News 🔥
- [2024/2] Lookahead Decoding Paper now available on arXiv. Sampling and FlashAttention are supported. Advanced features for better token prediction are updated.
We introduce lookahead decoding:
- A parallel decoding algorithm to accelerate LLM inference.
- Without the need for a draft model or a data store.
- Linearly decreases #decoding steps relative to log(FLOPs) used per decoding step.
Below is a demo of lookahead decoding accelerating LLaMa-2-Chat 7B generation:

Lookahead decoding is motivated by Jacobi decoding, which views autoregressive decoding as solving nonlinear systems and decodes all future tokens simultaneously using a fixed-point iteration method. Below is a Jacobi decoding example.
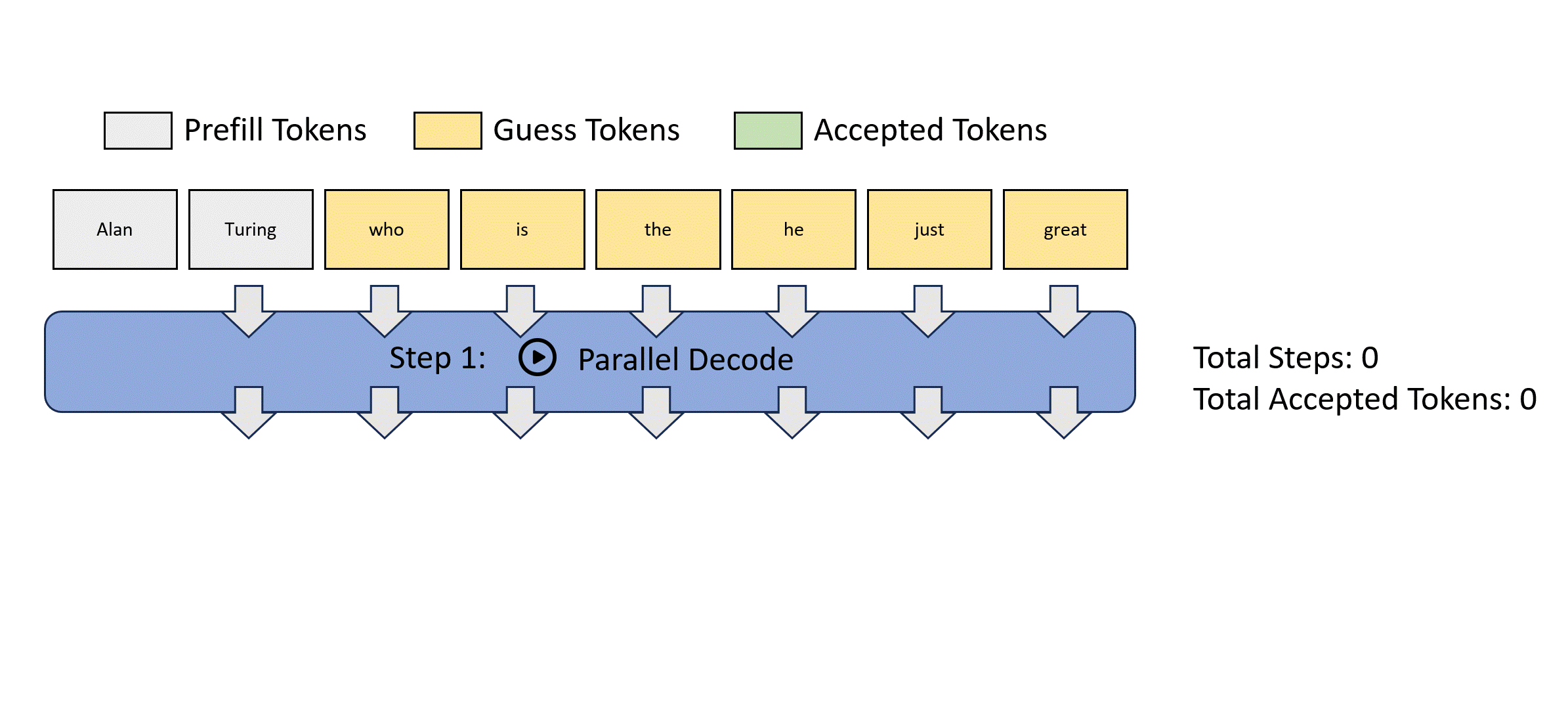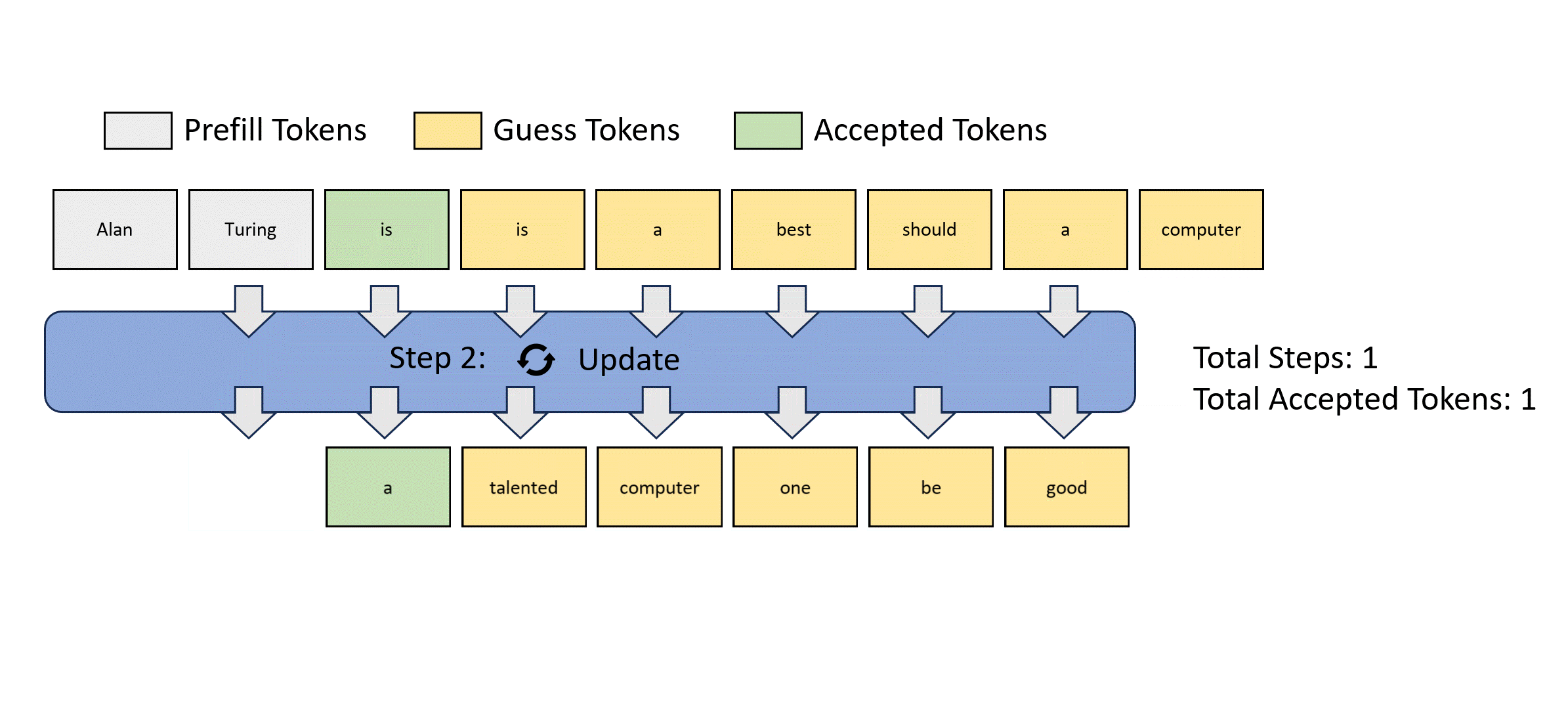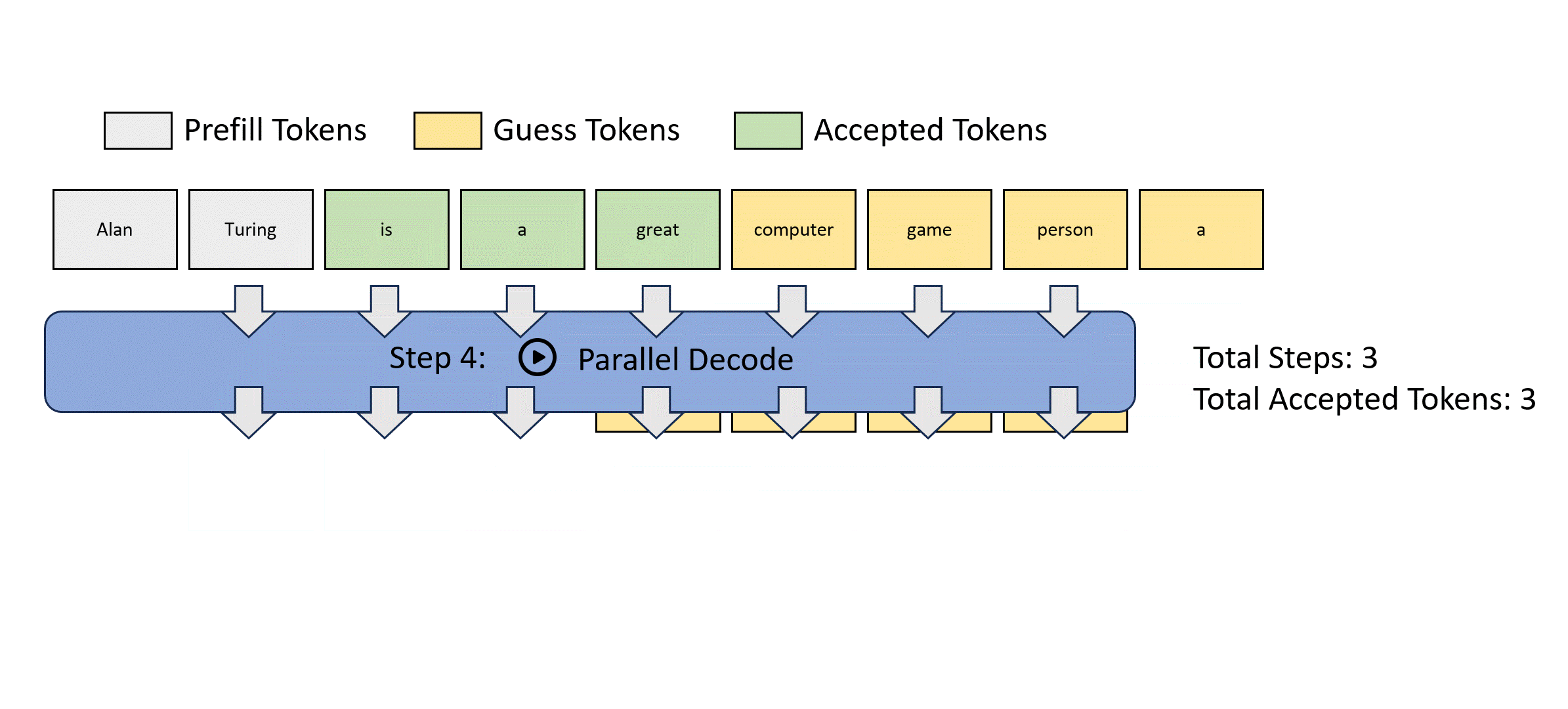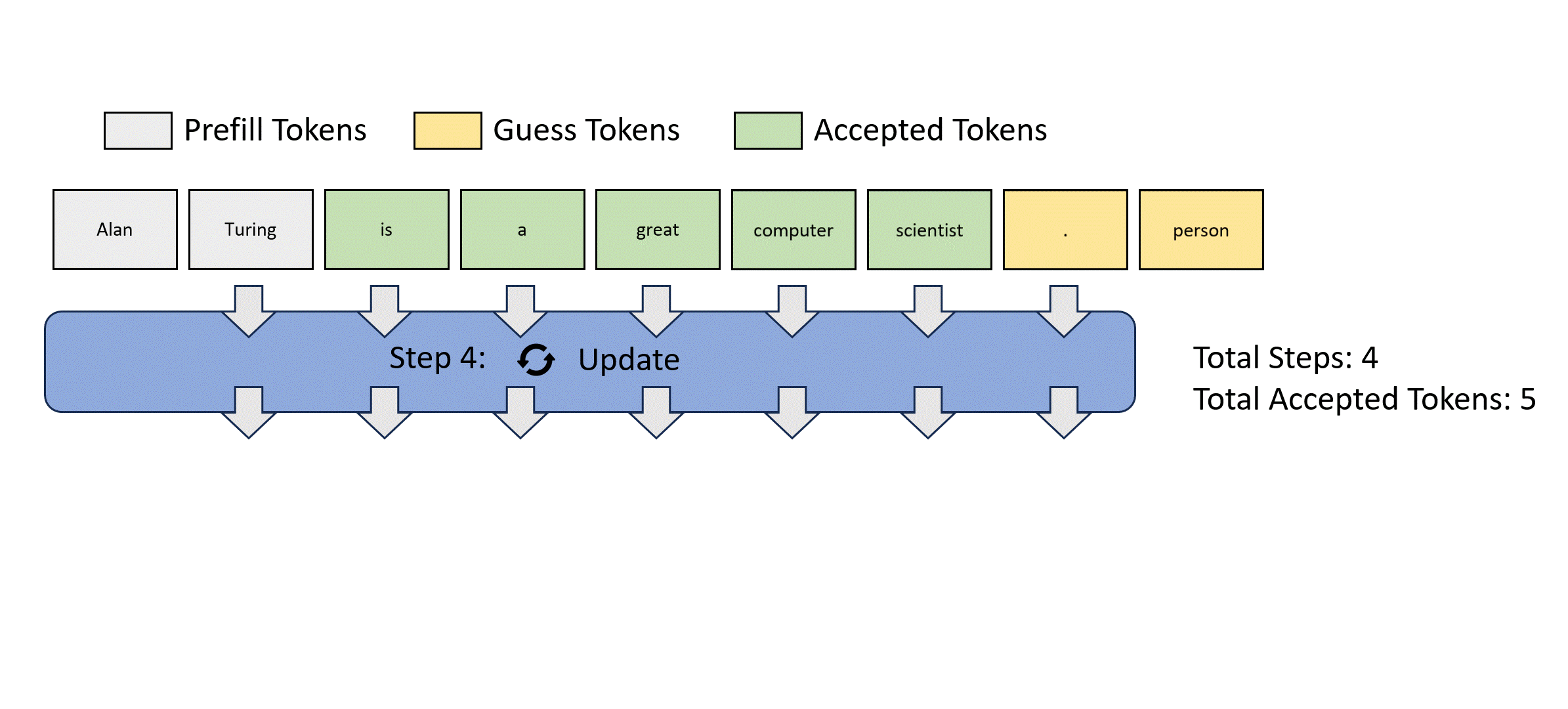
However, Jacobi decoding can barely see wall-clock speedup in real-world LLM applications.
