![]()
🎉 🎉 🎉 LightSeq supports fast training for models in the Transformer family now, please check out here for details.
LightSeq is a high performance training and inference library for sequence processing and generation implemented in CUDA. It enables highly efficient computation of modern NLP models such as BERT, GPT, Transformer, etc. It is therefore best useful for Machine Translation, Text Generation, Dialog, Language Modelling, Sentiment analysis, and other related tasks with sequence data.
The library is built on top of CUDA official library(cuBLAS, Thrust, CUB) and custom kernel functions which are specially fused and optimized for Transformer model family. In addition to model components, the library also provide easy-to deploy model management and serving backend based on TensorRT Inference Server(referred to as TRTIS in the later discussion). With LightSeq, one can easily develop modified Transformer architecture with little additional code.
- Comprehensive sequence modeling support, including Bert, GPT, Transformer and their VAE variants.
- Various search methods, such as beam search, diverse beam search, topp/topk sampling.
- Out-of-the-box rich middlewares for model service based on TRTIS, such as dynamic batch, multi-model on single GPU.
- Lightening fast training speed for supported models.
- Lightening fast inference performance compared with Deeplearning framework and other inference libraries.
The following is a support matrix of LightSeq compared with TurboTransformers and FasterTransformer.

Here are the experimental results on neural machine translation and text generation. The models of these two tasks are Transformer-base, but use beam search and sampling search methods respectively. We choose Tensorflow and FasterTransformer as a comparison. The implementation from tensor2tensor was used as the benchmark of Tensorflow.
