An inference runtime offering GPU-class performance on CPUs and APIs to integrate ML into your application
DeepSparse is a CPU inference runtime that takes advantage of sparsity within neural networks to execute inference quickly. Coupled with SparseML, an open-source optimization library, DeepSparse enables you to achieve GPU-class performance on commodity hardware.

For details of training sparse models for deployment with DeepSparse, check out SparseML.
Neural Magic is bringing performant deep learning inference to ARM CPUs! In our recent product release, we launched alpha support for DeepSparse on AWS Graviton and Ampere. We are working towards a general release across ARM server, embedded, and mobile platforms in 2023.
If you would like to trial the alpha or want early access to the general release, sign up for the waitlist.
DeepSparse is available in two editions:
- DeepSparse Community is free for evaluation, research, and non-production use with our DeepSparse Community License.
- DeepSparse Enterprise requires a trial license or can be fully licensed for production, commercial applications.
DeepSparse Community is available as a container image hosted on GitHub container registry.
docker pull ghcr.io/neuralmagic/deepsparse:1.4.2
docker tag ghcr.io/neuralmagic/deepsparse:1.4.2 deepsparse-docker
docker run -it deepsparse-docker- Check out the Docker page for more details.
DeepSparse Community is also available via PyPI. We recommend using a virtual enviornment.
pip install deepsparse- Check out the Installation page for optional dependencies.
Supported Hardware for DeepSparse
DeepSparse is tested on Python versions 3.8-3.10, ONNX versions 1.5.0-1.12.0, ONNX opset version 11 or higher, and manylinux compliant systems. Please note that DeepSparse is only supported natively on Linux. For those using Mac or Windows, running Linux in a Docker or virtual machine is necessary to use DeepSparse.
DeepSparse includes three deployment APIs:
- Engine is the lowest-level API. With Engine, you pass tensors and receive the raw logits.
- Pipeline wraps the Engine with pre- and post-processing. With Pipeline, you pass raw data and receive the prediction.
- Server wraps Pipelines with a REST API using FastAPI. With Server, you send raw data over HTTP and receive the prediction.
The example below downloads a 90% pruned-quantized BERT model for sentiment analysis in ONNX format from SparseZoo, compiles the model, and runs inference on randomly generated input.
from deepsparse import Engine
from deepsparse.utils import generate_random_inputs, model_to_path
# download onnx, compile
zoo_stub = "zoo:nlp/sentiment_analysis/obert-base/pytorch/huggingface/sst2/pruned90_quant-none"
batch_size = 1
compiled_model = Engine(model=zoo_stub, batch_size=batch_size)
# run inference (input is raw numpy tensors, output is raw scores)
inputs = generate_random_inputs(model_to_path(zoo_stub), batch_size)
output = compiled_model(inputs)
print(output)
# > [array([[-0.3380675 , 0.09602544]], dtype=float32)] << raw scoresPipeline is the default API for interacting with DeepSparse. Similar to Hugging Face Pipelines, DeepSparse Pipelines wrap Engine with pre- and post-processing (as well as other utilities), enabling you to send raw data to DeepSparse and receive the post-processed prediction.
The example below downloads a 90% pruned-quantized BERT model for sentiment analysis in ONNX format from SparseZoo, sets up a pipeline, and runs inference on sample data.
from deepsparse import Pipeline
# download onnx, set up pipeline
zoo_stub = "zoo:nlp/sentiment_analysis/obert-base/pytorch/huggingface/sst2/pruned90_quant-none"
sentiment_analysis_pipeline = Pipeline.create(
task="sentiment-analysis", # name of the task
model_path=zoo_stub, # zoo stub or path to local onnx file
)
# run inference (input is a sentence, output is the prediction)
prediction = sentiment_analysis_pipeline("I love using DeepSparse Pipelines")
print(prediction)
# > labels=['positive'] scores=[0.9954759478569031]- Check out the Use Cases Page for more details on supported tasks.
- Check out the Pipelines User Guide for more usage details.
Server wraps Pipelines with REST APIs, enabling you to stand up model serving endpoint running DeepSparse. This enables you to send raw data to DeepSparse over HTTP and receive the post-processed predictions.
DeepSparse Server is launched from the command line, configured via arguments or a server configuration file. The following downloads a 90% pruned-quantized BERT model for sentiment analysis in ONNX format from SparseZoo and launches a sentiment analysis endpoint:
deepsparse.server \
--task sentiment-analysis \
--model_path zoo:nlp/sentiment_analysis/obert-base/pytorch/huggingface/sst2/pruned90_quant-noneSending a request:
import requests
url = "http://localhost:5543/predict" # Server's port default to 5543
obj = {"sequences": "Snorlax loves my Tesla!"}
response = requests.post(url, json=obj)
print(response.text)
# {"labels":["positive"],"scores":[0.9965094327926636]}- Check out the Use Cases Page for more details on supported tasks.