Lookahead decoding takes advantage of Jacobi decoding's ability by collecting and caching n-grams generated from Jacobi iteration trajectories.
The following gif shows the process of collecting 2 grams via Jacobi decoding and verifying them to accelerate decoding.
To enhance the efficiency of this process, each lookahead decoding step is divided into two parallel branches: the lookahead branch and the verification branch. The lookahead branch maintains a fixed-sized, 2D window to generate n-grams from the Jacobi iteration trajectory. Simultaneously, the verification branch selects and verifies promising n-gram candidates.
The lookahead branch aims to generate new N-grams. The branch operates with a two-dimensional window defined by two parameters:
- Window size W: How far ahead we look in future token positions to conduct parallel decoding.
- N-gram size N: How many steps we look back into the past Jacobi iteration trajectory to retrieve n-grams.
In the verification branch, we identify n-grams whose first token matches the last input token. This is determined via simple string match. Once identified, these n-grams are appended to the current input and subjected to verification via an LLM forward pass through them.
We implement these branches in one attention mask to further utilize GPU's parallel computing power.

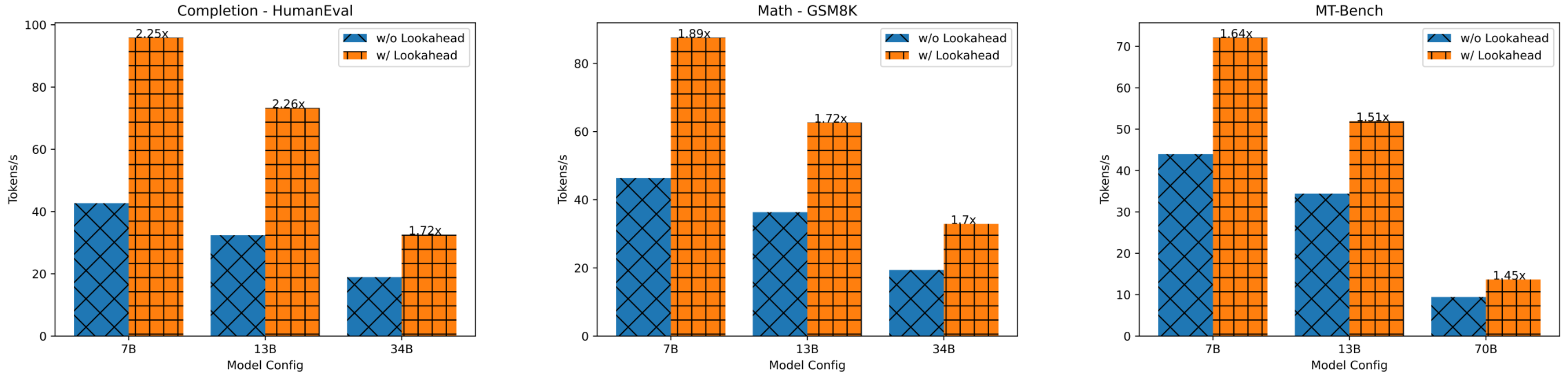
Our study shows lookahead decoding substantially reduces latency, ranging from 1.5x to 2.3x on different datasets on a single GPU. See the figure below.
pip install ladegit clone https://github.com/hao-ai-lab/LookaheadDecoding.git
cd LookaheadDecoding
pip install -r requirements.txt
pip install -e .You can run the minimal example to see the speedup that Lookahead decoding brings.
python minimal.py #no Lookahead decoding
USE_LADE=1 LOAD_LADE=1 python minimal.py #use Lookahead decoding, 1.6x speedupYou can also enjoy chatting with your own chatbots with Lookahead decoding.
