
![]()
ArXiv | Docs | Slideflow Studio | Cite
Slideflow is a deep learning library for digital pathology that provides a unified API for building, training, and testing models using Tensorflow or PyTorch.
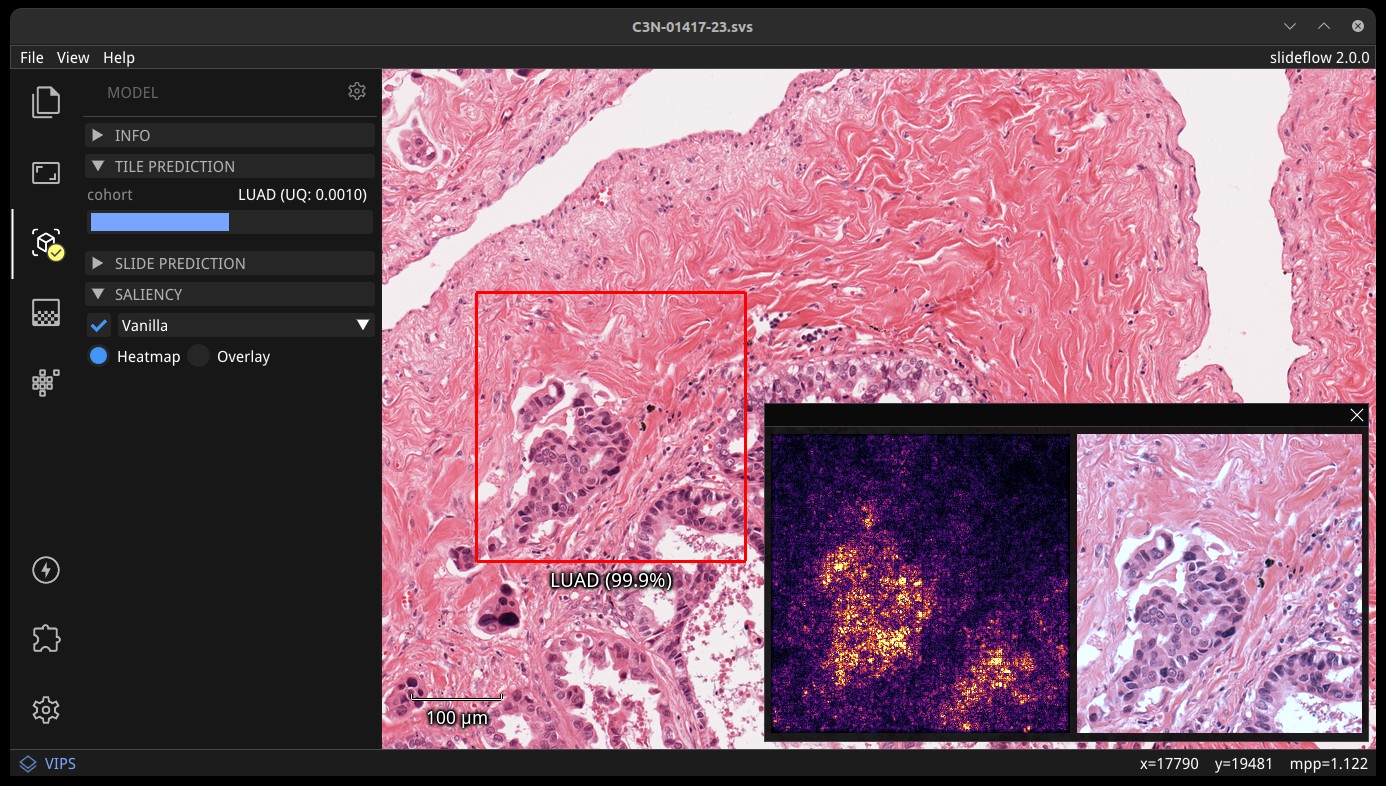
Slideflow includes tools for whole-slide image processing, customizable deep learning model training with dozens of supported architectures, multi-instance learning, self-supervised learning, cell segmentation, explainability tools (including heatmaps, mosaic maps, GANs, and saliency maps), analysis of layer activations, uncertainty quantification, and more.
A variety of fast, optimized whole-slide image processing tools are included, including background filtering, blur/artifact detection, stain normalization/augmentation, and efficient storage in *.tfrecords format. Model training is easy and highly configurable, with an straightforward API for training custom architectures. Slideflow can be used as an image processing backend for external training loops, serving an optimized tf.data.Dataset or torch.utils.data.DataLoader to read and process slide images and perform real-time stain normalization.
Full documentation with example tutorials can be found at slideflow.dev.
- Python >= 3.7 (<3.10 if using cuCIM)
- Tensorflow 2.5-2.11 or PyTorch 1.9-2.0
- GAN and MIL functions require PyTorch <1.13
- Libvips >= 8.9 (alternative slide reader, adds support for *.scn, *.mrxs, *.ndpi, *.vms, and *.vmu files).