- Check out the Server User Guide for more usage details.
DeepSparse accepts models in the ONNX format. ONNX models can be passed in one of two ways:
-
SparseZoo Stub: SparseZoo is an open-source repository of sparse models. The examples on this page use SparseZoo stubs to identify models and download them for deployment in DeepSparse.
-
Local ONNX File: Users can provide their own ONNX models, whether dense or sparse. For example:
wget https://github.com/onnx/models/raw/main/vision/classification/mobilenet/model/mobilenetv2-7.onnxfrom deepsparse import Engine
from deepsparse.utils import generate_random_inputs
onnx_filepath = "mobilenetv2-7.onnx"
batch_size = 16
# Generate random sample input
inputs = generate_random_inputs(onnx_filepath, batch_size)
# Compile and run
compiled_model = Engine(model=onnx_filepath, batch_size=batch_size)
outputs = compiled_model(inputs)
print(outputs[0].shape)
# (16, 1000) << batch, num_classesDeepSparse offers different inference scenarios based on your use case.
Single-stream scheduling: the latency/synchronous scenario, requests execute serially. [default]
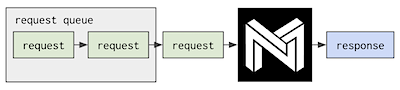
It's highly optimized for minimum per-request latency, using all of the system's resources provided to it on every request it gets.
Multi-stream scheduling: the throughput/asynchronous scenario, requests execute in parallel.

The most common use cases for the multi-stream scheduler are where parallelism is low with respect to core count, and where requests need to be made asynchronously without time to batch them.
- Check out the Scheduler User Guide for more details.
DeepSparse Community Edition gathers basic usage telemetry including, but not limited to, Invocations, Package, Version, and IP Address for Product Usage Analytics purposes. Review Neural Magic's Products Privacy Policy for further details on how we process this data.
To disable Product Usage Analytics, run the command:
export NM_DISABLE_ANALYTICS=TrueConfirm that telemetry is shut off through info logs streamed with engine invocation by looking for the phrase "Skipping Neural Magic's latest package version check." For additional assistance, reach out through the DeepSparse GitHub Issue queue.
- DeepSparse | stable
- DeepSparse-Nightly | nightly (dev)
- GitHub | releases
Contribute with code, examples, integrations, and documentation as well as bug reports and feature requests! Learn how here.
For user help or questions about DeepSparse, sign up or log in to our Neural Magic Community Slack. We are growing the community member by member and happy to see you there. Bugs, feature requests, or additional questions can also be posted to our GitHub Issue Queue. You can get the latest news, webinar and event invites, research papers, and other ML Performance tidbits by subscribing to the Neural Magic community.
For more general questions about Neural Magic, complete this form.
DeepSparse Community is licensed under the Neural Magic DeepSparse Community License. Some source code, example files, and scripts included in the deepsparse GitHub repository or directory are licensed under the Apache License Version 2.0 as noted.
DeepSparse Enterprise requires a Trial License or can be fully licensed for production, commercial applications.
Find this project useful in your research or other communications? Please consider citing:
@InProceedings{
pmlr-v119-kurtz20a,
title = {Inducing and Exploiting Activation Sparsity for Fast Inference on Deep Neural Networks},
author = {Kurtz, Mark and Kopinsky, Justin and Gelashvili, Rati and Matveev, Alexander and Carr, John and Goin, Michael and Leiserson, William and Moore, Sage and Nell, Bill and Shavit, Nir and Alistarh, Dan},
booktitle = {Proceedings of the 37th International Conference on Machine Learning},
pages = {5533--5543},
year = {2020},
editor = {Hal Daumé III and Aarti Singh},
volume = {119},
series = {Proceedings of Machine Learning Research},
address = {Virtual},
month = {13--18 Jul},
publisher = {PMLR},
pdf = {http://proceedings.mlr.press/v119/kurtz20a/kurtz20a.pdf},
url = {http://proceedings.mlr.press/v119/kurtz20a.html}
}
@article{DBLP:journals/corr/abs-2111-13445,
author = {Eugenia Iofinova and
Alexandra Peste and
Mark Kurtz and
Dan Alistarh},
title = {How Well Do Sparse Imagenet Models Transfer?},
journal = {CoRR},
volume = {abs/2111.13445},
year = {2021},
url = {https://arxiv.org/abs/2111.13445},
eprinttype = {arXiv},
eprint = {2111.13445},
timestamp = {Wed, 01 Dec 2021 15:16:43 +0100},
biburl = {https://dblp.org/rec/journals/corr/abs-2111-13445.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}