url="https://www.youtube.com/watch?v=L5b_OJVOJKo&t=576s" %} Using Kafka and Pinot for Real-time User-facing Analytics {% endembed %}
Here's another great video that goes into the details of how Pinot tackles some of the challenges faced in handling a user-facing analytics workload.
{% embed url="https://youtu.be/JV0WxBwJqKE" %} Building Latency Sensitive User-facing Analytics via Apache Pinot {% endembed %}
Pinot originated at LinkedIn which currently has one of the largest deployment powering more than 50+ user facing applications such as Viewed My Profile, Talent Analytics, Company Analytics, Ad Analytics and many more. At LinkedIn, Pinot also serves as the backend to visualize and monitor 10,000+ business metrics.
With Pinot's growing popularity, several companies are now using it in production to power a variety of analytics use cases. A detailed list of companies using Pinot can be found here.
- A column-oriented database with various compression schemes such as Run Length, Fixed Bit Length
- Pluggable indexing technologies - Sorted Index, Bitmap Index, Inverted Index, StarTree Index, Bloom Filter, Range Index, Text Search Index(Lucence/FST), Json Index, Geospatial Index
- Ability to optimize query/execution plan based on query and segment metadata
- Near real-time ingestion from streams such as Kafka, Kinesis and batch ingestion from sources such as Hadoop, S3, Azure, GCS
- SQL-like language that supports selection, aggregation, filtering, group by, order by, distinct queries on data
- Support for multi-valued fields
- Horizontally scalable and fault-tolerant
Pinot is designed to execute OLAP queries with low latency. It is suited in contexts where fast analytics, such as aggregations, are needed on immutable data, possibly, with real-time data ingestion.
User facing Analytics Products
Pinot is the perfect choice for user-facing analytics products. Pinot was originally built at LinkedIn to power rich interactive real-time analytic applications such as Who Viewed Profile, Company Analytics, Talent Insights, and many more. UberEats Restaurant Manager is another example of a customer-facing Analytics App. At LinkedIn, Pinot powers 50+ user-facing products, ingesting millions of events per second and serving 100k+ queries per second at millisecond latency.
Real-time Dashboard for Business Metrics
Pinot can be also be used to perform typical analytical operations such as slice and dice, drill down, roll up, and pivot on large scale multi-dimensional data. For instance, at LinkedIn, Pinot powers dashboards for thousands of business metrics. One can connect various BI tools such as Superset, Tableau, or PowerBI to visualize data in Pinot.
Instructions to connect Pinot with Superset can be found here.
Anomaly Detection
In addition to visualizing data in Pinot, one can run Machine Learning Algorithms to detect Anomalies in the data stored in Pinot. See ThirdEye for more information on how to use Pinot for Anomaly Detection and Root Cause Analysis.
While Pinot doesn't match the typical mold of a database product, it is best understood based on your role as either an analyst, data scientist, or application developer.
Enterprise business intelligence
For analysts and data scientists, Pinot is best viewed as a highly-scalable data platform for business intelligence. In this view, Pinot converges big data platforms with the traditional role of a data warehouse, making it a suitable replacement for analysis and reporting.
Enterprise application development
For application developers, Pinot is best viewed as an immutable aggregate store that sources events from streaming data sources, such as Kafka, and makes it available for a query using SQL.
As is the case with a microservice architecture, data encapsulation ends up requiring each application to provide its own data store, as opposed to sharing one OLTP database for reads and writes. In this case, it becomes difficult to query the complete view of a domain because it becomes stored in many different databases. This is costly in terms of performance since it requires joins across multiple microservices that expose their data over HTTP under a REST API. To prevent this, Pinot can be used to aggregate all of the data across a microservice architecture into one easily queryable view of the domain.
Pinot tenants prevent any possibility of sharing ownership of database tables across microservice teams. Developers can create their own query models of data from multiple systems of record depending on their use case and needs. As with all aggregate stores, query models are eventually consistent and immutable.
Our documentation is structured to let you quickly get to the content you need and is organized around the different concerns of users, operators, and developers. If you're new to Pinot and want to learn things by example, please take a look at our getting started section.
{% content-ref url="basics/getting-started/" %} getting-started {% endcontent-ref %}
To start importing data into Pinot, check out our guides on batch import and stream ingestion based on our plugin architecture.
{% content-ref url="basics/data-import/" %} data-import {% endcontent-ref %}
Pinot works very well for querying time series data with many dimensions and metrics over a vast unbounded space of records that scales linearly on a per-node basis. Filters and aggregations are both easy and fast.
SELECT sum(clicks), sum(impressions) FROM AdAnalyticsTable
WHERE
((daysSinceEpoch >= 17849 AND daysSinceEpoch <= 17856)) AND
accountId IN (123456789)
GROUP BY
daysSinceEpoch TOP 100Pinot supports SQL for querying read-only data. Learn more about querying Pinot for time series data in our PQL (Pinot Query Language) guide.
Pinot may be deployed to and operated on a cloud provider or a local or virtual machine. You may get started either with a bare-metal installation or a Kubernetes one (either locally or in the cloud). To get immediately started with Pinot, check out these quick start guides for bootstrapping a Pinot cluster using Docker or Kubernetes.
{% content-ref url="basics/getting-started/running-pinot-locally.md" %} running-pinot-locally.md {% endcontent-ref %}
{% content-ref url="basics/getting-started/running-pinot-in-docker.md" %} running-pinot-in-docker.md {% endcontent-ref %}
{% content-ref url="basics/getting-started/kubernetes-quickstart.md" %} kubernetes-quickstart.md {% endcontent-ref %}
{% content-ref url="./" %} . {% endcontent-ref %}
For a high-level overview that explains how Pinot works, please take a look at our basic concepts section.
{% content-ref url="basics/concepts.md" %} concepts.md {% endcontent-ref %}
To understand the distributed systems architecture that explains Pinot's operating model, please take a look at our basic architecture section.
{% content-ref url="basics/architecture.md" %} architecture.md {% endcontent-ref %}