- Linear solver (for preserved-site cross-validation)
- CPLEX 20.1.0 with Python API
- or Pyomo with Bonmin solver
Slideflow can be installed with PyPI, as a Docker container, or run from source.
pip3 install --upgrade setuptools pip wheel
pip3 install slideflow[cucim] cupy-cuda11x
The cupy package name depends on the installed CUDA version; see here for installation instructions. cupy is not required if using Libvips.
Alternatively, pre-configured docker images are available with OpenSlide/Libvips and the latest version of either Tensorflow and PyTorch. To install with the Tensorflow backend:
docker pull jamesdolezal/slideflow:latest-tf
docker run -it --gpus all jamesdolezal/slideflow:latest-tf
To install with the PyTorch backend:
docker pull jamesdolezal/slideflow:latest-torch
docker run -it --shm-size=2g --gpus all jamesdolezal/slideflow:latest-torch
To run from source, clone this repository, install the conda development environment, and build a wheel:
git clone https://github.com/jamesdolezal/slideflow
cd slideflow
conda env create -f environment.yml
conda activate slideflow
python setup.py bdist_wheel
pip install dist/slideflow* cupy-cuda11x
Slideflow supports both Tensorflow and PyTorch, defaulting to Tensorflow if both are available. You can specify the backend to use with the environmental variable SF_BACKEND. For example:
export SF_BACKEND=torch
By default, Slideflow reads whole-slide images using cuCIM. Although much faster than other openslide-based frameworks, it supports fewer slide scanner formats. Slideflow also includes a Libvips backend, which adds support for *.scn, *.mrxs, *.ndpi, *.vms, and *.vmu files. You can set the active slide backend with the environmental variable SF_SLIDE_BACKEND:
export SF_SLIDE_BACKEND=libvips
Slideflow experiments are organized into Projects, which supervise storage of whole-slide images, extracted tiles, and patient-level annotations. The fastest way to get started is to use one of our preconfigured projects, which will automatically download slides from the Genomic Data Commons:
import slideflow as sf
P = sf.create_project(
root='/project/destination',
cfg=sf.project.LungAdenoSquam,
download=True
)After the slides have been downloaded and verified, you can skip to Extract tiles from slides.
Alternatively, to create a new custom project, supply the location of patient-level annotations (CSV), slides, and a destination for TFRecords to be saved:
import slideflow as sf
P = sf.create_project(
'/project/path',
annotations="/patient/annotations.csv",
slides="/slides/directory",
tfrecords="/tfrecords/directory"
)Ensure that the annotations file has a slide column for each annotation entry with the filename (without extension) of the corresponding slide.
Next, whole-slide images are segmented into smaller image tiles and saved in *.tfrecords format. Extract tiles from slides at a given magnification (width in microns size) and resolution (width in pixels) using sf.Project.extract_tiles():
P.extract_tiles(
tile_px=299, # Tile size, in pixels
tile_um=302 # Tile size, in microns
)If slides are on a network drive or a spinning HDD, tile extraction can be accelerated by buffering slides to a SSD or ramdisk:
P.extract_tiles(
...,
buffer="/mnt/ramdisk"
)Once tiles are extracted, models can be trained. Start by configuring a set of hyperparameters:
params = sf.ModelParams(
tile_px=299,
tile_um=302,
batch_size=32,
model='xception',
learning_rate=0.0001,
...
)Models can then be trained using these parameters. Models can be trained to categorical, multi-categorical, continuous, or time-series outcomes, and the training process is highly configurable. For example, to train models in cross-validation to predict the outcome 'category1' as stored in the project annotations file:
P.train(
'category1',
params=params,
save_predictions=True,
multi_gpu=True
)Slideflow includes a host of additional tools, including model evaluation and prediction, heatmaps, analysis of layer activations, mosaic maps, and more. See our full documentation for more details and tutorials.
Slideflow has been used by:
- Dolezal et al, Modern Pathology, 2020
- Rosenberg et al, Journal of Clinical Oncology [abstract], 2020
- Howard et al, Nature Communications, 2021
- Dolezal et al Nature Communications, 2022
- Storozuk et al, Modern Pathology [abstract], 2022
- Partin et al Front Med, 2022
- Dolezal et al [abstract], 2022
- Dolezal et al [arXiv], 2022
- Howard et al npj Breast Cancer, 2023
- Hieromnimon et al [bioRxiv], 2023
This code is made available under the GPLv3 License and is available for non-commercial academic purposes.
If you find our work useful for your research, or if you use parts of this code, please consider citing as follows:
Dolezal, J. M., Kochanny, S., Dyer, E., et al. Slideflow: Deep Learning for Digital Histopathology with Real-Time Whole-Slide Visualization. ArXiv [q-Bio.QM] (2023). http://arxiv.org/abs/2304.04142
@misc{dolezal2023slideflow,
title={Slideflow: Deep Learning for Digital Histopathology with Real-Time Whole-Slide Visualization},
author={James M. Dolezal and Sara Kochanny and Emma Dyer and Andrew Srisuwananukorn and Matteo Sacco and Frederick M. Howard and Anran Li and Prajval Mohan and Alexander T. Pearson},
year={2023},
eprint={2304.04142},
archivePrefix={arXiv},
primaryClass={q-bio.QM}
}