More results is available here.
-
Neural machine translation
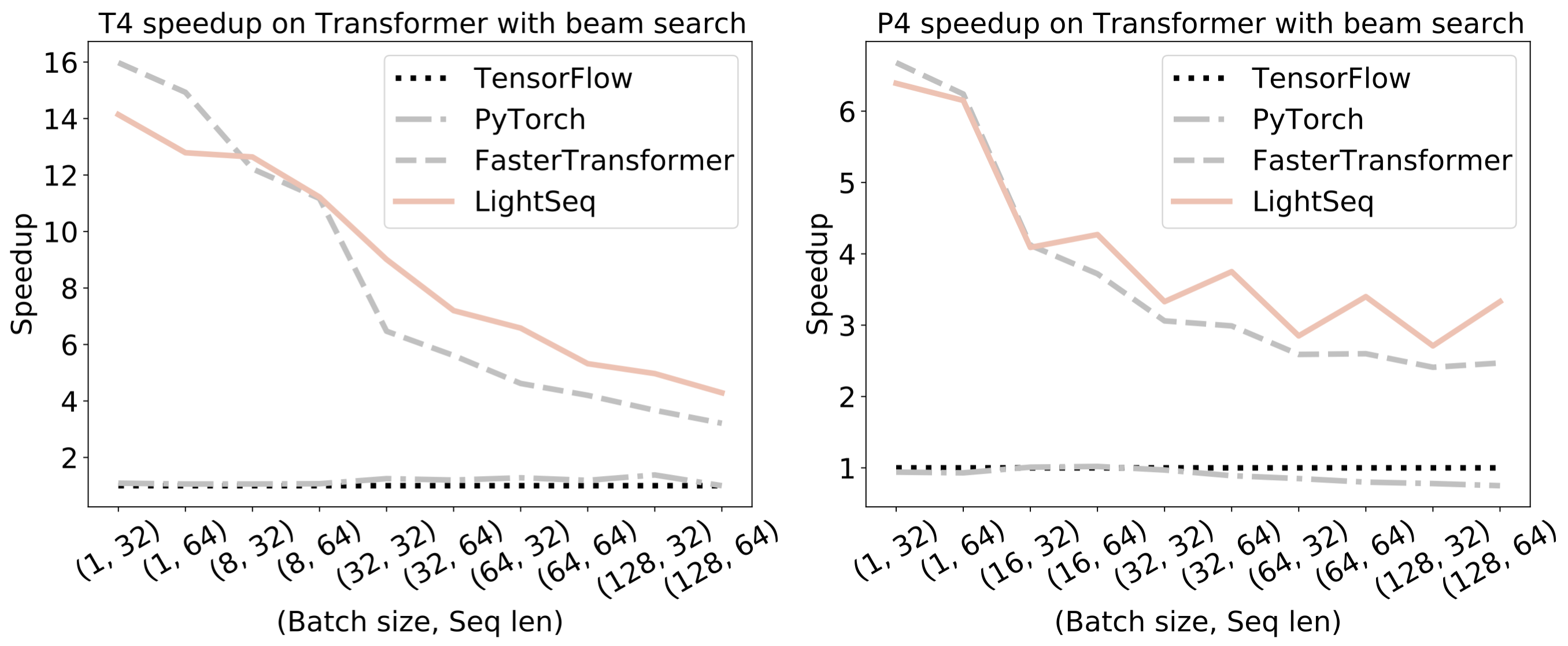
-
Text generation
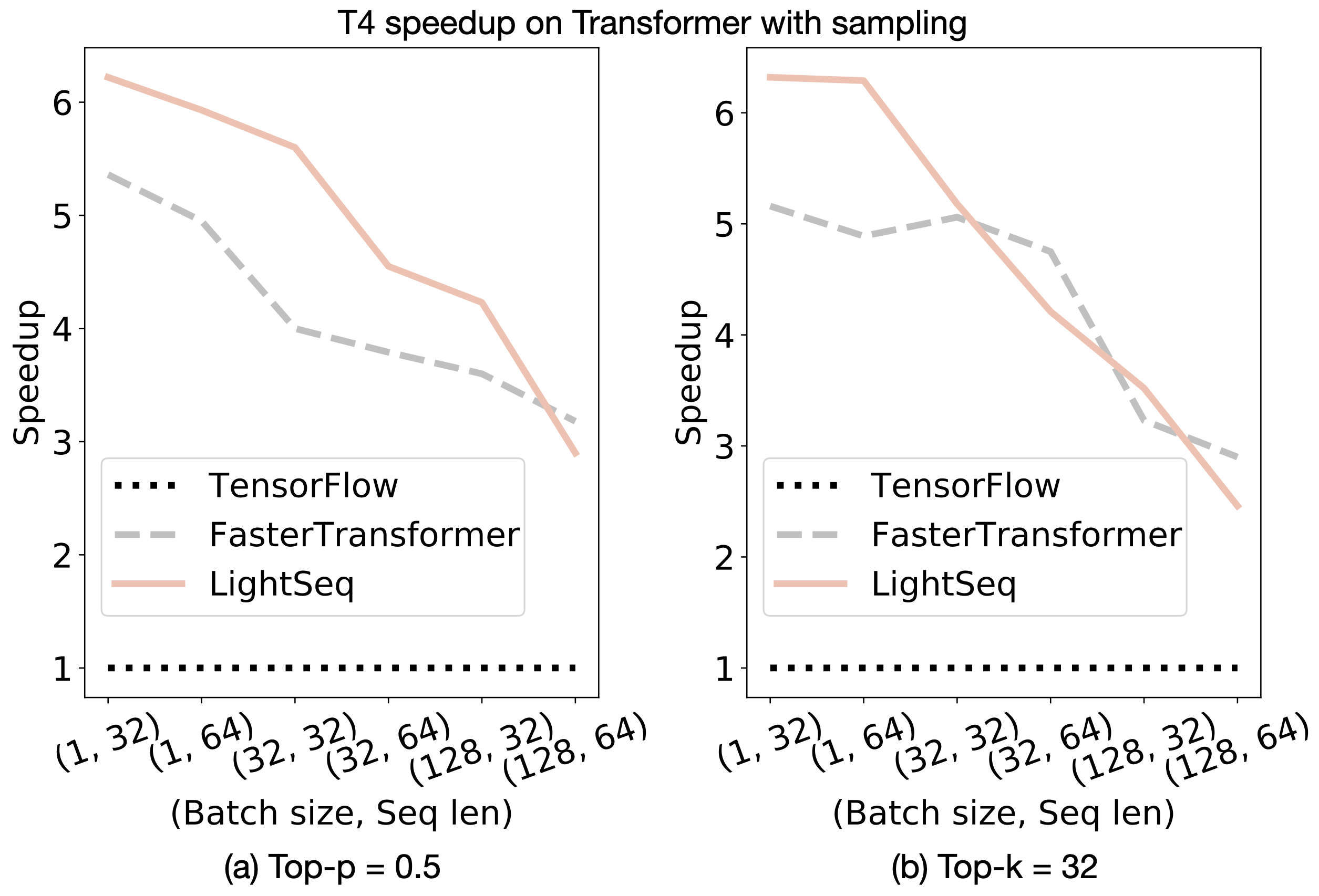
You can experience lightning fast training by running following commands, Firstly install these requirements.
pip install lightseq fairseq sacremosesThen you can train a translation task on wmt14 en2de dataset by running the following script
sh lightseq/training/examples/fairseq/ls_fairseq_wmt14en2de.shTo compare lightseq with fairseq, delete the arguments with ls_prefix to using the original fairseq implementation
We provide an end2end bart-base example to see how fast Lightseq is compared to HuggingFace. First you should install these requirements.
pip install torch tensorflow transformers lightseq
cd example/pythonthen you can check the performance by simply running following commands. hf_bart_export.py is used to transform pytorch weights to LightSeq protobuffer.
python hf_bart_export.py
python ls_bart.pyon our Tesla V100 we can get following output, 10x speedup have been obtained from running LightSeq rather than HuggingFace.
=========lightseq=========
lightseq generating...
lightseq time: 0.03398153930902481s
lightseq results:
I love that girl, but she does not love me.
She is so beautiful that I can not help glance at her.
Nothing's gonna change my love for you.
Drop everything now. Meet me in the pouring rain. Kiss me on the sidewalk.
=========huggingface=========
huggingface generating...
huggingface time: 0.3320543058216572s
huggingface results:
I love that girl, but she does not love me.
She is so beautiful that I can not help glance at her.
Nothing's gonna change my love for you.
