Danbooru 2018 Anime Character Recognition Dataset
This repo provides an anime character recognition dataset based on Danbooru 2018. The original Danbooru dataset provides images with tags. We processed the dataset (more details below) to generate 1M head images with corresponding character tags. About 70k characters are included in the dataset.
Methodology
We processed the original Danbooru dataset as follows:
- First only the character tags were kept by filtering according to the category of the tag.
- Because we don't have information on which face corresponds to which tag, we only kept the images that have only one character tag.
- Then we extracted head bounding boxes using this model.
- For similar reasons, we discarded the images on which multiple head boxes are detected.
This ended up with 0.97M images and 70k tags.
Data Distribution and Visualization
Out of these 1M images, the distribution of how many images each tag has is visualized as below:
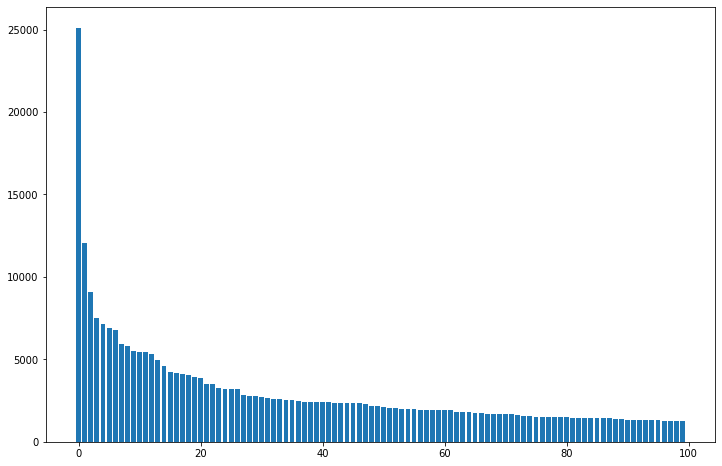
Only the 100 tags with the most images are shown here for clarify. And the top-20 tags are:
- hatsune_miku
- hakurei_reimu
- flandre_scarlet
- kirisame_marisa
- cirno
- izayoi_sakuya
- remilia_scarlet
- kochiya_sanae
- rumia
- shameimaru_aya
- patchouli_knowledge
- inubashiri_momiji
- fujiwara_no_mokou
- komeiji_koishi
- reisen_udongein_inaba
- yakumo_yukari
- alice_margatroid
- komeiji_satori
- hinanawi_tenshi
- kazami_yuuka
It is obvious that the distribution is long-tail, considering the average number of images per tag is 13.85. I'm also surprised to see how popular Touhou Project is in the Danbooru dataset. Out of the 70k tags, about 20k tags only have one single image. While they may not be very useful in character recognition, we still keep them in the dataset.
Here is a visualization of some top tags.

How to Use
The core of the database is the detected head bounding boxes and corresponding tags.
This is stored in the file faces.tsv.
Note you will have to obtain the images from the original Danbooru dataset
The tsv file has three columns.
The first column is the file name from the Danbooru dataset.
The second column is the tag id, and the third column is the head detection results.
Each detection result has five fields separated by commas, i.e. left, top, right, bottom, confidence in order.
The tag text for each id can be seen in the file tagIds.tsv.
We also have the cropped face images ready as a tarball.
Many thanks to gwern, you can now download the tarball using rsync:
rsync --verbose rsync://78.46.86.149:873/biggan/2019-07-27-grapeot-danbooru2018-animecharacterrecognition.tar ./Cite the Dataset
If you find the dataset useful, please consider citing the dataset:
- Yan Wang, "Danbooru2018 Anime Character Recognition Dataset," July 2019. https://github.com/grapeot/Danbooru2018AnimeCharacterRecognitionDataset
- Anonymous, The Danbooru Community, Gwern Branwen, & Aaron Gokaslan; “Danbooru2018: A Large-Scale Crowdsourced and Tagged Anime Illustration Dataset”, 3 January 2019. https://www.gwern.net/Danbooru2018
@misc{danboorucharacter,
author = {Yan Wang},
title = {Danbooru 2018 Anime Character Recognition Dataset},
howpublished = {\url{https://github.com/grapeot/Danbooru2018AnimeCharacterRecognitionDataset}},
url = {https://github.com/grapeot/Danbooru2018AnimeCharacterRecognitionDataset},
type = {dataset},
year = {2019},
month = {July} } @misc{danbooru2018,
author = {Anonymous, the Danbooru community, Gwern Branwen, Aaron Gokaslan},
title = {Danbooru2018: A Large-Scale Crowdsourced and Tagged Anime Illustration Dataset},
howpublished = {\url{https://www.gwern.net/Danbooru2018}},
url = {https://www.gwern.net/Danbooru2018},
type = {dataset},
year = {2019},
month = {January},
timestamp = {2019-01-02},
note = {Accessed: DATE} }Character Recognition Baseline
We also provide a baseline for character recognition based on the dataset. If using a ResNet18 without SE, and use the ArcFace loss, we are able to achieve a testing accuracy of 37.3%. The model and a related demo will be released soon.
Data Split
The split for the baseline is also provided in case evaluation and comparison of the algorithms are of interest.
trainSplit.tsvcontains the image ids for training.valSplit.tsvcontains the image ids for validation.testSplit.tsvis the set we use to measure the final accuracy.
The total number of images are less than the entire dataset because we removed images that did not reach the confidence bar (0.85). Note at the current stage the test set has not been verified by humans.
Open problems
- The test set for character recognition is to be verified by humans.
- Still need to do more work on face alignment.