USE_LADE=1 python applications/chatbot.py --model_path meta-llama/Llama-2-7b-chat-hf --debug --chat #chat, with lookahead
USE_LADE=0 python applications/chatbot.py --model_path meta-llama/Llama-2-7b-chat-hf --debug --chat #chat, without lookahead
USE_LADE=1 python applications/chatbot.py --model_path meta-llama/Llama-2-7b-chat-hf --debug #no chat, with lookahead
USE_LADE=0 python applications/chatbot.py --model_path meta-llama/Llama-2-7b-chat-hf --debug #no chat, without lookaheadYou can import and use Lookahead decoding in your own code in three LoCs. You also need to set USE_LADE=1 in command line or set os.environ["USE_LADE"]="1" in Python script. Note that Lookahead decoding only support LLaMA yet.
import lade
lade.augment_all()
lade.config_lade(LEVEL=5, WINDOW_SIZE=7, GUESS_SET_SIZE=7, DEBUG=0)
#LEVEL, WINDOW_SIZE and GUESS_SET_SIZE are three important configurations (N,W,G) in lookahead decoding, please refer to our blog!
#You can obtain a better performance by tuning LEVEL/WINDOW_SIZE/GUESS_SET_SIZE on your own device.Then you can speedup the decoding process. Here is an example using greedy search:
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype=torch.float16, device_map=torch_device)
model_inputs = tokenizer(input_text, return_tensors='pt').to(torch_device)
greedy_output = model.generate(**model_inputs, max_new_tokens=1024) #speedup obtained
Here is an example using sampling:
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype=torch.float16, device_map=torch_device)
model_inputs = tokenizer(input_text, return_tensors='pt').to(torch_device)
sample_output = model.generate(**model_inputs, max_new_tokens=1024, temperature=0.7) #speedup obtained
Install the original FlashAttention
pip install flash-attn==2.3.3 #original FlashAttentionTwo ways to install FlashAttention specialized for Lookahead Decoding
- Download a pre-built package on https://github.com/Viol2000/flash-attention-lookahead/releases/tag/v2.3.3 and install (fast, recommended). For example, I have cuda==11.8, python==3.9 and torch==2.1, I should do the following:
wget https://github.com/Viol2000/flash-attention-lookahead/releases/download/v2.3.3/flash_attn_lade-2.3.3+cu118torch2.1cxx11abiFALSE-cp39-cp39-linux_x86_64.whl
pip install flash_attn_lade-2.3.3+cu118torch2.1cxx11abiFALSE-cp39-cp39-linux_x86_64.whl- Install from the source (slow, not recommended)
git clone https://github.com/Viol2000/flash-attention-lookahead.git
cd flash-attention-lookahead && python setup.py installHere is an example script to run the models with FlashAttention:
python minimal-flash.py #no Lookahead decoding, w/ FlashAttention
USE_LADE=1 LOAD_LADE=1 python minimal-flash.py #use Lookahead decoding, w/ FlashAttention, 20% speedup than w/o FlashAttentionIn your own code, you need to set USE_FLASH=True when calling config_lade, and set attn_implementation="flash_attention_2" when calling AutoModelForCausalLM.from_pretrained.
import lade
lade.augment_all()
lade.config_lade(LEVEL=5, WINDOW_SIZE=7, GUESS_SET_SIZE=7, USE_FLASH=True, DEBUG=0)
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype=torch.float16, device_map=torch_device, attn_implementation="flash_attention_2")
model_inputs = tokenizer(input_text, return_tensors='pt').to(torch_device)
greedy_output = model.generate(**model_inputs, max_new_tokens=1024) #speedup obtainedWe will integrate FlashAttention directly into this repo for simple installation and usage.
@misc{fu2024break,
title={Break the Sequential Dependency of LLM Inference Using Lookahead Decoding},
author={Yichao Fu and Peter Bailis and Ion Stoica and Hao Zhang},
year={2024},
eprint={2402.02057},
archivePrefix={arXiv},
primaryClass={cs.LG}
}The core implementation is in decoding.py. Lookahead decoding requires an adaptation for each specific model. An example is in models/llama.py.