Drop everything now. Meet me in the pouring rain. Kiss me on the sidewalk.
LightSeq installation from pypi only supports python 3.6 to 3.8 on Linux for now. Consider compiling from source if you have other environments.
We provide python api to call lightseq, all you need is to install lightseq with pip, and make sure you have GPU driver not older than 418.40.04.
And check these files proto/*.proto to prepare your model weights. We provide an example weight file for you to test.
curl -OL https://github.com/bytedance/lightseq/releases/download/v0.0.1/transformer_weight.tar.gz
tar -zxvf transformer_weight.tar.gzFinally you can run lightseq in only a few lines!
import lightseq.inference as lsi
import numpy as np
test_input = np.array([[5001, 2, 36, 5002]])
transformer = lsi.Transformer("transformer.pb", 32) # 32 is max batch size, it will decide GPU memory occupancy.
result = transformer.infer(test_input)Python api doesn't support GPT for now, and we will get it ready as soon as possible.
- Install Docker and nvidia-docker.
- GPU driver version >= 410.48
- Login to the NGC registry.
To avoid problems caused by inconsistent environments, you can use the pre-built TRTIS container from NVIDIA GPU Cloud (NGC). To start the given container, you need to install nvidia-docker and make your GPU driver version >= 410.48
docker pull nvcr.io/nvidia/tensorrtserver:19.05-py3
#
docker run --gpus '"device=0"' -it --rm -p8000:8000 -p8001:8001 -p8002:8002 -v
/${current}/${path}:/quick_start nvcr.io/nvidia/tensorrtserver:19.05-py3 /bin/bash
# inside container
cd /quick_startTo quickly deploy your model that supported by LightSeq currently, you can download the pre-built libraries from the GitHub release page corresponding to the release version you are interested in. In each release version, we will upload binary executable example and dynamic link library of models which is a custom backend of TRTIS.
wget https://github.com/bytedance/lightseq/releases/download/${VERSION}/${VERSION}_libs.tar.gz
tar -zxvf ${VERSION}_libs.tar.gzTo run local inference demo, you need to prepare model weights saved in custom proto defined by LightSeq and input token ids. We provide a GPT-LM model and its corresponding input token ids:
wget https://github.com/bytedance/lightseq/releases/download/v0.0.1/v0.0.1_gptlm.pkg.tar.gz
tar -zxvf v0.0.1_gptlm.pkg.tar.gz
# fp32 example
./{VERSION}_libs/gptlm_example.fp32 ./v0.0.1_gptlm.pkg/gpt.pb ./v0.0.1_gptlm.pkg/test_case
# fp16 example
./{VERSION}_libs/gptlm_example.fp16 ./v0.0.1_gptlm.pkg/gpt.pb ./v0.0.1_gptlm.pkg/test_caseTo run the end-to-end model server based on TRTIS, you need to prepare a custom backend model repository like this:
models/
<model-name>/
config.pbtxt # configuration
xxx # model weights
1/
libyyy.so # custom dynamic link libraryWith the pre-built libraries and example weights mentioned above, you can easily run a server:
mkdir -p ./model_zoo/gptlm/1
wget https://github.com/bytedance/lightseq/releases/download/v0.0.1/v0.0.1_gptlm.config.pbtxt
mv v0.0.1_gptlm.config.pbtxt model_zoo/gptlm/config.pbtxt
cp ./v0.0.1_gptlm.pkg/gpt.pb model_zoo/gptlm/gpt.pb
cp ./{VERSION}_libs/libgptlm.so.fp32 model_zoo/gptlm/1/libgptlm.so
# or fp16 server
# cp ./{VERSION}_libs/libgptlm.so.fp16 model_zoo/gptlm/1/libgptlm.so
export MODEL_ZOO="/quick_start/model_zoo"
trtserver --model-store=${MODEL_ZOO}After starting server, Invoking the TRTIS client will get the inference result.
In order to serve your own model, you need to export model trained from deeplearning framework(E.g. TenforFlow, PyTorch) to custom model proto defined by LightSeq. Furthermore, you may need to build from source code if you want to modify the model architectures or serve a new model not supported by LightSeq currently.
LightSeq does not support CPU inference for now and its compilation relies heavily on TRTIS, we will try to solve these problems in future. Furthermore, the following will be the focus of our future work:
- Support more model architectures and decoding search algorithms.
- Int8 inference.
- Device deployment.
If you use LightSeq in your research, please cite the following paper.
@InProceedings{wang2021lightseq,
title = "{L}ight{S}eq: A High Performance Inference Library for Transformers",
author = "Wang, Xiaohui and Xiong, Ying and Wei, Yang and Wang, Mingxuan and Li, Lei",
booktitle = "Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies: Industry Papers (NAACL-HLT)",
month = jun,
year = "2021",
publisher = "Association for Computational Linguistics",
pages = "113--120",
}Any questions or suggestions, please feel free to contact us at wangxiaohui.neo@bytedance.com, xiongying.taka@bytedance.com, weiyang.god@bytedance.com, wangmingxuan.89@bytedance.com, lileilab@bytedance.com